You’re Integrating AI the Wrong Way in Your Java Ecosystem (If You’re Not Using Spring AI)




In the last twenty years, the Java Enterprise world has never followed trends.
It has gone through necessary architectural transformations.
| Evolution | Why it became essential |
|---|---|
| SOA | To move away from unmanageable monolithic systems |
| REST | To finally standardize integration |
| Microservices | To isolate responsibilities and enable independent releases |
| Cloud Native | To stop designing around servers |
| Kubernetes | To automate tasks that previously required entire teams |
Each time, it wasn’t about technological enthusiasm — it was about architectural survival.
At a certain point, not adopting that change became the real risk.
Today, it’s happening again.
But for the first time, the change is not about infrastructure.
It’s about the very nature of application logic itself.
It’s called Generative AI.
For the first time in the history of enterprise software, we have a component that:
- understands natural language
- generates content
- uses company knowledge
- makes contextual decisions
- can interact with existing systems
This is not a technological improvement. It is a paradigm shift in how software can operate.
And this is where I see the biggest mistake emerging:
“Let’s just make an HTTP call to OpenAI.”
It’s the same mistake we saw with SOAP, REST, and microservices.
Trying to use new technology without changing the way the architecture is designed.
The result is always the same:
fragile code, hard to maintain, untestable, unobservable, and not portable.
The right question is not:
“How do I use an LLM?”
The right question is:
How do I integrate an LLM into a Spring Boot–based Java Enterprise architecture while maintaining the same quality standards I have always required from my software?
That is exactly why Spring AI exists.

The Real Problem Spring Developers Are Facing
Those who work with Spring Boot know how to build excellent systems:
- clean APIs
- testable microservices
- observable code
- maintainable architectures
Then an LLM arrives, and suddenly new questions appear — questions for which previous experience is no longer enough:
- Where do prompts live in the code?
- How do I manage conversational context?
- How do I prevent hallucinations?
- How do I test something that is inherently non-deterministic?
- How do I integrate private company documents?
- How do I provide real-time data to the model?
- How do I monitor costs and token usage?
- How do I make all of this production-grade?
Without a framework, AI enters the project like a foreign body.
With Spring AI, it becomes a first-class architectural component.
Integrating an LLM with Spring AI does not mean using unusual SDKs or making manual HTTP calls.
It means declaring a Spring bean.
@Bean
public ChatClient chatClient(ChatClient.Builder builder) {
return builder.build();
}Message Roles: Speaking Correctly with an LLM
An LLM does not reason over a single string, but over messages with roles:
- System → model behavior
- User → request
- Assistant → response
- Function/Tool → interaction with code
Spring AI models these roles explicitly and makes them portable across different providers. Same code. Different LLMs. No rewrites.
This is architectural design, not technical integration.
String response = chatClient.prompt()
.system("You are a professional HR assistant")
.user("Explain the leave policy")
.call()
.content();Memory: Solving the Stateless Nature of LLMs
LLMs are, by nature, completely stateless.
Each call is independent from the previous one. For the model, every request is a brand-new conversation.
And yet, when we use ChatGPT, we have the feeling that it “remembers.”
The reality is far less magical and far more architectural:
someone stores the conversation history, persists it, and sends it back to the model with every request as part of the context.
This mechanism, which may seem trivial, is actually one of the most critical aspects when bringing an LLM into an enterprise system.
Because this is where the real questions begin:
- Where do I store the conversation?
- Do I keep it in memory? In a database? In a distributed cache?
- How do I associate it with a user, a session, or a tenant?
- How much history do I send back to the model? All of it? Only part of it?
- How do I avoid wasting tokens unnecessarily?
- How do I manage multiple conversations at the same time?
- How do I make all of this testable and maintainable?
Without a framework, conversational context management quickly turns into fragile code scattered across the application.
Spring AI introduces the concept of Chat Memory as an explicit part of the architecture.
Memory is no longer an implementation detail, but a configurable system component:
- persistence of conversation history
- user/session-based management
- integration with external storage systems
- control over how much context is sent back to the model
This is what makes it possible to build:
- real enterprise assistants
- serious multi-turn chatbots
- contextual conversational systems
- intelligent interactions that evolve over time
Without Chat Memory, you are building a demo.
With Chat Memory, you are building an enterprise conversational system.
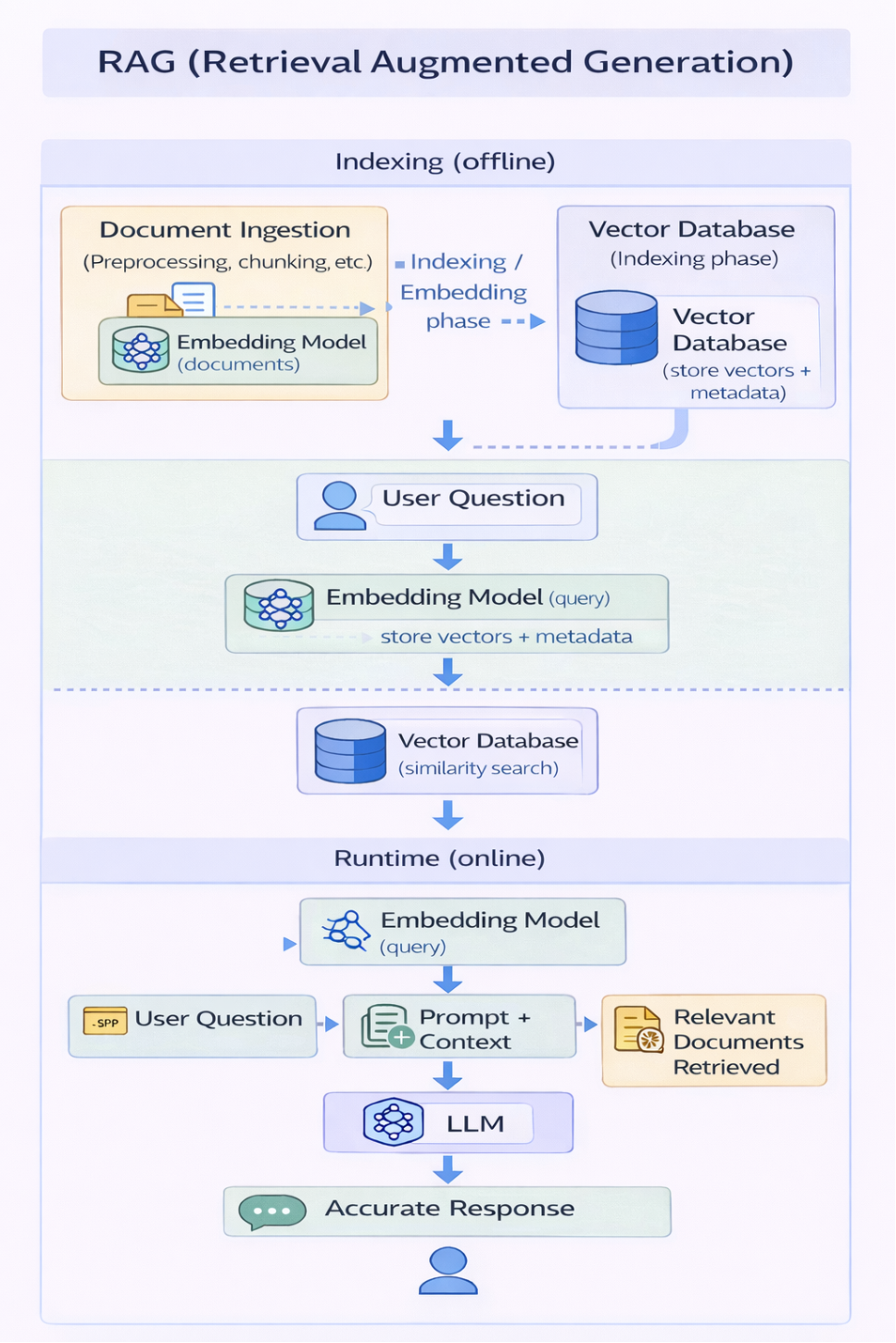
RAG: Making Company Documents Known to the Model
Retrieval Augmented Generation is the point where Generative AI stops being generic and becomes truly useful in an enterprise context.
LLMs, as powerful as they are, know nothing about your company.
They do not know:
- internal PDFs
- policies
- operational manuals
- proprietary documentation
- internal knowledge bases
- contracts, procedures, regulations
Without RAG, the model answers using only the public knowledge it was trained on.
And in a business environment, that is not enough.
RAG introduces a completely new architecture around the model.
Company documents are not simply “passed to the model.”
They are:
- analyzed and split into chunks
- transformed into vector embeddings using an embedding model
- stored in a vector database along with metadata
This is the indexing phase.
Then, at runtime, when a question arrives:
- the question itself is transformed into an embedding
- the vector database performs a similarity search
- only the truly relevant documents are retrieved
- those documents are injected into the prompt as context
At that point, the model is no longer answering “on its own.”
It answers using the company knowledge you dynamically provided.
This has enormous effects:
- it drastically reduces hallucinations
- it makes responses domain-specific
- it optimizes token usage (only relevant context is sent)
- it allows the model to “know” the company without retraining it
And this is where Generative AI becomes truly enterprise-ready.
Because you are no longer asking the model to be smart.
You are building a system that provides the right knowledge at the right time.
Tool Calling: When the Model Starts Taking Action
Up to this point, the LLM has been used to generate better answers.
With Tool Calling, the paradigm changes completely.
The model is no longer used only to produce text.
It is used to decide when real application logic must be executed.
This is where AI stops being “chat” and becomes intelligent automation integrated into the system.
In Spring AI, a tool is simply a Java method exposed to the model.
But the architectural point is much deeper.
The real flow is not:
LLM → Tool
The real flow is:
Agent (your Spring application) ⇄ LLM
Agent → Tool
The model suggests a function call.
It is the application that remains in control and executes the method.
This allows the model to:
- query real-time databases
- call internal APIs
- create tickets
- send emails
- read up-to-date data
- interact with any existing system
AI is no longer an external system.
It becomes a decision-maker that triggers your business logic.
@Tool
public String getCurrentWeather(String city) {
return weatherService.fetch(city);
}
chatClient.prompt("What's the weather in Rome?")
.call()
.content();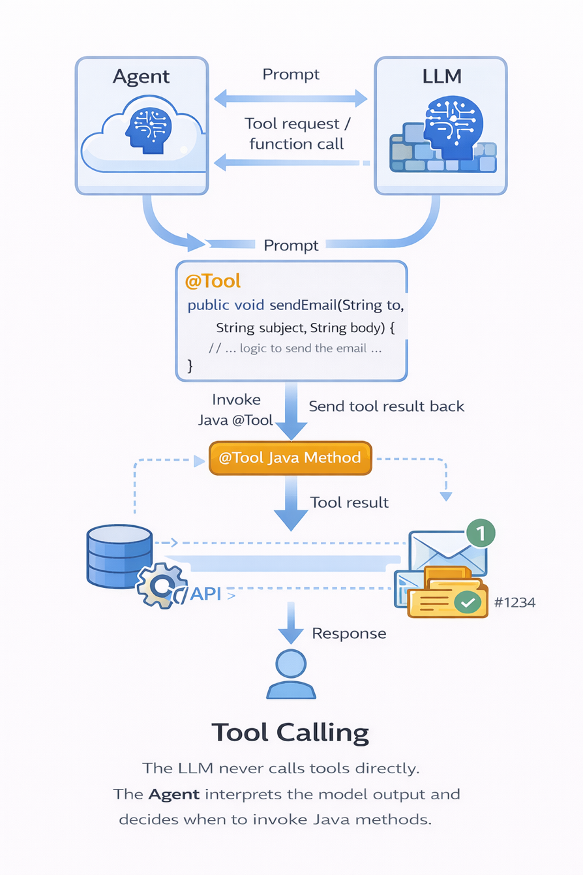
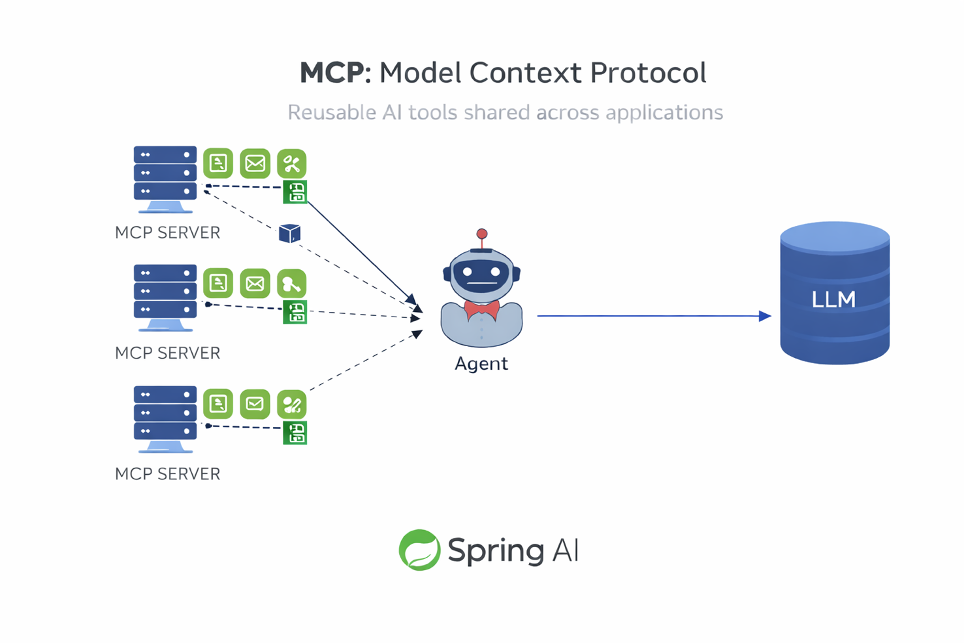
MCP: Making Tools Reusable Across Applications
The next step is natural.
If tools are Java methods, and if these tools begin to represent real business capabilities…
why should they live only inside a single application?
This is where the Model Context Protocol (MCP) comes into play.
MCP is not “a central server.” It is a protocol.
With MCP, microservices become MCP servers:
- they expose tools
- they describe their capabilities
- they make those capabilities invocable by agents
Exactly as happened years ago with REST APIs.
MCP is to AI tools what REST was to service integration.
Spring AI natively supports MCP, allowing you to:
- turn Spring Boot microservices into MCP servers
- expose reusable tools
- build distributed agent-based orchestrations
- keep everything within the same ecosystem of deployment, security, and governance
The result is powerful:
AI does not introduce a new parallel world.
It plugs directly into the existing microservices architecture.
Testing: The Point Almost Everyone Ignores
Here you touch on one of the most underestimated points of all.
With an LLM:
same input ≠ same output
Traditional tests based on assertEquals simply do not work.
But this does not mean that AI is not testable.
It means it must be tested in a different way.
Spring AI introduces the concept of an Evaluator:
an LLM that semantically evaluates the output of another LLM.
You are no longer verifying:
“Is the response identical?”
You are verifying:
- Is the response semantically correct?
- Does it respect domain rules?
- Does it answer the question?
- Does it contain conceptual errors?
EvaluationResult result = evaluator.evaluate(prompt, response);
assertTrue(result.isPass());This is a huge mindset shift for anyone building enterprise software.
You are not giving up on testing…
you are evolving the way testing is done.

Observability: When AI Finally Becomes Operable (and Governable)
There is one aspect that almost every company discovers too late when they start experimenting with LLMs:
as long as AI is just an HTTP call, it is invisible.
You don’t know:
- how many tokens you are consuming
- how much each request actually costs
- where the latency is (LLM? RAG? tools?)
- when the model fails
- how it impacts service performance
- how it scales under load
It becomes a black box inside your system.
And a black box, in an enterprise context, is unacceptable.
Spring AI radically changes this scenario by bringing AI into the Spring Boot Actuator ecosystem.
This means AI exposes metrics like any other component of your system.
Metrics such as:
- token usage per request
- LLM call latency
- RAG pipeline performance
- tool usage
- errors and fallbacks
- throughput under load
All of this can be automatically integrated with:
- Prometheus
- Grafana
- distributed tracing
- existing monitoring systems
But there is an even more delicate aspect.
When you use an LLM as a SaaS (OpenAI, Anthropic, Gemini, Mistral), every token is money.
Without observability, you have no control over costs.
You don’t know:
- which service consumes the most
- which endpoint generates the most expense
- which prompt is inefficient
- which RAG pipeline is injecting too much context
- where to optimize to reduce consumption
With Spring AI, costs become measurable like any other operational metric.
AI finally enters the domain of governance.
It stops being “something magical” and becomes something you can monitor, measure, optimize, and govern.
And in an enterprise architecture, this is just as important as RAG and Tool Calling.
Because it’s not enough for AI to work.
It must be operable.
It must be controllable.
It must be sustainable over time.

The Architectural Point That Changes Everything
Without Spring AI, AI in a Java project remains just a technical integration.
An HTTP call to an external model. Special code, isolated, difficult to test, monitor, and govern. Something that lives at the edges of the architecture.
With Spring AI, AI instead becomes:
a first-class architectural component.
And this radically changes the way you design, test, monitor, and evolve the system.
Because the real value of Generative AI, in an enterprise context, is not the AI itself.
It is its deep integration into the existing ecosystem.
The moment AI:
- follows the same design rules as your microservices
- enters your CI/CD pipeline
- becomes observable through Actuator, Prometheus, Grafana
- scales with Kubernetes like any other service
- is testable with the same quality standards
- is governable with the same architectural practices
it stops being a “technological novelty.”
It becomes part of the system.
It becomes something controllable, predictable, operable.
It becomes enterprise.
And then the question becomes almost natural.
If your stack is Java Enterprise, if your ecosystem is already based on Spring Boot, if for years you have used Spring as the “architectural language” to integrate databases, queues, REST, security, and cloud…
why would you integrate AI with a different key?
Every time you introduced something new — REST, messaging, cloud, Kubernetes — you did it through the same gateway:
Spring.
Spring has always been the way you made new technologies part of your system without breaking it.
Spring AI is exactly that.
It is the same key you have used for years to open a new room in your architecture.
Only this time, inside that room, there is intelligence.
The Limits of Spring AI (and When You Need Something More)
It is important to be very clear about one point.
Spring AI was not created to be a framework for complex agent orchestration.
It was created to solve a very specific problem:
integrating Generative AI into Spring Boot applications in an architecturally correct way.
And at this, it excels.
Spring AI is perfect when:
- you want to add “intelligence” to a microservice
- you want to integrate RAG with your documents
- you want to expose Java tools to the model
- you want to build enterprise assistants and chatbots
- you want to preserve testability, observability, and governance
- you want AI to follow the same rules as your Spring ecosystem
In these scenarios, Spring AI is probably the best choice today in the Java world.
But when the nature of the problem changes, the tool must change as well.
When you start designing:
- complex agent workflows
- dynamic decision chains between multiple LLMs and multiple tools
- iterative reasoning loops
- non-linear orchestrations
- execution graphs that change at runtime
- systems where AI is no longer “inside a service,” but becomes the engine of the application flow itself
Spring AI begins to show its limits.
Because its model is intentionally linear and declarative, very similar to what LangChain does in the Python world:
prompt → model → tool → result
It is perfect for application integration.
It becomes less natural for building complex agentic systems.
This is where tools like LangChain4j (the Java equivalent of LangChain) or approaches inspired by LangGraph start to provide real value.
These frameworks are not designed to integrate AI into an application.
They are designed to build applications around AI.
The difference is subtle, but fundamental.
| Spring AI | LangChain4j / LangGraph-style approach |
|---|---|
| AI inside the microservice | The microservice becomes a node in the agentic graph |
| Linear flow: prompt → tool → response | Non-linear flows, graphs, loops, dynamic decisions |
| Architectural integration | Agentic orchestration |
| Perfect for RAG, tools, assistants | Perfect for complex agents and advanced workflows |
It is not a replacement.
It is a possible next step as the architecture evolves.
Many mature architectures start like this:
- Spring AI to integrate AI into existing services
- MCP to make tools reusable
- A higher layer (LangChain4j / agentic logic) that orchestrates these MCP Servers into more complex workflows
At that point, Spring AI is not abandoned.
It becomes the foundation on which something even more sophisticated is built.
The Final Message
Spring AI is the right tool when you need to bring AI into your Java ecosystem.
If, over time, AI starts to drive the application flow itself, you may need tools designed for more complex orchestrations.
And that is a natural evolution — not a mistake in the initial choice.