Karpenter: un nuovo approccio all’autoscaling intelligente su Kubernetes




Immagina una scena familiare per chi lavora con Kubernetes: la tua applicazione sta andando alla grande, il traffico cresce, i pod cominciano a saturare la CPU. L’Horizontal Pod Autoscaler entra in azione, crea nuove repliche... ma qualcosa si ferma.
Alcuni pod restano nello stato Pending, lo scheduler non trova più spazio, e tu inizi a chiederti:
“Perché Kubernetes non scala anche i nodi?”
Ed è proprio qui che entra in gioco Karpenter.
Un progetto open source nato in AWS, oggi parte del SIG Autoscaling della CNCF , che introduce un nuovo approccio al modo in cui un cluster Kubernetes cresce e si adatta dinamicamente alle esigenze di carico.
Dall’HPA ai limiti del Cluster Autoscaler
Kubernetes è bravissimo a scalare i pod, ma non altrettanto i nodi.
Quando il traffico aumenta, l’HPA (Horizontal Pod Autoscaler) crea nuove repliche basandosi su metriche come l’utilizzo CPU o memoria. Tuttavia, se non ci sono nodi liberi dove eseguirle, i pod rimangono in Pending, in attesa che qualcuno liberi o crei risorse.
Questa “attesa” è il momento in cui il Cluster Autoscaler entra in scena: monitora i pod non schedulabili e cerca di espandere il cluster aggiungendo nuove istanze EC2.
Ma il suo funzionamento, basato su node group statici, è rigido e macchinoso.
Ogni node group deve essere definito in anticipo, con un tipo di istanza fisso e dimensioni uniformi (best practice AWS EKS Cluster Autoscaler).
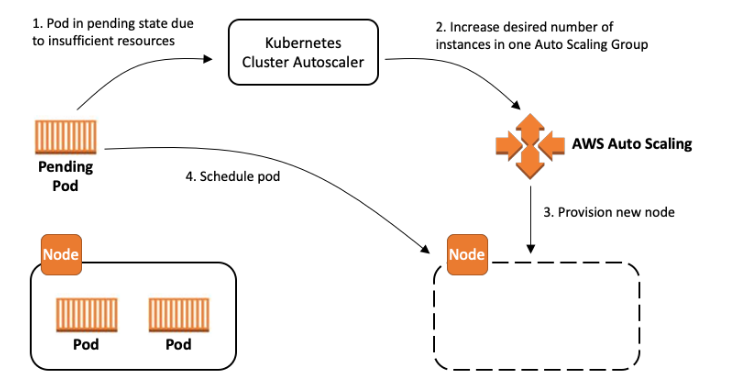
Questo modello funziona... fino a quando non serve flessibilità.
Se domani devi eseguire un workload GPU o un job di AI, devi creare un nuovo node group, riconfigurare l’autoscaling e attendere minuti prima che le nuove istanze siano pronte.
Nel mondo del cloud moderno, minuti possono essere un’eternità.
Le sfide del Cluster Autoscaler
Il Cluster Autoscaler è un buon soldato, ma con armi datate.
Ogni volta che un pod resta unschedulable, invoca un Auto Scaling Group di EC2, che a sua volta crea un’istanza. Questo passaggio — CA → ASG → EC2 — introduce latenza.
Inoltre, la gestione dei node group è un incubo operativo: occorre sapere in anticipo quali tipi di istanze userai, come saranno distribuite tra Availability Zone e se serviranno GPU o storage locali.
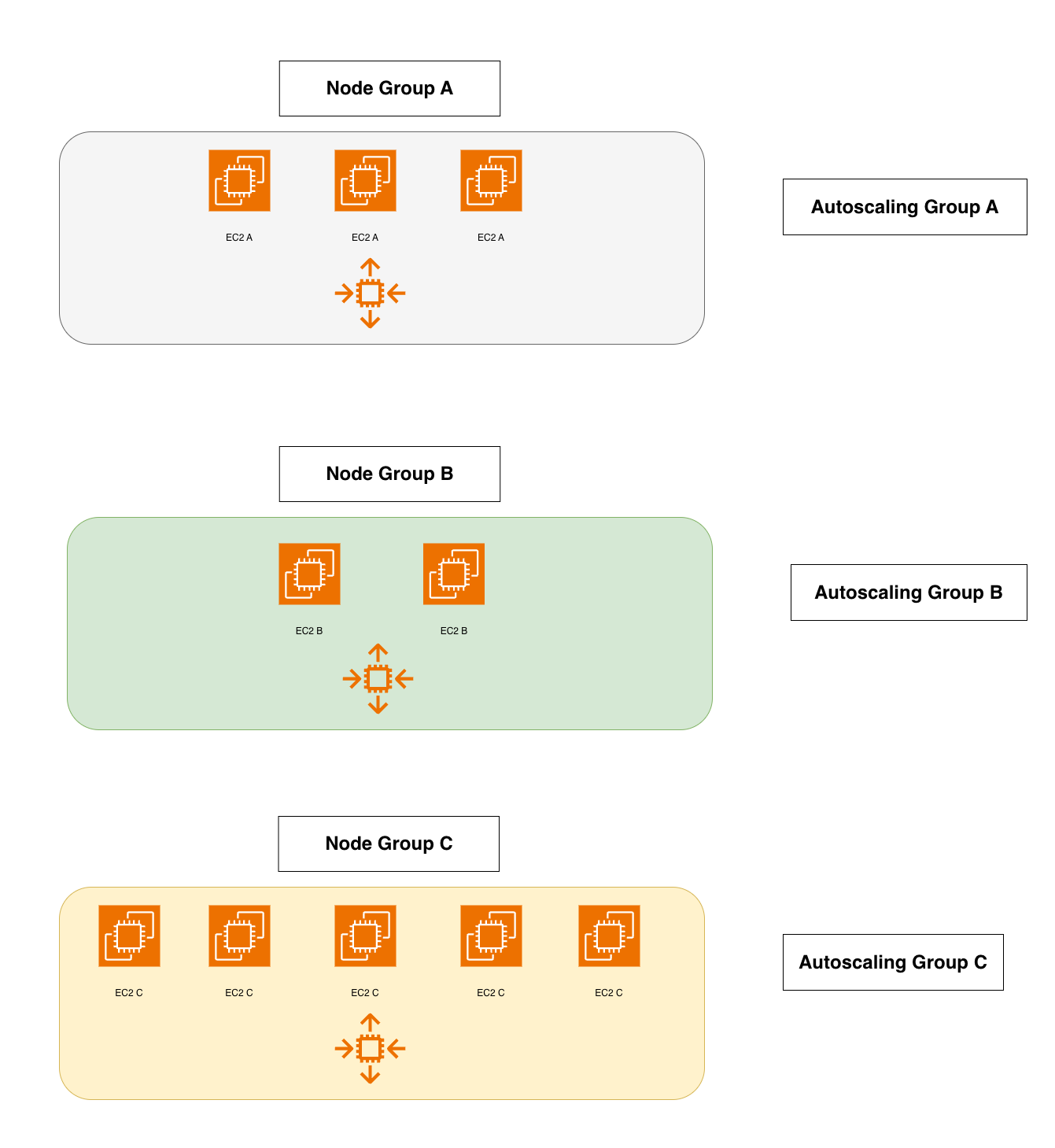
Il risultato?
Scalabilità lenta, poca flessibilità, costi spesso superiori al necessario e un continuo micromanagement dell’infrastruttura.
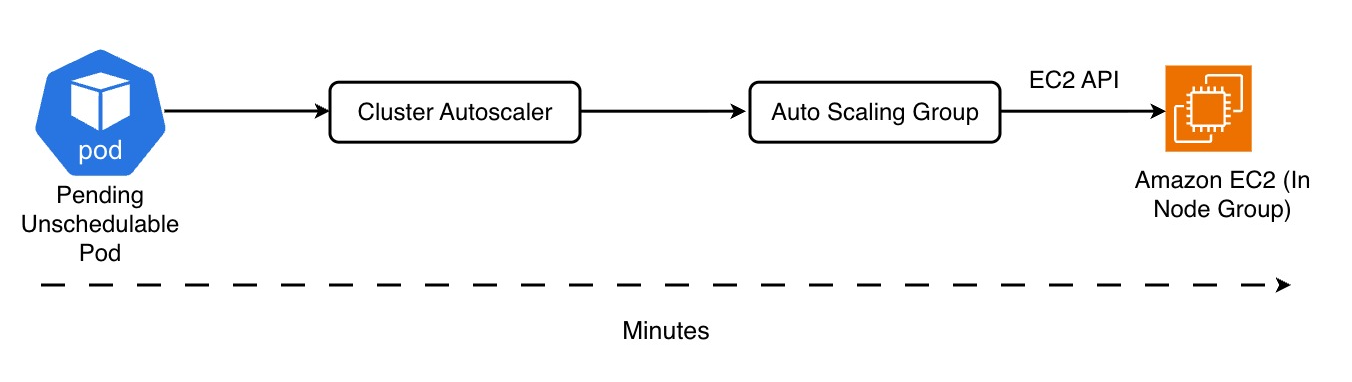
Entra in scena Karpenter
Quando AWS ha annunciato Karpenter, l’obiettivo era chiaro
“Semplificare la gestione dei nodi lasciando che Kubernetes scelga in modo dinamico la risorsa più adatta per ogni workload.”
Karpenter è un autoscaler di nuova generazione, progettato per essere cloud native e Kubernetes native (documentazione ufficiale e guida introduttiva).
Non parla più con gli Auto Scaling Group, ma dialoga direttamente con le API di EC2, rendendo il provisioning estremamente rapido, nell’ordine di decine di secondi fino a uno o due minuti a seconda dell’AMI, dei DaemonSet e della rete.
Karpenter riduce sensibilmente la latenza rispetto al Cluster Autoscaler, ma non è “istantaneo”. È open source, CNCF sandbox project, e oggi è supportato anche su Azure e altri cloud provider.
Nota tecnica: il provider AWS è il più maturo. Per Azure esiste un provider dedicato mantenuto dalla community/Microsoft, ancora in evoluzione e con differenze architetturali.”. Gli altri provider sono in fase sperimentale o non ufficiale.
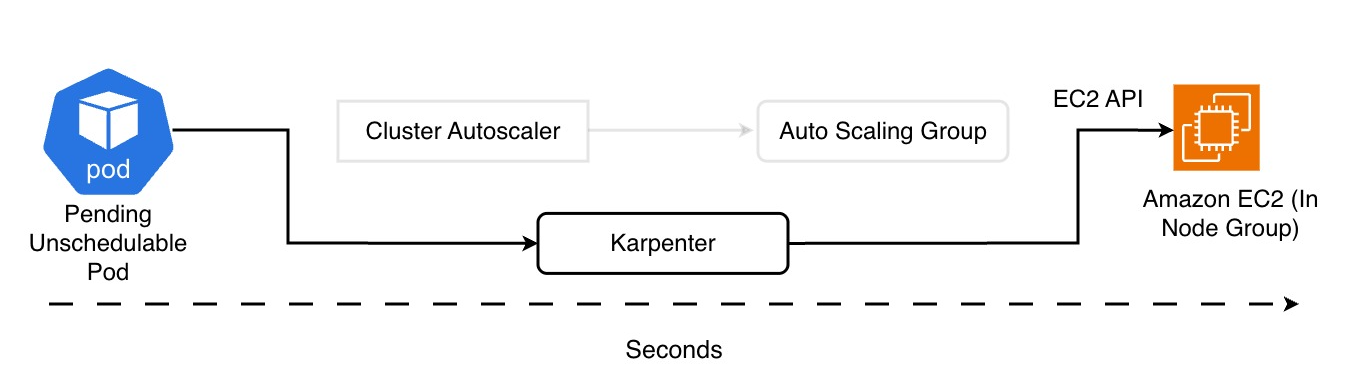
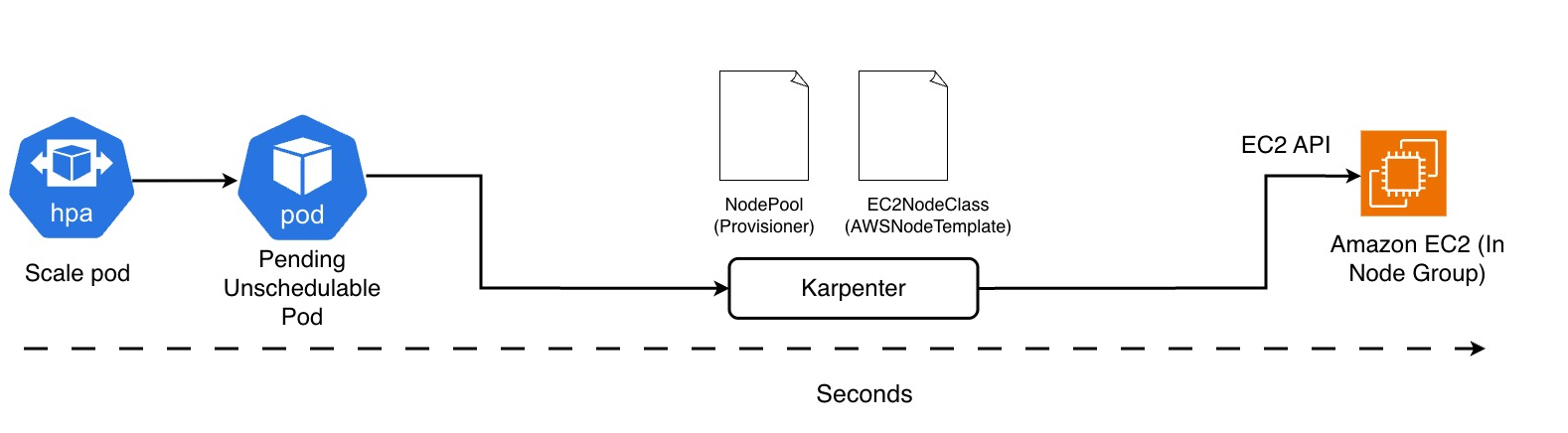
In pratica, se un pod non può essere schedulato, Karpenter interviene in pochi secondi:
valuta le risorse richieste, sceglie il tipo di istanza più adatto e crea un nodo ottimizzato per quel carico, riducendo al minimo la necessità di configurazioni manuali.
Nota tecnica: secondo la documentazione AWS ufficiale e le linee guida CNCF, il provisioning di un nodo con Karpenter può avvenire in meno di un minuto su AWS.
Questo tempo è realistico in condizioni favorevoli — ad esempio con AMI già disponibili, bootstrap rapido e rete pronta — ma può variare in base all’ambiente e alla configurazione del cluster
Come funziona Karpenter (davvero)
Il cuore pulsante di Karpenter ruota attorno a due risorse Kubernetes:
- NodePool – definisce le regole di provisioning: quali istanze EC2 usare, in quali AZ, con che architettura o politica di costo.
- EC2NodeClass – specifica i dettagli “fisici” del nodo: AMI, Security Group, subnet, IAM Role, tag, e così via.
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: general-purpose
spec:
template:
spec:
nodeClassRef:
name: default-ec2
requirements:
- key: "kubernetes.io/arch"
operator: In
values: ["amd64"]
limits:
resources:
cpu: 1000
memory: 4Ti
disruption:
consolidationPolicy: WhenUnderutilized
consolidateAfter: 30s
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default-ec2
spec:
amiFamily: AL2
role: "KarpenterNodeRole"
subnetSelector:
karpenter.sh/discovery: my-cluster
securityGroupSelector:
karpenter.sh/discovery: my-cluster
NodePool + EC2NodeClass + EC2
Quando un pod diventa Pending/Unschedulable, Karpenter controlla i NodePool esistenti, valuta i constraint (architettura, famiglia, tipo di istanza, AZ, costo, disponibilità) e crea la migliore istanza EC2 possibile per quel workload.
Ma il lavoro di Karpenter non si ferma alla semplice creazione di nuovi nodi.
Una delle sue funzioni più evolute è la consolidation, un meccanismo che analizza costantemente l’utilizzo del cluster e sostituisce automaticamente i nodi sottoutilizzati o non più necessari. In questo modo riduce i costi operativi e migliora l’efficienza complessiva senza impatto sui workload.
A questa si affianca la drift detection, che rileva eventuali discrepanze tra la configurazione desiderata e lo stato reale dei nodi (ad esempio cambi di AMI, labels o impostazioni di sicurezza). Quando viene rilevato un “drift”, Karpenter può riprovisionare i nodi per riallinearli in modo trasparente e coerente.
Queste funzionalità, spesso trascurate nelle prime panoramiche, rappresentano il vero passo avanti rispetto ai tradizionali autoscaler: Karpenter non si limita a scalare — ma mantiene nel tempo un cluster più pulito, efficiente e conforme alle policy definite dal team DevOps.
Il risultato è un data plane che si adatta dinamicamente, riducendo sprechi e rigidità operative.
E se vuoi avere controllo fine, puoi specificare limiti, priorità o vincoli direttamente nei manifest YAML di NodePool e NodeClass.
Le istanze Spot e l’intelligenza predittiva
Uno degli aspetti più interessanti di Karpenter è la gestione delle istanze Spot.
Le spot sono economiche ma volatili: AWS può riprenderle con soli due minuti di preavviso.
Karpenter ascolta gli eventi di EventBridge, intercetta il segnale di spot interruption, e in quei 120 secondi provvede a fare il provisioning di un nuovo nodo — decidendo se usare ancora Spot o passare a On-Demand, in base al costo e alla disponibilità (documentazione ufficiale).
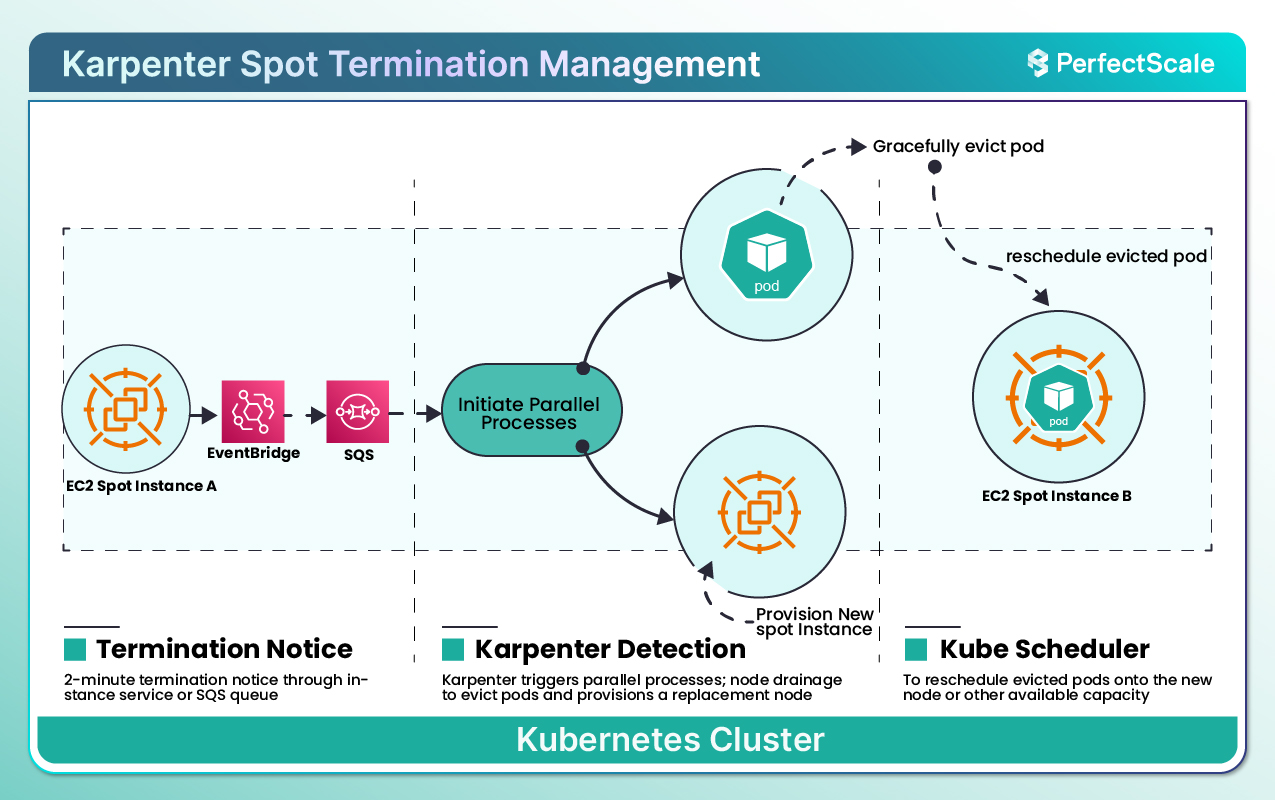
Tutto questo avviene con un intervento umano minimo, e con pieno rispetto delle regole di Kubernetes: drain dei pod, scheduling automatico minimizzando il downtime.
Nota tecnica: Karpenter può ridurre fortemente la disruption durante le interruzioni Spot, ma non può garantire zero downtime in ogni scenario; dipende dai PodDisruptionBudget, dal numero di repliche e dalla capacità disponibile.
Scheduling intelligente: affinità, etichette e team isolation
Karpenter non sostituisce lo scheduler di Kubernetes: lo potenzia.
Puoi continuare a usare nodeSelector, affinity, taints e tolerations per controllare dove i pod devono essere eseguiti.
Vuoi che i workload di CI/CD girino solo su istanze Spot?
Basta assegnare ai nodi provisionati da Karpenter la label capacity-type=spot e usare un nodeSelector nei deployment.
apiVersion: apps/v1
kind: Deployment
metadata:
name: ci-runner
spec:
replicas: 3
selector:
matchLabels:
app: ci-runner
template:
metadata:
labels:
app: ci-runner
spec:
nodeSelector:
karpenter.sh/capacity-type: spot
tolerations:
- key: "workload-type"
operator: "Equal"
value: "ci"
effect: "NoSchedule"
containers:
- name: runner
image: myregistry/ci-runner:latest
resources:
requests:
cpu: "500m"
memory: "512Mi"
Deployment CI/CD su Spot
Hai workload che richiedono GPU o hardware dedicato?
Puoi creare un NodePool specifico che selezioni istanze come p4d.24xlarge, e usare taints/tolerations per garantire che solo i pod compatibili vengano pianificati lì.
Karpenter aggiunge automaticamente etichette standard come topology.kubernetes.io/zone, semplificando la distribuzione multi-AZ e l’alta disponibilità.
Nota tecnica: l’aggiunta delle label di topologia dipende dal provider e dall’immagine nodo; su AWS è automatica, ma può variare altrove.
Strategie di NodePool: single, multiple, weighted
Nel mondo reale, i cluster sono spesso condivisi da più team o applicazioni.
Karpenter gestisce perfettamente scenari multi-tenant, permettendo di usare più NodePool contemporaneamente.
Puoi scegliere tra tre strategie:
- Single NodePool: tutte le applicazioni usano lo stesso insieme di istanze (semplice, ma poco flessibile).
- Multiple NodePools: ogni team ha il suo NodePool, con regole, limiti e label dedicati.
- Weighted NodePools: Karpenter assegna priorità ai diversi tipi di nodi in base ai pesi configurati — ad esempio, può tentare prima con istanze Spot o On-Demand specifiche.
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: gpu-team
spec:
weight: 80
template:
spec:
requirements:
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["p4d.24xlarge"]
---
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: batch-team
spec:
weight: 20
template:
spec:
requirements:
- key: "karpenter.sh/capacity-type"
operator: In
values: ["spot"]
Weighted NodePools
Nota tecnica: i Saving Plans sono un meccanismo di fatturazione AWS, non visibile a Karpenter. È possibile preferire manualmente tipi di istanza coerenti con i propri impegni di costo, ma non c’è integrazione automatica con i Saving Plans.
Il risultato è un equilibrio perfetto tra controllo dei costi e isolamento delle risorse.
Osservabilità: capire cosa fa Karpenter
Karpenter non è una “scatola nera”: tutto è osservabile.
I log si leggono direttamente dai pod del controller (kubectl logs), e le metriche sono esposte nativamente in formato Prometheus , perfettamente integrabili in Grafana.
Metriche come:
- tempo medio di provisioning di un nodo,
- numero di pod pending,
aiutano a misurare l’efficienza del cluster e ottimizzare i costi.
Nota tecnica: Karpenter non espone direttamente il costo stimato per tipo di istanza; per questo servono integrazioni esterne come Datadog, PerfectScale o AWS Cost Explorer.
Disruption Management e Pod Disruption Budget
Karpenter è anche un gestore attivo della “salute” dei nodi.
Può terminare automaticamente nodi sotto-utilizzati (voluntary disruption) o reagire a eventi esterni come interruzioni Spot (involuntary disruption).
Prima di distruggere un nodo, simula la pianificazione dei pod altrove e rispetta i Pod Disruption Budget (PDB) definiti dagli sviluppatori.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: web-frontend-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: web-frontend
PDB di esempio
Questo garantisce che nessuna operazione di manutenzione o ottimizzazione causi downtime, mantenendo sempre il numero minimo di pod richiesto attivo.
Karpenter può inoltre consolidare i nodi eliminando automaticamente quelli parzialmente utilizzati, riducendo i costi e migliorando la densità di utilizzo del cluster. Questa funzione, chiamata Consolidation , consente di mantenere un data plane sempre ottimizzato in base al carico reale.
Conclusione – Più che un autoscaler: un orchestratore intelligente
Karpenter va oltre il concetto tradizionale di autoscaler, offrendo un controllo più dinamico del data plane.
Gestisce in modo intelligente il provisioning delle risorse, rispettando le policy e ottimizzando i costi in tempo quasi reale.
In contesti cloud dinamici, rappresenta un’evoluzione significativa verso infrastrutture più adattive.
Nota per l’adozione in produzione: l’impiego di Karpenter in ambienti mission-critical (best practices AWS EKS + Karpenter) richiede una configurazione attenta di NodePool, PodDisruptionBudget e policy di rete. Una governance chiara di questi elementi è essenziale per sfruttarne la flessibilità senza introdurre instabilità nel cluster.