KEDA: autoscaling event-driven per Kubernetes




Introduzione: perché KEDA è rilevante oggi
Negli ultimi anni Kubernetes ha standardizzato l’autoscaling tramite Horizontal Pod Autoscaler (HPA), basato principalmente su CPU e memoria. Questo approccio funziona bene per workload sincroni e CPU-bound, ma mostra limiti evidenti nelle architetture event-driven: consumer di code, stream processor, job asincroni, integrazioni con sistemi esterni.
In questi scenari il vero segnale di carico non è l’utilizzo di CPU, ma il backlog di lavoro: messaggi in coda, lag Kafka, eventi in attesa, metriche applicative. È qui che entra in gioco KEDA: un componente Kubernetes-native che abilita autoscaling guidato da eventi reali, incluso lo scaling to zero, impossibile con HPA puro.
Questo articolo è pensato per DevOps, Platform Engineer e SRE che vogliono capire a fondo KEDA e implementarlo correttamente in produzione, evitando errori comuni e comprendendo i trade-off architetturali.
Cos’è KEDA e cosa non è
KEDA (Kubernetes Event-Driven Autoscaling) è un operatore Kubernetes che estende HPA fornendo metriche esterne derivate da sistemi di eventi.
È importante chiarire subito alcuni punti:
- KEDA non sostituisce HPA → lo estende.
- KEDA non esegue workload → decide quando e quanto scalare.
- KEDA non è un event source → osserva event source esistenti.
Il valore chiave di KEDA è la capacità di:
- scalare da 0 a N pod,
- basarsi su event source reali (RabbitMQ, Kafka, Prometheus, cron, ecc.),
- integrarsi in modo nativo con l’API Kubernetes.
KEDA e workload GenAI: un’anticipazione sul perché è rilevante per i LLM su Kubernetes
Il valore di KEDA emerge in modo ancora più evidente quando si osservano i workload di nuova generazione, in particolare quelli legati alla Generative AI e ai Large Language Model (LLM).
Come evidenziato nella letteratura recente sul deployment di sistemi GenAI su Kubernetes, questi carichi presentano pattern fortemente irregolari: lunghi periodi di inattività possono essere seguiti da burst improvvisi di richieste di inferenza ad alto costo computazionale.
In questi scenari, metriche tradizionali come CPU o memoria non rappresentano il lavoro reale in modo tempestivo né affidabile.
Per i servizi LLM, il vero segnale di pressione non è l’utilizzo delle risorse a valle, ma la domanda in ingresso: richieste di inferenza, code di job asincroni, pipeline che orchestrano retrieval, embedding e generazione.
Scalare solo quando CPU o GPU sono già sature significa reagire troppo tardi, con impatti diretti su latenza e costi.
KEDA abilita un approccio diverso: permette di scalare i componenti di un’architettura GenAI in base agli eventi che generano lavoro, non in base al consumo delle risorse che lo eseguono. Questo rende possibile:
- anticipare i picchi di carico,
- ridurre l’over-provisioning di risorse costose (come le GPU),
- scalare a zero i servizi di inferenza quando non sono utilizzati.
In questo senso, KEDA non è solo un autoscaler per microservizi event-driven, ma un abilitatore architetturale per l’esecuzione efficiente di LLM su Kubernetes, soprattutto quando combinato con HPA e autoscaling del cluster.
Questo stesso principio — scalare sulla domanda reale anziché sull’utilizzo delle risorse — è alla base dell’architettura di KEDA e del modo in cui si integra con HPA.
Architettura di KEDA (come funziona davvero)
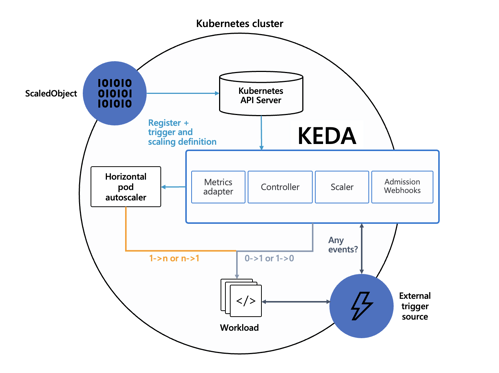
L’architettura di KEDA è intenzionalmente semplice e allineata ai pattern Kubernetes.
Componenti principali
- Scaler
- Ogni scaler è responsabile di una sorgente di eventi specifica.
- Esempi: RabbitMQ, Kafka, Azure Service Bus, Prometheus, Cron.
- Recupera una metrica semantica (es. lunghezza coda, lag).
- Controller
- Osserva le Custom Resource (ScaledObject, ScaledJob).
- Decide quando attivare/disattivare lo scaling.
- Metrics Adapter
- Espone le metriche come External Metrics API.
- Permette all’HPA di consumarle come se fossero native.
- Admission Webhook
- Valida le configurazioni (CRD).
- Previene errori strutturali a runtime.
Integrazione con HPA
Il flusso reale è il seguente:
- Definisci uno ScaledObject.
- KEDA crea automaticamente un HPA.
- KEDA gestisce:
- scaling 0 → 1
- scaling 1 → 0
- HPA gestisce:
- scaling 1 → N
Questo design evita di reinventare l’autoscaling e mantiene compatibilità totale con l’ecosistema Kubernetes.
ScaledObject e ScaledJob: scegliere lo strumento giusto
ScaledObject
Usalo quando:
- il workload è long-running,
- scala un Deployment o StatefulSet,
- vuoi consumatori sempre pronti quando arrivano eventi.
Caratteristiche:
- supporta scaling to zero,
- replica count dinamico,
- perfetto per microservizi e consumer.
ScaledJob
Usalo quando:
- ogni evento è un’unità di lavoro indipendente,
- vuoi Job Kubernetes reali,
- il pod deve terminare dopo l’elaborazione.
Caratteristiche:
- 1 evento → 1 Job,
- ideale per batch, ETL, task asincroni,
- pulizia automatica dei job completati.
Trade-off chiave
ScaledJob offre isolamento perfetto ma aumenta l’overhead di scheduling. ScaledObject è più efficiente per flussi continui.
Installazione di KEDA
Metodo consigliato: Helm
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
kubectl create namespace keda
helm install keda kedacore/keda --namespace kedaPerché Helm in produzione
- versioning controllato,
- upgrade e rollback semplici,
- gestione pulita delle CRD.
Alternativa: manifest YAML
Utile per test rapidi o ambienti estremamente controllati:
kubectl apply -f https://github.com/kedacore/keda/releases/download/v2.18.2/keda-2.18.2.yaml
Anatomy di uno ScaledObject (capirlo riga per riga)
Parametri fondamentali
| CAMPO | PERCHÉ È IMPORTANTE |
|---|---|
| scaleTargetRef | Collega KEDA al workload |
| pollingInterval | Frequenza di lettura eventi |
| cooldownPeriod | Stabilità dello scaling |
| minReplicaCount | Consente lo scale a zero |
| maxReplicaCount | Protezione da runaway scaling |
| idleReplicaCount | Numero di repliche “idle” (se vuoi non scendere a zero) |
Sezione advanced
Qui si governa il comportamento fine dello scaling.
- restoreToOriginalReplicaCount
- true: ritorna al valore del Deployment
- false: usa i limiti dello ScaledObject
- horizontalPodAutoscalerConfig.behavior
- evita oscillazioni aggressive,
- consente scale-up immediato e scale-down controllato.
In produzione è fortemente consigliato configurare behavior.
Caso reale: autoscaling RabbitMQ consumer
Obiettivo
- Consumer Java su Kubernetes
- RabbitMQ come event source
- Scaling automatico 0 → N → 0
Logica di scaling
KEDA calcola:
desiredReplicas = ceil(queueLength / targetValue)
Esempio:
- 100 messaggi
- target = 5
- → 20 pod
Questo approccio:
- massimizza parallelismo,
- evita sovra-scaling,
- mantiene prevedibilità operativa.
Perché il cooldown è essenziale
Senza cooldownPeriod:
- continui scale-up/scale-down,
- instabilità,
- costi inutili.
Autenticazione in KEDA: un aspetto strutturale, non un dettaglio
Quando si introduce KEDA in un cluster Kubernetes, l’autoscaling smette di essere un problema puramente “interno” al cluster.
Gli scaler di KEDA, per definizione, devono parlare con sistemi esterni: broker di messaggi, database, API cloud, metriche esposte fuori dal cluster.
Questo cambia radicalmente il modello di sicurezza.
Con HPA classico:
- le metriche sono locali (CPU, memoria),
- non esistono credenziali applicative coinvolte.
Con KEDA:
- ogni scaler deve autenticarsi verso un sistema esterno,
- quelle credenziali diventano parte integrante del piano di controllo dello scaling.
Trattare l’autenticazione come un dettaglio di configurazione è uno degli errori più comuni — e più pericolosi — quando si porta KEDA in produzione.
Il principio chiave: separare scaling, workload e secrets
KEDA introduce volutamente un livello di indirezione tra:
- il workload da scalare (Deployment / Job),
- la logica di scaling (ScaledObject / ScaledJob),
- le credenziali necessarie per leggere le metriche.
Questo principio è fondamentale per tre motivi:
- Sicurezza
- Nessuna credenziale hardcoded negli YAML applicativi.
- Manutenibilità
- Cambiare password o token non richiede modifiche ai workload.
- Osservabilità e audit
- È chiaro chi accede a cosa e perché.
È qui che entrano in gioco Secret, TriggerAuthentication e authenticationRef.
Flusso reale dell’autenticazione in KEDA
A livello concettuale, il flusso è questo:
- KEDA legge lo ScaledObject
- Trova un authenticationRef
- Risolve il riferimento a un TriggerAuthentication
- Il TriggerAuthentication:
- legge uno o più Secret Kubernetes (oppure un secret esterno)
- Le credenziali vengono usate solo dallo scaler
- Il Deployment da scalare non conosce nulla di questo processo
Questo è un punto cruciale: il pod scalato non ha bisogno di conoscere le credenziali usate per scalare.
Pattern consigliato: Secret + TriggerAuthentication + ScaledObject
Questo è il pattern di riferimento per ambienti reali.
1. Secret Kubernetes
Il Secret contiene solo dati sensibili, nulla di logico:
- host
- username
- password
- connection string
- token
apiVersion: v1
kind: Secret
metadata:
name: rabbitmq-secret
type: Opaque
data:
host: <base64>
username: <base64>
password: <base64>Il Secret vive nel namespace dell’applicazione, segue RBAC e può essere ruotato senza toccare KEDA.
2. TriggerAuthentication
Il TriggerAuthentication è l’oggetto che mappa i Secret verso i parametri attesi dallo scaler.
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: rabbitmq-trigger-auth
spec:
secretTargetRef:
- parameter: host
name: rabbitmq-secret
key: host
- parameter: username
name: rabbitmq-secret
key: username
- parameter: password
name: rabbitmq-secret
key: passwordQui avviene la parte più importante:
- parameter non è arbitrario,
- deve corrispondere esattamente a ciò che lo scaler RabbitMQ si aspetta.
Questo rende l’autenticazione esplicita, tipizzata e verificabile.
3. ScaledObject con authenticationRef
Lo ScaledObject si limita a dire:
“Per questo trigger, usa quell’identità”.
triggers:
- type: rabbitmq
metadata:
queueName: queue001
mode: QueueLength
value: "5"
authenticationRef:
name: rabbitmq-trigger-authIl risultato è una separazione netta:
- ScaledObject → logica di scaling
- TriggerAuthentication → identità
- Secret → dati sensibili
Perché evitare l’autenticazione inline (se non per demo)
KEDA permette anche configurazioni più rapide, come secretKeyRef diretto nel trigger.
È utile per test e PoC, ma presenta limiti chiari:
- accoppia scaling e credenziali,
- rende difficile la rotazione,
- peggiora la leggibilità del flusso.
In ambienti condivisi o regolamentati, questo approccio non scala a livello organizzativo.
ClusterTriggerAuthentication: quando lo scaling è multi-namespace
In contesti enterprise è comune avere:
- più namespace,
- più team,
- un unico broker o servizio esterno condiviso.
Il TriggerAuthentication standard è namespace-scoped.
Per evitare duplicazioni, KEDA introduce ClusterTriggerAuthentication.
Differenza chiave:
| OGGETTO | SCOPE |
|---|---|
| TriggerAuthentication | Namespace |
| ClusterTriggerAuthentication | Cluster-wide |
Il vantaggio:
- un’unica definizione di identità,
- riutilizzabile da più ScaledObject.
Il Secret, invece, rimane nel namespace dell’applicazione, mantenendo l’isolamento dei dati sensibili.
Secret esterni: HashiCorp Vault e oltre
Per ambienti ad alta compliance (PCI, SOC2, regulated workload), KEDA può leggere segreti direttamente da sistemi esterni, come HashiCorp Vault.
In questo scenario:
- KEDA non legge Secret Kubernetes,
- interroga Vault usando un metodo di autenticazione (token, Kubernetes auth, ecc.),
- risolve dinamicamente i parametri dello scaler.
Il trade-off è chiaro:
- più sicurezza
- più complessità operativa
È una scelta architetturale, non una necessità universale.
Scaler disponibili e quando usarli
Uno dei punti di forza di KEDA è l’astrazione del concetto di evento.
Non è rilevante da dove arrivi il segnale di carico, ma quanto quel segnale rappresenti in modo affidabile il lavoro reale da svolgere.
Per questo motivo KEDA supporta un numero elevato di scaler: ciascuno è pensato per tradurre una specifica tipologia di evento o metrica in una decisione di scaling coerente.
Queue-based scaler
(RabbitMQ, AWS SQS, Azure Queue)
Sono ideali quando il backlog di messaggi rappresenta direttamente il carico del sistema.
Il numero di messaggi in coda è una misura chiara e immediata del lavoro da elaborare, rendendo questo tipo di scaler perfetto per consumer asincroni e pipeline di integrazione.
Stream-based scaler
(Kafka, EventHub, Pub/Sub)
Pensati per sistemi ad alta velocità e throughput elevato, dove il consumer lag è il vero indicatore di pressione.
In questi scenari CPU e memoria sono metriche secondarie: è il ritardo accumulato nello stream a determinare la necessità di scalare.
Metric-based scaler
(Prometheus, Datadog)
Utili quando il carico è espresso da una metrica applicativa aggregata, come il numero di richieste, il tempo di risposta o un contatore custom.
Questo approccio è particolarmente efficace quando non esiste una coda esplicita, ma il lavoro può essere rappresentato da una metrica osservabile.
Time-based scaler
(Cron)
Perfetti per carichi prevedibili o finestre operative controllate.
Consentono di scalare in base al tempo, ad esempio per aumentare la capacità in orari di punta noti o ridurla durante periodi di inattività programmata.
Database scaler
(Redis, PostgreSQL, MySQL)
Indicati quando lo stato applicativo risiede in strutture dati o tabelle.
Il numero di record in uno stato specifico (ad esempio “pending” o “queued”) diventa il segnale che guida lo scaling, mantenendo il sistema allineato al lavoro effettivo.
In KEDA non si scala sulla CPU, ma sulla verità operativa del sistema: se un segnale è misurabile e rappresenta lavoro reale, può guidare lo scaling.
Errori comuni da evitare
1. Usare KEDA come sostituto completo dell’HPA
KEDA non è un replacement dell’HPA, ma un event source che ne estende le capacità.
In molti scenari, soprattutto quelli CPU-bound o memory-bound, l’HPA resta la soluzione più stabile e prevedibile.
Best practice: usare KEDA per tradurre eventi esterni (queue, stream, topic) in metriche Kubernetes e lasciare all’HPA la responsabilità finale dello scaling. Questo approccio ibrido riduce comportamenti erratici e migliora la stabilità.
2. Impostare un polling interval troppo aggressivo
Un pollingInterval troppo basso può:
- aumentare il carico su API esterne (es. Kafka, Azure Service Bus, Prometheus),
- introdurre latenza e instabilità nello scaling,
- generare costi inutili o throttling.
Best practice: partire da valori conservativi (30–60s) e ridurli solo dopo aver osservato metriche reali di latenza e throughput. Lo scaling event-driven non deve essere iper-reattivo, ma sufficientemente tempestivo.
3. Non definire un maxReplicaCount
Lasciare lo scaling senza un limite superiore è uno degli errori più pericolosi in produzione:
- può causare over-scaling incontrollato,
- saturare nodi e cluster,
- generare costi imprevisti.
Best practice: impostare sempre maxReplicaCount in base (alla capacità del cluster, ai limiti dell'event source, al carico massimo sostenibile dall'appliazione).4. Hardcodare secret e credenziali negli YAML
Inserire credenziali direttamente nei manifest Kubernetes:
- viola le best practice di sicurezza,
- espone segreti nei repository,
- rende difficile la rotazione delle chiavi.
Best practice: usare TriggerAuthentication con Kubernetes Secrets oppure provider esterni (Vault, Azure Key Vault, AWS Secrets Manager)5. Ignorare il comportamento dello scale-down
Molti team si concentrano solo sullo scale-up, ma lo scale-down è spesso la parte più delicata:
- riduzioni troppo aggressive possono causare cold start frequenti,
- applicazioni stateful o con cleanup asincrono possono perdere messaggi o task in corso.
Best practice: configurare correttamente cooldownPeriod, testare il comportamento con carichi intermittenti, verificare che l’applicazione gestisca shutdown e retry in modo idempotente.Conclusione: quando KEDA fa davvero la differenza
KEDA è uno strumento potente ma mirato. Non va usato ovunque, ma dove il carico è guidato dagli eventi offre vantaggi enormi:
Takeaway pratici
- Usa KEDA quando CPU ≠ lavoro
- Combinalo sempre con HPA (non escluderlo)
- Progetta lo scale-down prima dello scale-up
- Tratta i secret come cittadini di prima classe
- Inizia semplice, raffina con advanced
Se Kubernetes è il sistema operativo del cloud, KEDA è ciò che lo rende reattivo al mondo reale.