Oltre il server: anatomia del pensiero serverless




Parte 1 — Il tempo del serverless
Introduzione
Ogni rivoluzione tecnologica inizia nel momento in cui una limitazione diventa insopportabile.
Per decenni, lo sviluppo software è stato vincolato a un assioma invisibile: per eseguire codice serve un server. E quel server, fisico o virtuale, è sempre stato la nostra gabbia.
L’abbiamo configurato, mantenuto, patchato, scalato, monitorato. Ogni innovazione applicativa era mediata da un’infrastruttura che chiedeva di essere domata.
Poi, qualcosa è cambiato.
Il cloud aveva già dissolto il possesso dell’hardware. Ma con il serverless, il passo successivo è stato più audace: dissolvere anche la gestione.
Non si tratta di un’astrazione infrastrutturale, ma di un cambio culturale profondo.
Il serverless è la risposta di un’industria che non accetta più di spendere il proprio capitale cognitivo nella manutenzione di ciò che non crea valore diretto.
Non è solo una scelta tecnica, è una reazione naturale all’entropia.
“Build and run applications without thinking about servers.”
Questa definizione, tanto essenziale quanto spiazzante, racchiude la filosofia di AWS Lambda e di tutto ciò che le ruota intorno: l’infrastruttura diventa trasparente, e il focus si sposta definitivamente sul business intent.
Le organizzazioni che intraprendono questa transizione non cercano solo efficienza. Cercano velocità, elasticità e serenità operativa.
Il serverless non promette di fare di più. Promette di farlo con meno: meno costi fissi, meno complessità, meno errori umani.
E nel mondo del software moderno, meno è davvero di più.
Il nuovo ruolo dell’architetto
In un mondo serverless, l’architetto non è più il custode dell’infrastruttura: è il compositore di comportamenti.
Il suo lavoro non è decidere quanti nodi debbano sostenere il carico, ma quando e perché una funzione debba esistere.
Pensare serverless significa progettare in termini di eventi, reazioni e confini di dominio.
Ogni componente diventa una “cellula autonoma” — una Lambda che vive solo per il tempo necessario a rispondere a un evento, poi scompare.
Questo modo di ragionare impone un cambio radicale: l’architetto non disegna più un monolite che respira all’unisono, ma un ecosistema che evolve indipendentemente.
Il provisioning, l’autoscaling, la disponibilità: tutto viene demandato al cloud provider.
Il suo compito diventa allora quello di modellare il flusso del valore, non quello delle risorse.
In questa visione, l’architettura non è più un diagramma statico ma un comportamento emergente.
È qui che la disciplina architetturale si avvicina alla biologia: un insieme di funzioni che cooperano, competono, si rigenerano.
Un sistema serverless ben progettato non vive su un’infrastruttura, ma grazie ad essa.
Il viaggio verso una soluzione completamente serverless
Ogni organizzazione che decide di abbracciare il serverless attraversa un percorso che inizia con una domanda semplice ma destabilizzante: “E se smettessimo di preoccuparci dei server?”
La risposta non è mai immediata, perché il serverless non si adotta — si interiorizza.
Serve un cambio di mentalità, di pipeline, di ownership.
Il team deve imparare a pensare per eventi, a rinunciare al controllo ossessivo e a fidarsi di un’infrastruttura invisibile.
Il primo passo è quasi sempre un pilota: un microservizio isolato, un processo batch o una funzionalità sperimentale.
Da lì, la curva è esponenziale.
Ogni funzione Lambda che nasce diventa un tassello di un ecosistema più grande: un mosaico di compute-on-demand, orchestrato da API Gateway, alimentato da S3 e DynamoDB, esposto al mondo attraverso CloudFront.

Il percorso non è lineare. È un’evoluzione fatta di compromessi e scoperte.
Molti team passano da un’architettura ibrida — container e Lambda insieme — fino a raggiungere, gradualmente, una soluzione completamente serverless, dove ogni strato è delegato a un servizio gestito.
Alla fine di questo viaggio, si scopre che la vera conquista non è l’assenza dei server, ma l’assenza della paura di cambiare.
Architettura logica e il dilemma della Lambda
L’architettura serverless nasce da una tensione costante tra semplicità e granularità.
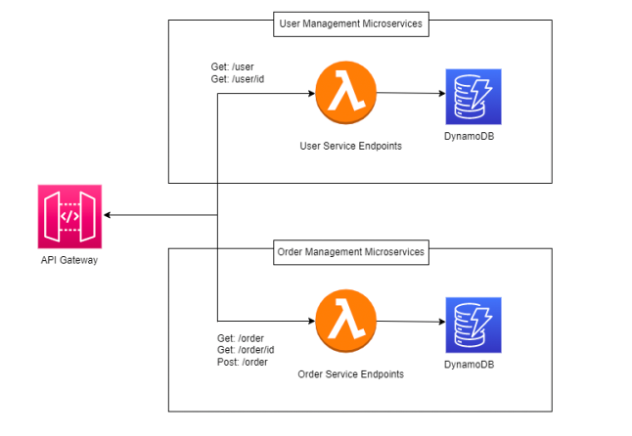
Ogni team si trova presto davanti a una scelta: costruire una Lambda monolitica per microservizio, o frammentare la logica in Lambda per singola feature.
Nel primo caso — una Lambda per microservizio — si ottiene compattezza e rapidità d’avvio.
Il cold start è minimo, la gestione è lineare, e il deploy avviene “tutto ogni volta”.
È un approccio che ricorda il micro-monolite: un pezzo unico ma facilmente scalabile.
Tuttavia, quando l’applicazione cresce, il debugging diventa un incubo.
Le dipendenze si moltiplicano e ogni modifica richiede un rilascio completo.
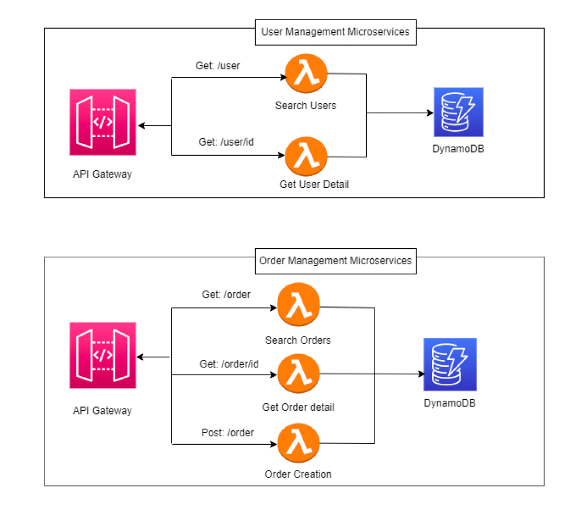
Nel secondo scenario, si adotta una Lambda per ogni funzionalità.
Il microservizio diventa una collezione di funzioni autonome che collaborano.
Il cold start può aumentare, ma il deployment diventa chirurgico: deploy only what changes.
La complessità si sposta verso l’orchestrazione, ma in cambio si ottiene flessibilità e indipendenza dei rilasci.
In realtà, nessuna delle due filosofie è “giusta” in senso assoluto.
Le architetture più evolute adottano un modello ibrido, in cui il confine tra funzioni è dettato dal dominio, non dalla tecnologia.
Un dominio “core” può meritare Lambda più granulari; uno “satellite”, più compatto.
Il segreto del serverless è questo: non esiste più una migliore architettura, esiste solo la più appropriata in quel momento.
Il database come dominio
La vera rivoluzione del serverless non è nell’eliminazione dei server, ma nella dissoluzione dei database monolitici.
Nel modello tradizionale, ogni servizio è legato a un unico datastore centrale: un grande lago dove tutto confluisce, tutto dipende e tutto rallenta.
Nel serverless, invece, ogni microservizio possiede il proprio database — scelto in base al proprio modello di dominio.
È il principio del Database per Service.
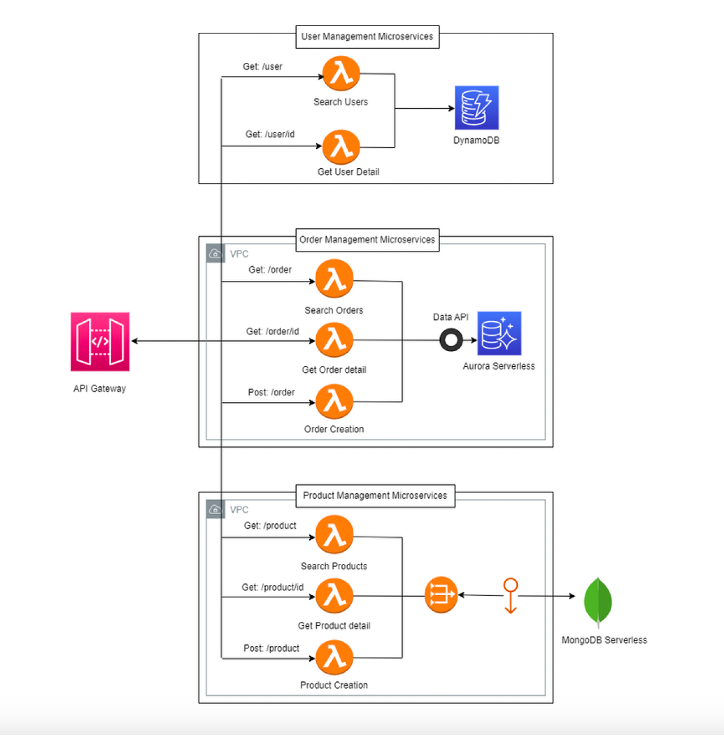
Un servizio che gestisce sessioni utente può vivere perfettamente con DynamoDB, sfruttandone la scalabilità lineare e i costi per richiesta.
Un altro, dedicato all’analisi dati, potrà affidarsi ad Aurora Serverless v2 per query SQL dinamiche.
Altri ancora useranno S3 come archivio di eventi o file statici.
I vantaggi di questo approccio sono evidenti:
- resilienza naturale: il failure di un database non blocca il sistema;
- granularità nello scaling: ogni dominio scala in base al proprio traffico;
- autonomia nei rilasci: un team può evolvere il proprio schema senza coordinarsi con altri.
Ma il rovescio della medaglia è la perdita della transazionalità globale.
Le operazioni cross-domain richiedono pattern avanzati, come saga orchestration o eventual consistency.
La consistenza non è più immediata, ma è intenzionale.
Questo è uno dei punti più difficili per i team che migrano al serverless:
accettare che la consistenza sia un effetto emergente, non un assioma architetturale.
Parte 2 — Anatomia del serverless
Polyglot engineering e strumenti di sviluppo
Ogni rivoluzione tecnologica è anche una liberazione del linguaggio.
Nel mondo serverless, il concetto di “stack” perde significato: ogni microservizio, ogni Lambda, ogni funzione può essere scritta nel linguaggio che meglio serve lo scopo.
È il trionfo del polyglot engineering.
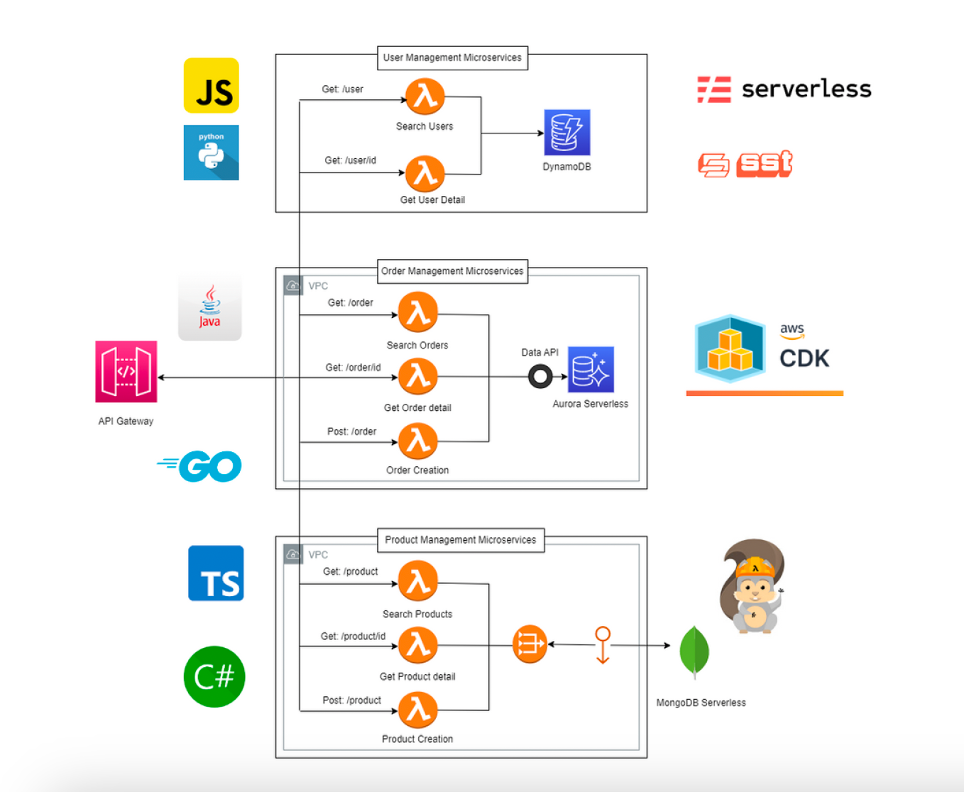
AWS non impone uno stack, lo accoglie.
Lambda supporta nativamente Python, Node.js, Go, Java, .NET, Ruby, ma soprattutto consente custom runtime.
Questo significa che la tecnologia non è più un vincolo organizzativo, ma una scelta di contesto.
Un team data-driven potrà usare Python per la velocità di sviluppo; un team di backend enterprise potrà scegliere Java per la solidità dell’ecosistema; un servizio ad alte prestazioni potrà usare Go per la leggerezza del runtime.
Il vero architetto serverless non sceglie un linguaggio per uniformità, ma per funzionalità e costo cognitivo.
Sulla dimensione dello sviluppo, AWS ha creato un arsenale maturo:
- AWS CDK (Cloud Development Kit) permette di definire l’infrastruttura come codice, usando linguaggi familiari (TypeScript, Python, Java). È la “DSL architetturale” del serverless.
- AWS SAM (Serverless Application Model) fornisce un framework dichiarativo per orchestrare Lambda, API Gateway, DynamoDB e Step Functions in modo nativo.
- Serverless Framework e SST (Serverless Stack Toolkit) completano la visione, abilitando pipeline CI/CD e gestione multi-ambiente.
Questi strumenti realizzano un principio fondamentale: l’infrastruttura diventa un artefatto di sviluppo, non un layer amministrativo.
Il risultato? Team più autonomi, tempi di rilascio più rapidi, e un’energia creativa che si era perduta nelle gerarchie DevOps.
Lo sviluppatore torna ad essere un autore, non un manutentore.
Le API come linguaggio del sistema
Ogni architettura serverless è, in ultima analisi, una rete di conversazioni.
Microservizi che si parlano, frontend che interroga backend, funzioni che reagiscono a eventi.
La qualità di questa comunicazione determina la qualità dell’intero ecosistema.
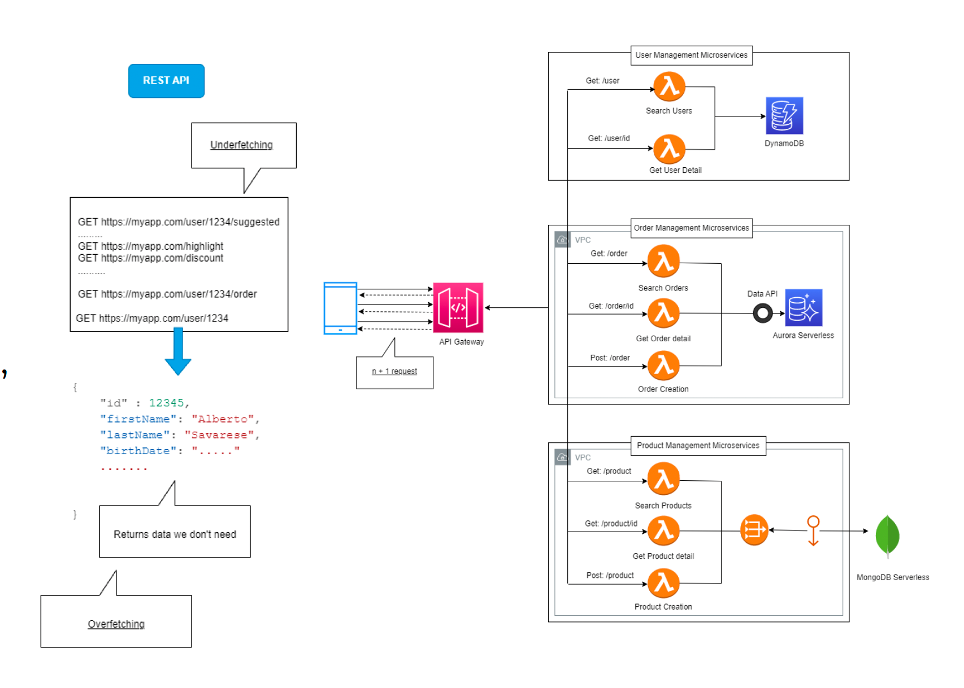
Per anni, il mondo REST ha dominato la scena.
Ma in un ambiente serverless, dove la scalabilità è atomica e i costi sono per invocazione, REST mostra i suoi limiti:
ogni endpoint è un roundtrip, ogni chiamata una latenza, ogni payload un costo.
Il client, spesso, chiede troppo o troppo poco.
In questo scenario si impone GraphQL, e con esso AWS AppSync, che offre una versione pienamente serverless del paradigma.
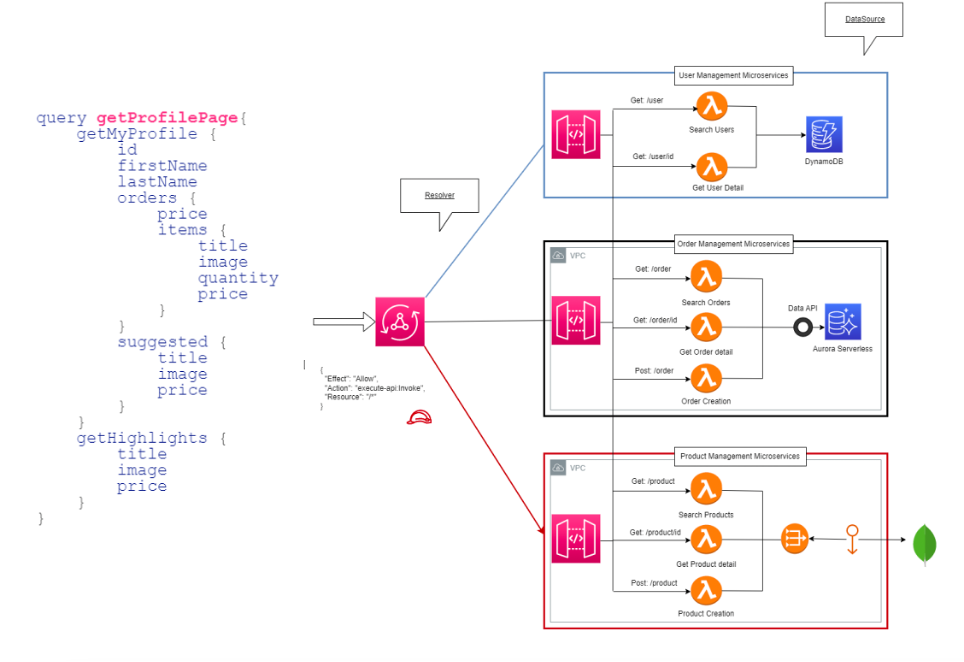
GraphQL rovescia il modello:
- Il client non consuma risorse, ma naviga un grafo di dati.
- Ogni nodo dello schema (type, query, mutation, subscription) è connesso a un resolver, cioè un connettore verso un datasource (una Lambda, un database, un’API REST).
- AppSync gestisce caching, sicurezza e performance, eliminando la necessità di un layer intermedio.
Il vantaggio non è solo tecnico ma filosofico:
GraphQL ridà potere al client, permettendogli di definire quali dati vuole e in quale forma.
La rete diventa semantica, non protocollare.
E poi c’è la subscription, il cuore pulsante del modello reattivo:
ogni volta che una mutation avviene, i client sottoscritti ricevono automaticamente un evento.
Niente polling, niente code aggiuntive: solo propagazione naturale dell’informazione.
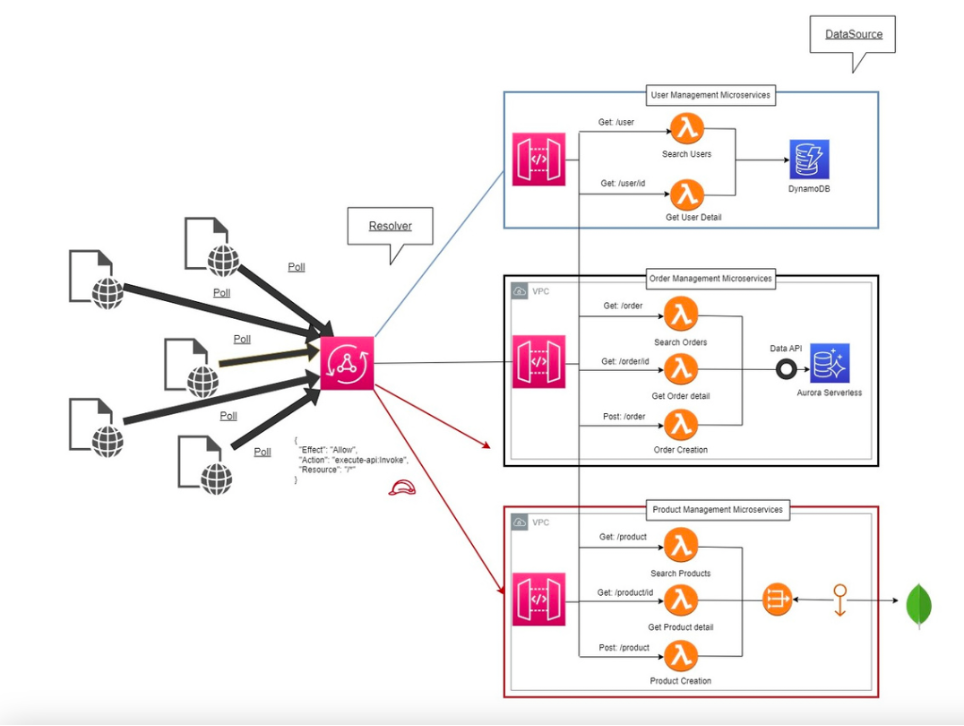
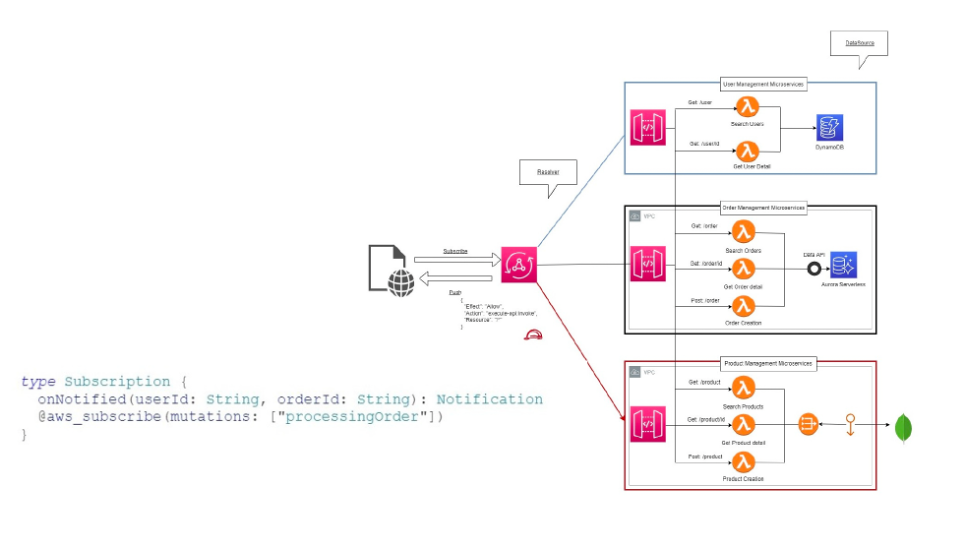
In un mondo asincrono, GraphQL non è solo un protocollo: è un patto di fiducia tra client e server.
Orchestrazione e coreografia: la danza invisibile dei microservizi
Se il serverless è un insieme di funzioni autonome, chi decide quando ciascuna di esse deve agire?
La risposta è duplice, e definisce due scuole di pensiero: orchestrazione e coreografia.
Nell’orchestrazione, un servizio centrale — spesso una Step Function di AWS — governa il flusso come un direttore d’orchestra.
Ogni step è definito, tracciato, osservabile. È perfetto per processi complessi: pagamenti, onboarding, flussi di validazione.
Il vantaggio è la prevedibilità, il limite è la rigidità.
La coreografia, al contrario, si basa sull’autonomia:
i microservizi si scambiano eventi attraverso Amazon EventBridge, reagendo ciascuno in modo indipendente.
Non esiste un centro, ma un ecosistema in equilibrio.
Il vantaggio è la scalabilità naturale, il limite è la visibilità globale.
Un sistema serverless maturo combina i due modelli:
usa orchestrazioni per i flussi deterministici e coreografie per quelli evolutivi.
È una danza invisibile, ma perfettamente sincronizzata.
L’architetto serverless diventa un coreografo: non impone sequenze, crea condizioni perché le sequenze emergano spontaneamente.
Dal backend al pixel: Amplify e il serverless frontend
Il serverless non è solo un paradigma di backend: è una filosofia che attraversa anche il frontend.
La domanda è: può un’applicazione web essere completamente serverless?
Con AWS la risposta è sì, grazie a Amplify, CloudFront, Lambda@Edge e S3.
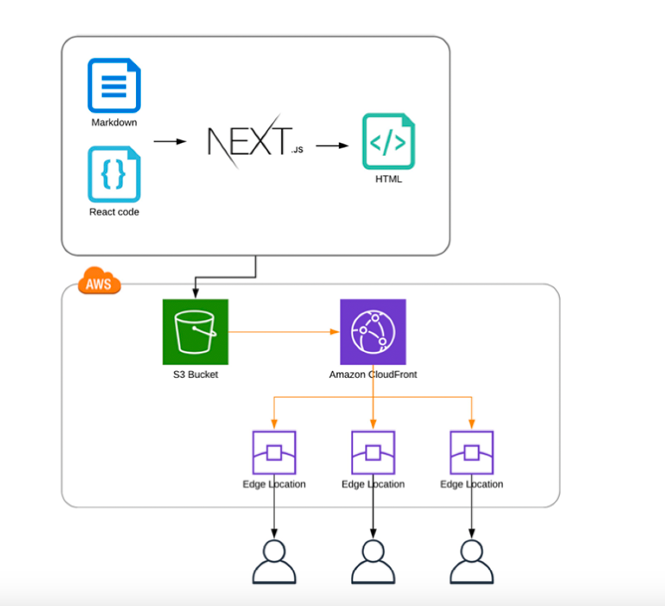
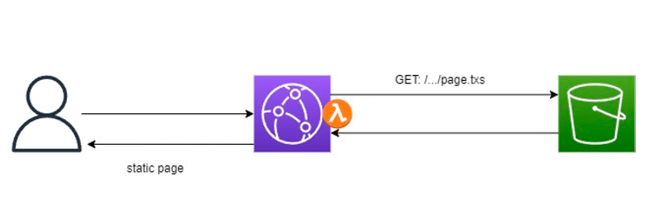
Immaginiamo il ciclo:
il codice del frontend viene buildato e caricato in un bucket S3;
CloudFront distribuisce globalmente i contenuti, agendo da CDN;
Lambda@Edge interviene nelle fasi di viewer request/response per generare Server-Side Rendering (SSR) dinamico.
Questo approccio risolve uno dei talloni d’Achille delle single-page app: la SEO.
Grazie all’SSR serverless, i motori di ricerca ricevono contenuti renderizzati, migliorando l’indicizzazione senza sacrificare performance o caching.
Amplify, infine, automatizza tutto il ciclo di vita:
gestione del versioning, CI/CD, environment multipli, e deployment atomico.
È l’incarnazione pratica del principio “no servers, no friction”.
Il risultato è un frontend globale, scalabile e distribuito, dove ogni pixel è servito dall’edge più vicino al cliente.
La distanza tra codice e utente si riduce letteralmente a millisecondi.
Observability: vedere l’invisibile
Il serverless, per quanto elegante, ha un difetto nascosto: la sua invisibilità.
Quando non ci sono istanze da monitorare né log centralizzati, capire cosa accade diventa un’arte.
Ed è qui che entra in gioco la observability strategy.
AWS offre un set completo di strumenti:
- CloudWatch Logs per la raccolta dei log di ogni Lambda,
- CloudWatch Metrics per la misurazione di throughput, error rate e latenza,
- CloudWatch Alarms per la reazione automatica agli eventi,
- X-Ray per la tracing distribuita.
Ma per sistemi complessi, soluzioni come Lumigo aggiungono un livello superiore: correlano le invocazioni, mostrano il flusso tra funzioni e servizi, misurano i costi per transazione.
L’observability nel serverless non è un lusso, è un requisito ontologico.
Senza di essa, un’architettura distribuita diventa un labirinto.
Con essa, diventa un sistema autodiagnostico, capace di raccontare da solo dove e perché qualcosa non funziona.
Osservare un sistema serverless significa imparare ad ascoltare la sua musica di eventi — una sinfonia di invocazioni, code e stream che, se compresa, rivela il battito reale dell’applicazione.
Parte 3 — Maturità e visione del serverless
Il modello dei costi: il prezzo dell’invisibilità
Uno degli aspetti più affascinanti del serverless è anche il più insidioso: paghi solo quello che usi.
Ma dietro questa apparente semplicità si nasconde una nuova complessità: la prevedibilità economica.
Nel mondo tradizionale, i costi erano stabili ma inefficaci — VM accese 24/7, anche nei momenti di quiete.
Nel mondo serverless, i costi sono dinamici, ma potenzialmente imprevedibili: ogni invocation di Lambda, ogni query a DynamoDB, ogni chiamata API Gateway contribuisce a un mosaico di micro-transazioni.
Un team maturo non subisce questa complessità, la trasforma in consapevolezza.
Costruisce modelli di costo “per evento”, non per mese.
Analizza i flussi di business e li traduce in metriche di consumo.
Un esempio concreto: un’applicazione di food delivery può stimare il costo medio per ordine sommando:
- invocazioni Lambda per orchestrazione e notifiche,
- chiamate GraphQL su AppSync,
- storage di eventi su S3,
- metriche CloudWatch generate durante il flusso.
AWS consente questa visibilità con strumenti come Cost Explorer, Budgets, e il Pricing Calculator, ma è l’architetto che deve trasformarli in una strategia.
Il principio è semplice: prevedere non quanto spenderai, ma perché.
In un mondo pay-per-use, il costo diventa un linguaggio.
E come ogni linguaggio, va imparato e parlato con intenzione.
Sicurezza e identità: la fiducia come architettura
Nel serverless, la sicurezza non si configura: si disegna.
Ogni Lambda, ogni API, ogni bucket S3 deve essere protetto per definizione, non per eccezione.
AWS Cognito diventa il cuore di questo modello.
Gestisce autenticazione, federazione di identità (Google, Facebook, SAML, OpenID), e genera token JWT che possono essere verificati direttamente dalle Lambda o da AppSync.
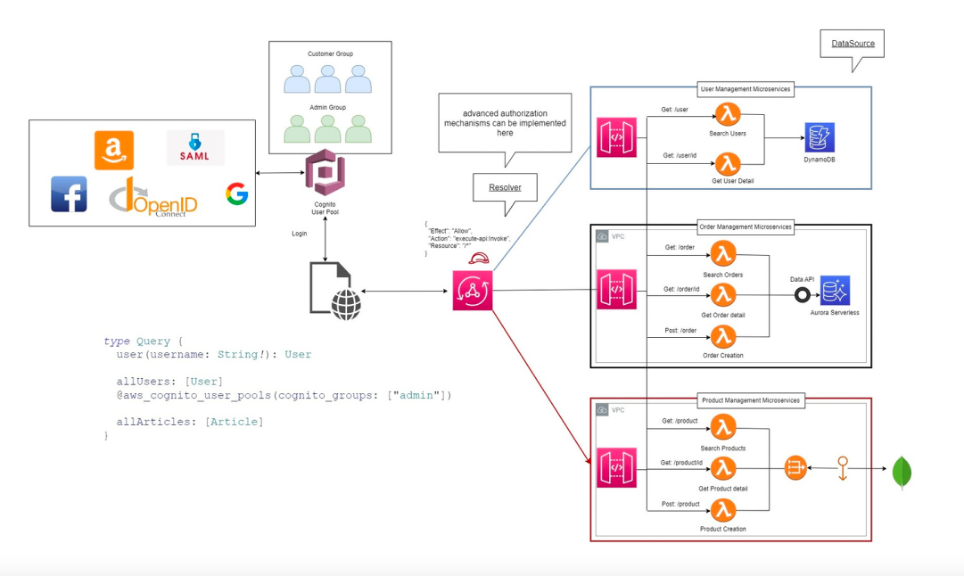
Ma la sicurezza serverless non si ferma al login.
È nella granularità delle IAM policies, nei VPC Endpoint per limitare il traffico interno, nelle Lambda Layer che separano le librerie sensibili dal codice applicativo.
Un approccio evoluto prevede la creazione di custom directives in GraphQL, per mappare l’autorizzazione fino al livello del campo.
Così, una query che richiede un dato sensibile può essere negata senza bisogno di codice aggiuntivo.
La sicurezza serverless è invisibile, ma onnipresente.
È la forma più alta di fiducia: non quella che concedi a un sistema, ma quella che costruisci con esso.
Resilienza e gestione del fallimento
Un sistema serverless ben progettato non si misura da quanto funziona, ma da come reagisce quando smette di funzionare.
La resilienza non è una caratteristica: è un comportamento progettuale.
Il serverless, per natura, tende alla resilienza — ogni funzione è isolata, ogni servizio autoscalante.
Ma la realtà è più complessa.
Un evento mancante, un errore di parsing, una dipendenza non disponibile possono generare “failure silenziose”.
Ecco perché il design resiliente si costruisce su tre pilastri:
- Idempotenza – ogni Lambda deve poter essere rieseguita senza effetti collaterali.
- Retry & DLQ (Dead Letter Queue) – ogni evento fallito deve avere una seconda opportunità, instradata in una coda SQS per il reprocessing.
- Circuit breaker e fallback – un errore ricorrente deve aprire il circuito, isolando il problema e notificando i sistemi upstream.
AWS Step Functions e EventBridge offrono nativamente strumenti per costruire flussi tolleranti.
Ma la vera resilienza nasce nella mentalità del team: trattare l’errore come un cittadino di prima classe, non come un’anomalia.
In un sistema serverless maturo, il fallimento non è più una sorpresa: è una forma di feedback.
Cultura e organizzazione: dal DevOps al DevProduct
Ogni rivoluzione tecnologica produce un effetto collaterale culturale.
Il serverless non fa eccezione.
Eliminando l’infrastruttura, cambia radicalmente la geometria dei team.
Nel modello tradizionale, lo sviluppo e l’operatività erano separati: i dev costruivano, gli ops mantenevano.
Il serverless dissolve questa barriera: non ci sono server da mantenere, quindi non c’è un “dopo la produzione”.
Il ciclo di vita è continuo, end-to-end.
Nasce così una nuova figura: il DevProduct.
Un team non è più proprietario di un componente tecnico, ma di un risultato di business.
Ogni team è responsabile della funzionalità, dei costi, dei log, della resilienza.
Questo modello, reso possibile da servizi gestiti e metriche trasparenti, favorisce una cultura di ownership diffusa e accountability misurabile.
L’impatto sull’organizzazione è profondo:
- meno burocrazia,
- più autonomia,
- meno coordinamento artificiale,
- più collaborazione naturale.
Il serverless non è solo un’architettura tecnologica: è un atto politico nella vita dei team.
Spostando il potere tecnico verso i bordi, crea un’organizzazione più organica, più veloce, più viva.
Trade-off e limiti del modello serverless
Ogni paradigma porta con sé la propria ombra.
Il serverless non è la risposta universale, e il vero architetto lo sa.
Il primo limite è il cold start: l’istante in cui una Lambda dormiente deve risvegliarsi per gestire la richiesta.
AWS ha mitigato molto questo aspetto con il provisioned concurrency, ma nei sistemi a bassa latenza resta un fattore da considerare.
Poi c’è il vendor lock-in.
Una soluzione profondamente integrata con Lambda, AppSync e DynamoDB è straordinariamente efficiente su AWS, ma difficile da replicare altrove.
È un trade-off tra libertà teorica e produttività reale.
Altri limiti emergono nei flussi di lunga durata o nelle pipeline ad alta I/O, dove i costi “per invocazione” possono superare un cluster containerizzato.
Eppure, la maturità architetturale non sta nell’evitare i limiti, ma nel progettarli consapevolmente.
Un sistema serverless non è mai totalmente puro: è una composizione pragmatica.
L’obiettivo non è eliminare i server, ma eliminare il pensiero server-centrico.
Dopo l’hype: la maturità silenziosa del serverless
C’è stato un tempo in cui il termine serverless era ovunque: nei titoli delle conferenze, nei pitch delle startup, nei manifesti del cloud moderno.
Era la promessa di una rivoluzione definitiva: il sogno di scrivere solo logica di business e lasciare che il resto accadesse da sé.
Poi, com’è naturale in ogni ciclo tecnologico, l’entusiasmo si è affievolito.
Il serverless ha smesso di essere la parola magica sulle labbra di tutti.
E qualcuno, guardando i trend o il silenzio dei social, ha pensato che fosse finito.
La realtà è l’opposto.
Il serverless non ha perso rilevanza: ha raggiunto la maturità.
Le tecnologie veramente riuscite non vivono di clamore — diventano parte dell’infrastruttura del mondo, così ordinarie da sembrare invisibili.
Quando qualcosa funziona davvero, smettiamo di parlarne come se fosse magia.
Oggi il serverless è questo: non più la promessa di un futuro possibile, ma la normalità del presente.
Non serve annunciarlo, perché si trova già ovunque — nei flussi asincroni di un e-commerce, nei backend di un’app mobile, nei sistemi di analisi dati che scalano all’infinito senza che nessuno debba pensarci.
Questa è la vera vittoria del paradigma: essere passato dall’eccezione alla consuetudine.
Non è più un esperimento, è un pattern operativo, una grammatica architetturale interiorizzata da chi costruisce software moderno.
Il serverless non ha perso hype.
Ha semplicemente smesso di averne bisogno.
È entrato nella fase adulta: quella in cui la tecnologia diventa così solida, prevedibile e diffusa da non richiedere più applausi.
È diventato ciò che ogni tecnologia sogna di essere: trasparente, indispensabile e data per scontata.
Conclusioni — Big Thinking Mitigation
Il serverless è il punto d’incontro tra ambizione e sobrietà.
Promette di semplificare, ma richiede di pensare più a fondo.
Liberando l’ingegnere dall’infrastruttura, lo costringe a concentrarsi su ciò che davvero conta: il flusso di valore.
Il concetto di Big Thinking Mitigation, che chiude idealmente il nostro viaggio, rappresenta questo equilibrio:
pensare in grande, ma costruire in piccolo; immaginare ecosistemi globali, ma realizzarli come insiemi di funzioni locali.
Un sistema completamente serverless non è un traguardo tecnologico: è una dichiarazione di metodo.
È dire al mondo che la tecnologia può diventare invisibile, lasciando spazio all’intelligenza, alla creatività e al valore.
In un futuro sempre più connesso, il serverless non sarà l’eccezione: sarà il nuovo default.
E il vero compito dell’architetto non sarà più quello di costruire infrastrutture, ma di creare sistemi che si costruiscono da soli.