Stai integrando l’AI nel modo sbagliato nel tuo ecosistema Java (se non stai usando Spring AI)




Negli ultimi vent’anni, il mondo Java Enterprise non ha mai seguito mode.
Ha attraversato trasformazioni architetturali obbligate.
| Evoluzione | Perché è diventata indispensabile |
|---|---|
| SOA | Per smettere di avere sistemi monolitici ingestibili |
| REST | Per rendere l’integrazione finalmente standard |
| Microservizi | Per isolare responsabilità e rilasciare in modo indipendente |
| Cloud Native | Per smettere di progettare attorno ai server |
| Kubernetes | Per automatizzare ciò che prima richiedeva team interi |
Ogni volta, non era entusiasmo tecnologico, era sopravvivenza architetturale.
A un certo punto, non adottare quel cambiamento diventava il vero rischio.
Oggi sta succedendo di nuovo.
Ma per la prima volta, il cambiamento non riguarda l’infrastruttura, riguarda la natura stessa della logica applicativa.
Si chiama Generative AI.
Per la prima volta nella storia del software enterprise, abbiamo un componente che:
- comprende linguaggio naturale
- genera contenuti
- usa conoscenza aziendale
- prende decisioni contestuali
- può interagire con i sistemi esistenti
Questo non è un miglioramento tecnologico, è un cambio di paradigma nel modo in cui il software può funzionare.
Ed è qui che vedo nascere l’errore più grande.
“Facciamo una chiamata HTTP a OpenAI.”
È lo stesso errore visto con SOAP, REST, microservizi.
Si prova a usare la tecnologia nuova senza cambiare il modo in cui si progetta l’architettura.
Il risultato è sempre lo stesso:
codice fragile, ingestibile, non testabile, non osservabile, non portabile.
La domanda corretta non è:
“Come uso un LLM?”
La domanda corretta è:
Come integro un LLM dentro un’architettura Java Enterprise Spring Boot based mantenendo gli stessi standard di qualità che ho sempre preteso dal mio software?
È esattamente il motivo per cui esiste Spring AI.

Il problema reale che gli sviluppatori Spring stanno incontrando
Chi lavora con Spring Boot sa costruire sistemi eccellenti:
- API pulite
- microservizi testabili
- codice osservabile
- architetture mantenibili
Poi arriva un LLM, e improvvisamente compaiono domande nuove, per cui l’esperienza precedente non basta:
- Dove vivono i prompt nel codice?
- Come gestisco il contesto conversazionale?
- Come evito le hallucinations?
- Come testo qualcosa che per natura non è deterministico?
- Come integro documenti aziendali privati?
- Come fornisco dati real-time al modello?
- Come monitoro costi e token?
- Come rendo tutto questo production-grade?
Senza un framework, l’AI entra nel progetto come un corpo estraneo.
Con Spring AI, diventa un componente architetturale di prima classe.
Integrare un LLM in Spring AI non significa usare SDK strani o fare chiamate HTTP manuali.
Significa dichiarare un bean Spring.
@Bean
public ChatClient chatClient(ChatClient.Builder builder) {
return builder.build();
}I Message Roles: parlare correttamente con un LLM
Un LLM non ragiona su una stringa, ma su messaggi con ruoli:
- System → comportamento del modello
- User → richiesta
- Assistant → risposta
- Function/Tool → interazione con il codice
Spring AI modella questi ruoli in modo esplicito e li rende portabili tra provider diversi. Stesso codice. LLM diversi. Nessuna riscrittura.
Questo è design architetturale, non integrazione tecnica.
Questo non è teoria. È parte diretta dell’API.
String response = chatClient.prompt()
.system("You are a professional HR assistant")
.user("Explain the leave policy")
.call()
.content();Memoria: risolvere la natura stateless degli LLM
Gli LLM sono, per natura, completamente stateless.
Ogni chiamata è indipendente dalla precedente. Per il modello, ogni richiesta è una conversazione nuova.
Eppure quando usiamo ChatGPT abbiamo la sensazione che “ricordi”.
La realtà è molto meno magica e molto più architetturale:
qualcuno salva lo storico della conversazione, lo persiste, e lo reinvia al modello ad ogni richiesta come parte del contesto.
Questo meccanismo, apparentemente banale, è in realtà uno dei punti più critici quando si porta un LLM dentro un sistema enterprise.
Perché a questo punto iniziano le domande vere:
- Dove salvo la conversazione?
- La salvo in memoria? In database? In cache distribuita?
- Come la associo a un utente, a una sessione, a un tenant?
- Quanto storico reinvio al modello? Tutto? Solo una parte?
- Come evito di sprecare token inutilmente?
- Come gestisco più conversazioni contemporaneamente?
- Come rendo tutto questo testabile e manutenibile?
Senza un framework, la gestione del contesto conversazionale diventa rapidamente codice fragile e sparso nell’applicazione.
Spring AI introduce il concetto di Chat Memory come parte esplicita dell’architettura.
La memoria non è più un dettaglio implementativo, ma un componente configurabile del sistema:
- persistenza dello storico
- gestione per utente/sessione
- integrazione con storage esterni
- controllo di quanto contesto viene reinviato al modello
Questo è ciò che rende possibile costruire:
- assistant aziendali veri
- chatbot multi-turn seri
- sistemi conversazionali contestuali
- interazioni intelligenti che evolvono nel tempo
Senza Chat Memory, stai costruendo una demo, con Chat Memory, stai costruendo un sistema conversazionale enterprise.
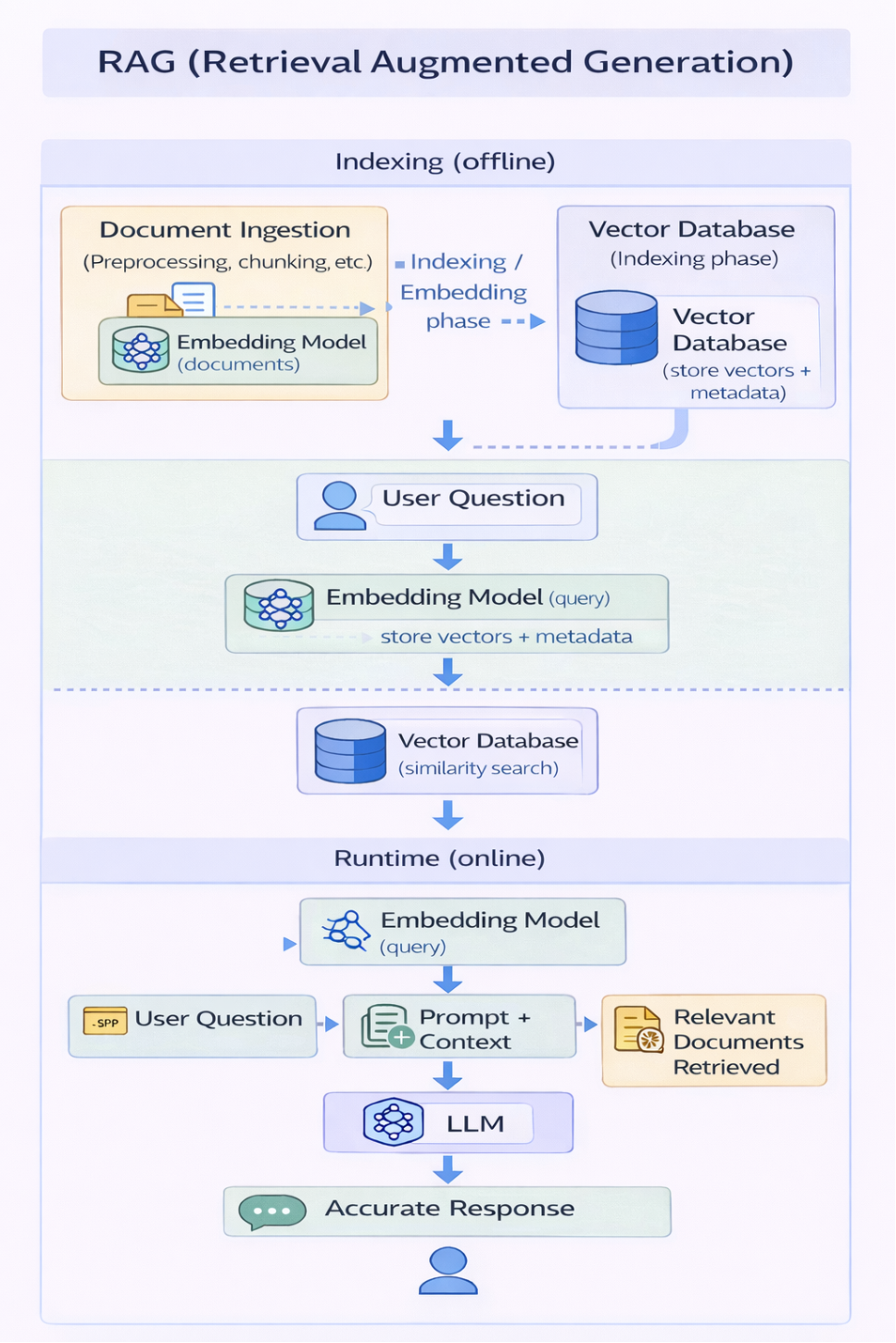
RAG: far conoscere al modello i documenti aziendali
Retrieval Augmented Generation è il punto in cui la Generative AI smette di essere generica e diventa realmente utile in un contesto enterprise.
Gli LLM, per quanto potenti, non conoscono nulla della tua azienda.
Non conoscono:
- PDF interni
- policy
- manuali operativi
- documentazione proprietaria
- knowledge base interna
- contratti, procedure, regolamenti
Senza RAG, il modello risponde usando solo la conoscenza pubblica con cui è stato addestrato.
E questo, in un contesto aziendale, è insufficiente.
RAG introduce un’architettura completamente nuova attorno al modello.
I documenti aziendali non vengono “passati al modello”.
Vengono:
- analizzati e suddivisi in chunk
- trasformati in embedding vettoriali tramite un embedding model
- salvati in un vector database insieme ai metadati
Questa è la fase di indexing.
Poi, a runtime, quando arriva una domanda:
- la domanda viene a sua volta trasformata in embedding
- il vector database esegue una similarity search
- vengono recuperati solo i documenti realmente rilevanti
- questi documenti vengono inseriti nel prompt come contesto
Il modello, a quel punto, non risponde più “di suo”.
Risponde usando la conoscenza aziendale che gli hai fornito dinamicamente.
Questo ha effetti enormi:
- riduce drasticamente le hallucinations
- rende le risposte domain-specific
- ottimizza l’uso dei token (solo il contesto rilevante)
- permette al modello di “conoscere” l’azienda senza riaddestrarlo
Ed è qui che la Generative AI diventa davvero enterprise-ready.
Perché non stai più chiedendo al modello di essere intelligente.
Stai costruendo un sistema che gli fornisce, nel momento giusto, la conoscenza giusta.
Tool Calling: quando il modello inizia ad agire
Fino a questo punto, l’LLM è stato usato per generare risposte migliori.
Con il Tool Calling cambia completamente il paradigma.
Il modello non viene più usato solo per produrre testo. Viene usato per decidere quando deve essere eseguita della logica applicativa reale.
È qui che l’AI smette di essere “chat” e diventa automazione intelligente integrata nel sistema.
Un tool, in Spring AI, è semplicemente un metodo Java esposto al modello.
Ma il punto architetturale è molto più profondo.
Il flusso reale non è:
LLM → Tool
Il flusso reale è:
Agent (la tua applicazione Spring) ⇄ LLM
Agent → Tool
Il modello suggerisce una function call.
È l’applicazione che mantiene il controllo ed esegue il metodo.
Questo permette al modello di:
- interrogare database real-time
- chiamare API interne
- creare ticket
- inviare email
- leggere dati aggiornati
- interagire con qualsiasi sistema già esistente
L’AI non è più un sistema esterno. Diventa un “decisore” che attiva la tua logica di business.
@Tool
public String getCurrentWeather(String city) {
return weatherService.fetch(city);
}
chatClient.prompt("What's the weather in Rome?")
.call()
.content();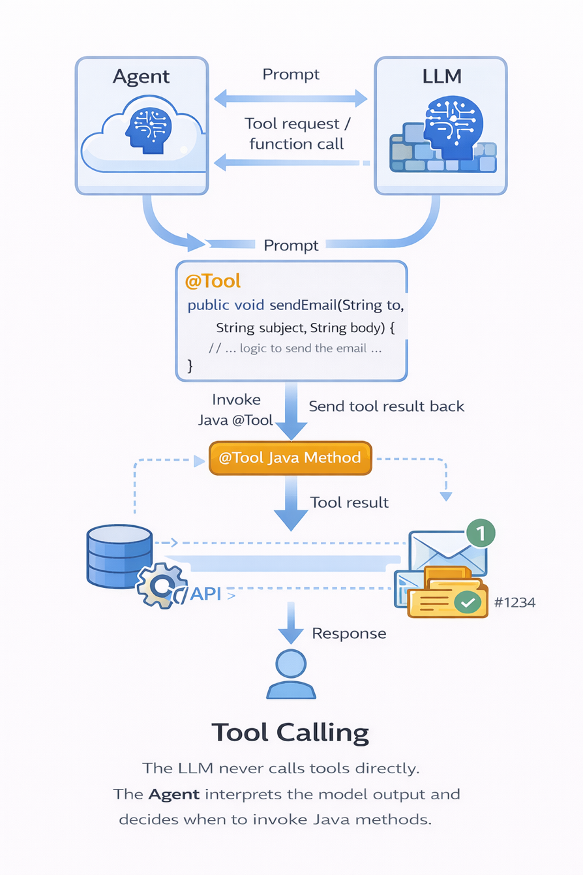
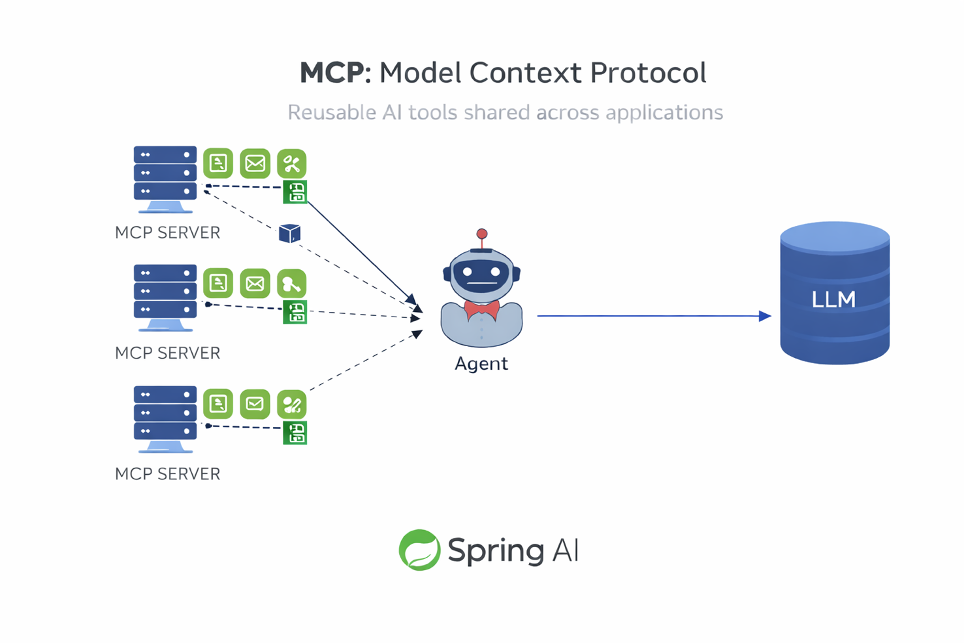
MCP: rendere i tool riusabili tra applicazioni
Il passo successivo è naturale.
Se i tool sono metodi Java, e se questi tool iniziano a rappresentare capacità di business reali…
perché dovrebbero vivere solo dentro una singola applicazione?
È qui che entra in gioco il Model Context Protocol (MCP).
MCP non è “un server centrale”. È un protocollo.
Con MCP, i microservizi diventano server MCP:
- espongono tool
- descrivono le loro capacità
- rendono queste capacità invocabili dagli agenti
Esattamente come è successo anni fa con le REST API.
MCP è per i tool AI ciò che REST è stato per l’integrazione tra servizi.
Spring AI supporta MCP nativamente, permettendo di:
- trasformare microservizi Spring Boot in MCP Server
- esporre tool riusabili
- costruire orchestrazioni agentiche distribuite
- mantenere tutto nello stesso ecosistema di deployment, sicurezza e governance
Il risultato è potente:
l’AI non introduce un nuovo mondo parallelo
si innesta direttamente nell’architettura a microservizi esistente
Testing: il punto che quasi tutti ignorano
Qui tocchi uno dei punti più sottovalutati in assoluto.
Con un LLM:
stesso input ≠ stesso output
I test tradizionali basati su assertEquals semplicemente non funzionano.
Ma questo non significa che l’AI non sia testabile.
Significa che va testata in modo diverso.
Spring AI introduce il concetto di Evaluator:
un LLM che valuta semanticamente l’output di un altro LLM.
Non stai più verificando:
“la risposta è identica”
Stai verificando:
- la risposta è corretta semanticamente?
- rispetta le regole di dominio?
- risponde alla domanda?
- contiene errori concettuali?
EvaluationResult result = evaluator.evaluate(prompt, response);
assertTrue(result.isPass());Questo è un cambio di mentalità enorme per chi fa software enterprise.
Non stai rinunciando al testing...stai evolvendo il testing.

Observability: quando l’AI diventa finalmente operabile (e governabile)
C’è un aspetto che quasi tutte le aziende scoprono troppo tardi quando iniziano a sperimentare con gli LLM:
finché l’AI è una chiamata HTTP, è invisibile.
Non sai:
- quanti token stai consumando
- quanto costa realmente ogni richiesta
- dove sta la latenza (LLM? RAG? tool?)
- quando il modello fallisce
- quanto impatta sulle performance del servizio
- quanto scala sotto carico
È una scatola nera dentro il tuo sistema.
E una scatola nera, in un contesto enterprise, è inaccettabile.
Spring AI cambia radicalmente questo scenario perché porta l’AI dentro l’ecosistema di Spring Boot Actuator.
Significa che l’AI espone metriche come qualsiasi altro componente del tuo sistema.
Metriche su:
- utilizzo dei token per richiesta
- latenza delle chiamate LLM
- performance della pipeline RAG
- utilizzo dei tool
- errori e fallback
- throughput sotto carico
Tutto questo è automaticamente integrabile con:
- Prometheus
- Grafana
- tracing distribuito
- sistemi di monitoring già esistenti
Ma c’è un aspetto ancora più delicato.
Quando usi un LLM come SaaS (OpenAI, Anthropic, Gemini, Mistral), ogni token è denaro.
Senza osservabilità, non hai controllo sui costi.
Non sai:
- quale servizio consuma di più
- quale endpoint genera più spesa
- quale prompt è inefficiente
- quale RAG sta iniettando troppo contesto
- dove ottimizzare per ridurre il consumo
Con Spring AI, i costi diventano misurabili come qualsiasi altra metrica operativa.
L’AI entra finalmente nel dominio della governance.
Smette di essere “qualcosa di magico” e diventa:
qualcosa che puoi monitorare, misurare, ottimizzare e governare.
E questo, in un’architettura enterprise, vale tanto quanto RAG e Tool Calling.
Perché non basta che l’AI funzioni.
Deve essere operabile.
Deve essere controllabile.
Deve essere sostenibile nel tempo.

Il punto architetturale che cambia tutto
Senza Spring AI, l’AI in un progetto Java resta: un’integrazione tecnica.
Una chiamata HTTP verso un modello esterno. Codice speciale, isolato, difficile da testare, monitorare e governare. Qualcosa che vive ai margini dell’architettura.
Con Spring AI, l’AI diventa invece:
un componente architetturale di prima classe.
E questo cambia radicalmente il modo in cui progetti, testi, monitori e fai evolvere il sistema.
Perché il vero valore della Generative AI, in un contesto enterprise, non è nell’AI in sé.
È nella sua integrazione profonda dentro l’ecosistema esistente.
Nel momento in cui l’AI:
- segue le stesse regole di design dei tuoi microservizi
- entra nella tua pipeline CI/CD
- è osservabile tramite Actuator, Prometheus, Grafana
- scala con Kubernetes come qualsiasi altro servizio
- è testabile con gli stessi standard di qualità
- è governabile con le stesse pratiche architetturali
smette di essere una “novità tecnologica”.
Diventa parte del sistema, diventa qualcosa di controllabile, prevedibile, operabile, diventa enterprise.
E allora la domanda diventa quasi naturale.
Se il tuo stack è Java Enterprise, se il tuo ecosistema è già basato su Spring Boot, se da anni usi Spring come “linguaggio architetturale” per integrare database, code, REST, sicurezza, cloud…
perché dovresti integrare l’AI con una chiave diversa?
Ogni volta che hai introdotto qualcosa di nuovo — REST, messaging, cloud, Kubernetes — lo hai fatto passando dalla stessa porta:
Spring.
Spring è sempre stato il modo con cui hai reso nuove tecnologie parte del tuo sistema, senza romperlo.
Spring AI è esattamente questo.
È la stessa chiave che usi da anni per aprire una nuova stanza dell’architettura.
Solo che questa volta, dentro quella stanza, c’è l’intelligenza.
I limiti di Spring AI (e quando serve qualcosa di più)
È importante essere molto chiari su un punto.
Spring AI non nasce per essere un framework di orchestrazione agentica complessa.
Nasce per risolvere un problema molto preciso:
integrare la Generative AI dentro applicazioni Spring Boot in modo architetturalmente corretto.
E in questo, è eccellente.
Spring AI è perfetto quando:
- vuoi dare “intelligenza” a un microservizio
- vuoi integrare RAG con i tuoi documenti
- vuoi esporre tool Java al modello
- vuoi costruire assistant e chatbot enterprise
- vuoi mantenere testabilità, osservabilità, governance
- vuoi che l’AI segua le stesse regole del tuo ecosistema Spring
In questi scenari, Spring AI è probabilmente la scelta migliore oggi nel mondo Java.
Ma quando il problema cambia natura, anche lo strumento deve cambiare.
Quando inizi a progettare:
- workflow agentici complessi
- catene decisionali dinamiche tra più LLM e più tool
- loop di ragionamento iterativi
- orchestrazioni non lineari
- grafi di esecuzione che cambiano a runtime
- sistemi in cui l’AI non è più “dentro un servizio”, ma diventa essa stessa il motore del flusso applicativo
Spring AI inizia a mostrare i suoi limiti.
Perché il suo modello è volutamente lineare e dichiarativo, molto simile a ciò che fa LangChain nel mondo Python:
prompt → modello → tool → risultato
È perfetto per l’integrazione applicativa.
Diventa meno naturale per la costruzione di sistemi agentici complessi.
È qui che strumenti come LangChain4j (l’equivalente Java di LangChain) o approcci ispirati a LangGraph (https://docs.langchain4j.dev/) iniziano ad avere valore.
Questi framework non sono pensati per integrare l’AI in un’applicazione.
Sono pensati per costruire applicazioni attorno all’AI.
La differenza è sottile ma fondamentale.
| Spring AI | LangChain4j / approccio tipo LangGraph |
|---|---|
| AI dentro il microservizio | Il microservizio diventa un nodo del grafo agentico |
| Flusso lineare prompt → tool → risposta | Flussi non lineari, grafi, loop, decisioni dinamiche |
| Integrazione architetturale | Orchestrazione agentica |
| Perfetto per RAG, tool, assistant | Perfetto per agent complessi e workflow evoluti |
Non è una sostituzione.
È un possibile passo successivo quando l’architettura evolve.
Molte architetture mature iniziano così:
- Spring AI per integrare l’AI nei servizi esistenti
- MCP per rendere i tool riusabili
- Un layer superiore (LangChain4j / logica agentica) che orchestra questi MCP Server in workflow più complessi
A quel punto, Spring AI non viene abbandonato.
Diventa la base su cui costruire qualcosa di ancora più sofisticato.
Il messaggio finale
Spring AI è lo strumento giusto quando devi portare l’AI dentro il tuo ecosistema Java.
Se, nel tempo, sarà l’AI a guidare il flusso dell’applicazione, allora potresti aver bisogno di strumenti pensati per orchestrazioni più complesse.
Ed è un’evoluzione naturale, non un errore di scelta iniziale.