GraphQL, ma con il pilota automatico: perché (e come) passare da REST ad AppSync senza farsi male




Quando le API non bastano più
C’è un momento, in ogni progetto digitale che cresce, in cui la lentezza non viene dal codice, ma dalle connessioni.
Il backend risponde in millisecondi, il database scala, la CDN fa il suo dovere… ma l’utente aspetta.
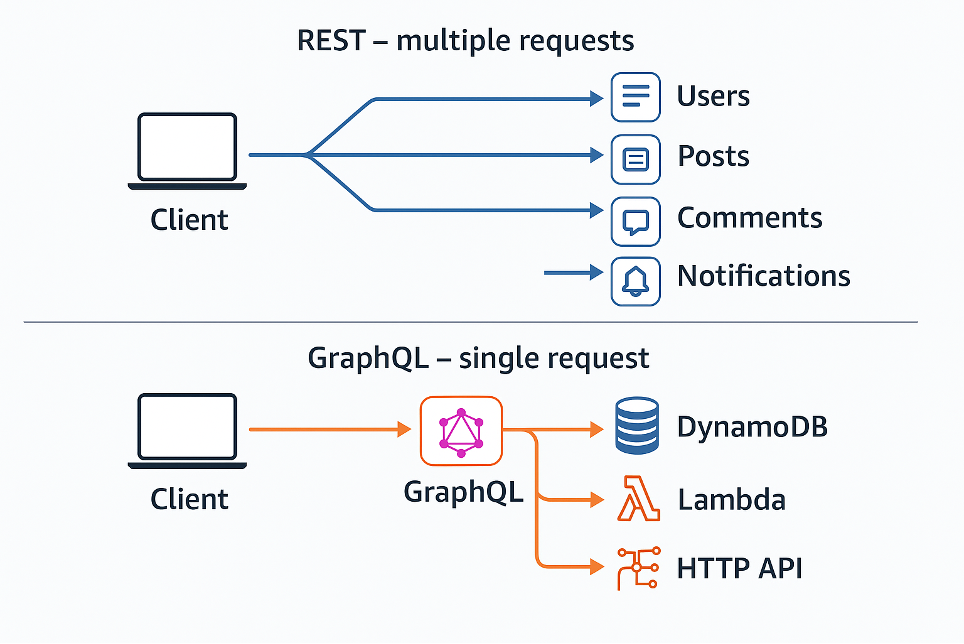
Ogni volta che apre la schermata principale, l’app compie una piccola maratona invisibile: prima chiede il profilo, poi i post, poi le notifiche, poi la lista amici.
Cinque richieste. Alcune in parallelo, altre in sequenza.
Il risultato? Una manciata di secondi che si sommano a ogni gesto.
È qui che molti team si accorgono di essere prigionieri di un modello che ha fatto il suo tempo.
REST, nato in un’epoca in cui i client erano leggeri e i dati poco interconnessi, oggi fatica a raccontare esperienze complesse.
Perché ogni risorsa vive nel suo endpoint, e il client deve orchestrare il tutto, spesso diventando un piccolo orchestratore di microservizi.
Ma c’è un altro modo.
Un modo in cui è il server a comporre la risposta, non il client.
Un modo in cui chiedi solo quello che ti serve, e lo ricevi in un’unica chiamata.
È qui che entra in scena GraphQL.
GraphQL: il linguaggio che dà forma ai dati
GraphQL non nasce per sostituire REST, ma per superarne i limiti strutturali.
È un linguaggio di query per le API, ma anche qualcosa di più profondo:
un contratto esplicito tra chi costruisce l’interfaccia e chi modella i dati dell’applicazione.
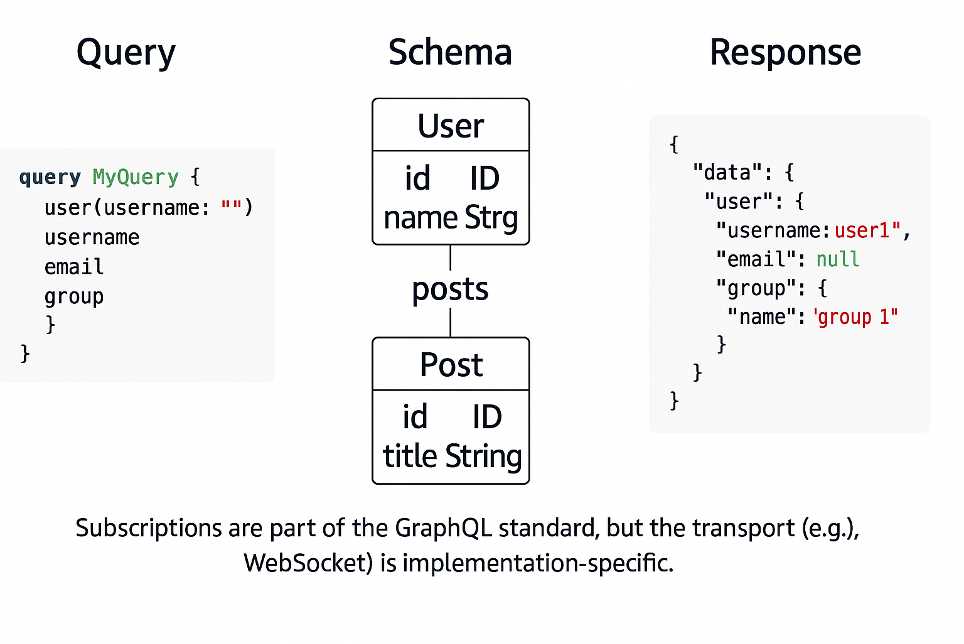
Il cuore di tutto è lo schema GraphQL — una rappresentazione logica e formale del dominio dell’applicazione.
Non è semplicemente la copia di un database: è la mappatura concettuale di come i dati si connettono tra loro e di come possono essere richiesti, modificati o osservati.
In altre parole, lo schema è il grafo che descrive la tua applicazione.
All’interno dello schema esistono tre tipi fondamentali di operazioni:
- Query, che permettono di navigare il grafo e raccogliere informazioni.
Ogni campo richiesto dal client diventa un nodo che il server risolve, attraversando le relazioni definite nello schema.
È il modo con cui il client “legge” la realtà del sistema, muovendosi tra entità e connessioni come in un grafo di conoscenza. - Mutation, che consentono di modificare o creare dati.
Sono l’equivalente delle operazioni di scrittura, aggiornamento o cancellazione: cambiano lo stato dell’applicazione e restituiscono l’oggetto aggiornato.
Anche qui, il contratto è rigoroso: lo schema stabilisce quali operazioni sono consentite e quali campi possono essere manipolati. - Subscription, che permettono di ricevere aggiornamenti in tempo reale quando qualcosa cambia.
Le subscription fanno parte dello standard GraphQL (insieme a query e mutation), ma — e qui sta la sfumatura importante — lo standard non definisce il protocollo di trasporto.
Significa che GraphQL stabilisce come dichiarare e descrivere una subscription, ma lascia a ciascuna implementazione la libertà di scegliere come consegnare gli aggiornamenti (tramite WebSocket, SSE o altri meccanismi).
È proprio qui che AWS AppSync brilla: fornisce un’infrastruttura WebSocket completamente gestita che gestisce connessioni, filtri e consegna dei messaggi, permettendo di ottenere reattività in tempo reale senza dover scrivere o mantenere un layer di pub/sub manuale.
Il risultato è un modello chiaro e potente:
il client non deve più conoscere la topologia del backend o l’indirizzo delle risorse;
gli basta sapere come parlare con lo schema.
Da quel momento, il server si occupa di comporre la risposta come un puzzle, interfacciandosi con i data source necessari — database, funzioni Lambda, API HTTP o sistemi esterni — e restituendo al client esattamente ciò che ha richiesto: né un byte in più, né uno in meno.
REST vs GraphQL: due modelli per due epoche
Per capire davvero perché GraphQL è nato, bisogna prima guardare con onestà a cosa è diventato REST negli anni.
REST ha avuto un merito enorme: ha portato ordine nel caos delle API, imponendo un modello chiaro fatto di risorse, endpoint e verbi HTTP.
Ma quel modello è nato in un mondo diverso — un mondo in cui le applicazioni erano pagine web, non ecosistemi interattivi che si aggiornano in tempo reale.
Oggi, le interfacce moderne chiedono molto di più.
Non vogliono solo recuperare dati, ma comporli, fonderli, aggiornarli continuamente.
E qui REST inizia a mostrare le sue crepe.
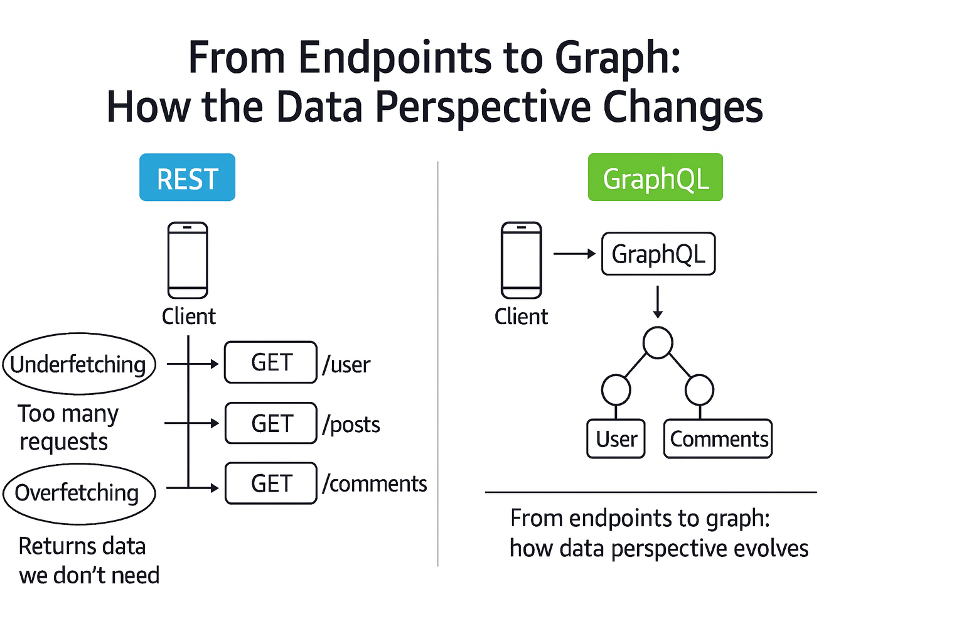
Con REST, ogni risorsa vive nel suo endpoint.
Se vuoi costruire una schermata complessa — per esempio, mostrare il profilo utente, i suoi post e i commenti di ciascun post — devi orchestrare più chiamate:
una per l’utente, una per i post, una per i commenti.
Magari anche in sequenza, perché ti serve prima l’ID del post per chiedere i commenti.
È la classica catena di richieste che inizia innocente e finisce in un groviglio di round-trip, latenza e logica duplicata nel client.
GraphQL cambia radicalmente il punto di vista.
Non pensi più in termini di “endpoint”, ma di grafo di dati.
Ogni tipo nello schema rappresenta un nodo; ogni relazione, un collegamento.
E la query è semplicemente un modo di navigare quel grafo.
Così, invece di dire al server quali URL chiamare, il client dichiara di quali campi ha bisogno:
query GetUser {
user(id: "123") {
name
posts {
title
comments {
content
author { name }
}
}
}
}
Una richiesta.
Una risposta.
Tutto ciò che serve per comporre una schermata intera, in un singolo viaggio di rete. Questo è il cuore del vantaggio di GraphQL:
- niente overfetching (non scarichi dati inutili),
- niente underfetching (non devi fare chiamate extra per completare le informazioni),
- e soprattutto nessuna dipendenza rigida dagli endpoint, che spesso obbliga il client a conoscere la struttura interna del backend.
Dove REST espone un insieme di risorse, GraphQL espone un modello di dominio, un grafo che rappresenta la tua applicazione in modo naturale.
È per questo che si dice che GraphQL non è un sostituto di REST, ma un’evoluzione del modo di pensare ai dati.
E quando questa evoluzione incontra una piattaforma completamente gestita come AWS AppSync, la combinazione diventa ancora più potente:
niente server da mantenere, risoluzione automatica delle query, caching nativo, sicurezza integrata e real-time gestito.
I resolver: l’anima del grafo
Se lo schema GraphQL è la mappa che descrive come sono fatti i dati e come si collegano tra loro, i resolver sono le mani che percorrono quella mappa.
Sono le funzioni che traducono la richiesta del client in azioni concrete sul backend: leggere un record, calcolare un valore, recuperare un’informazione da un servizio esterno.
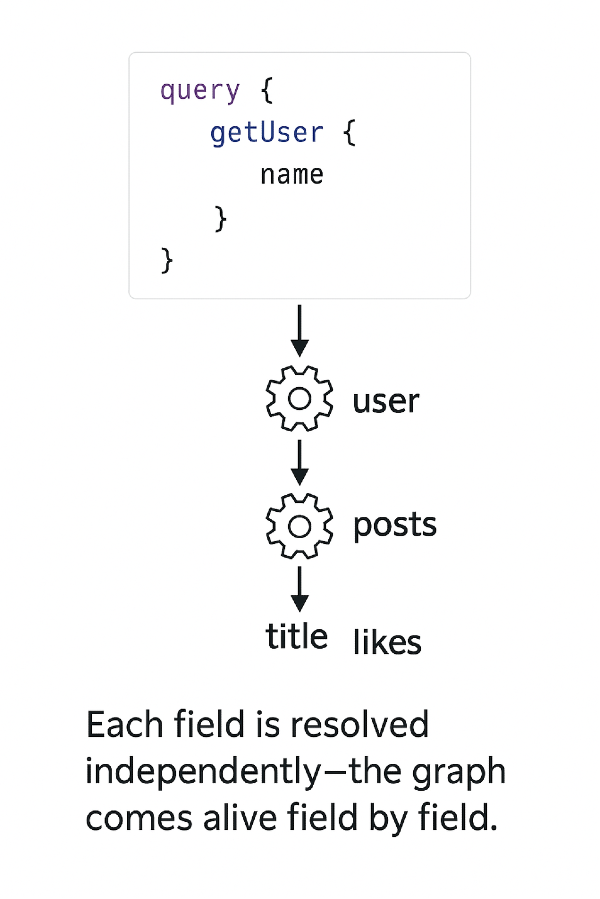
Ogni campo di una query GraphQL viene risolto da un resolver. Quando il client chiede ad esempio:
{
user(id: "42") {
name
posts {
title
likes
}
}
}
il server non restituisce tutto “in blocco”, ma esegue una piccola funzione per ogni campo — una per user, una per name, una per posts e così via.
Ognuna di queste sa dove prendere quel pezzo di informazione e come restituirlo nella forma prevista dallo schema.
È questo meccanismo che permette a GraphQL di ricostruire la risposta come un puzzle, seguendo il grafo dei dati passo dopo passo.
Non si tratta solo di interrogare un database, ma di comporre informazioni da più fonti, mantenendo coerenza e tipizzazione lungo tutto il percorso.
I resolver possono essere semplici — quando un campo corrisponde direttamente a un valore noto — oppure più complessi, quando devono combinare più dati, applicare regole o filtrare risultati.
In entrambi i casi, il principio resta lo stesso: ogni campo del grafo è autonomo, e la sua logica di risoluzione è esplicita e dichiarata.
Questo approccio rende GraphQL prevedibile e trasparente:
ogni dato esiste perché qualcuno lo ha risolto in modo deterministico.
E proprio questa modularità è ciò che consente di costruire API evolutive, dove si possono aggiungere nuovi campi o relazioni senza rompere le parti esistenti.
AppSync: GraphQL con il pilota automatico
Fin qui abbiamo visto come GraphQL, di per sé, sia un linguaggio elegante e coerente: lo schema disegna il grafo, i resolver gli danno vita, e il server orchestra tutto campo per campo.
Ma nella pratica quotidiana — dove bisogna pensare a infrastruttura, sicurezza, autenticazione, caching e scalabilità — costruire e mantenere un server GraphQL completo può diventare rapidamente complesso.
È qui che entra in gioco AWS AppSync, la piattaforma gestita di GraphQL che toglie dal tavolo tutto ciò che non è logica di business.
Non serve installare un server, né gestire socket o load balancer, né scrivere codice per lo scaling.
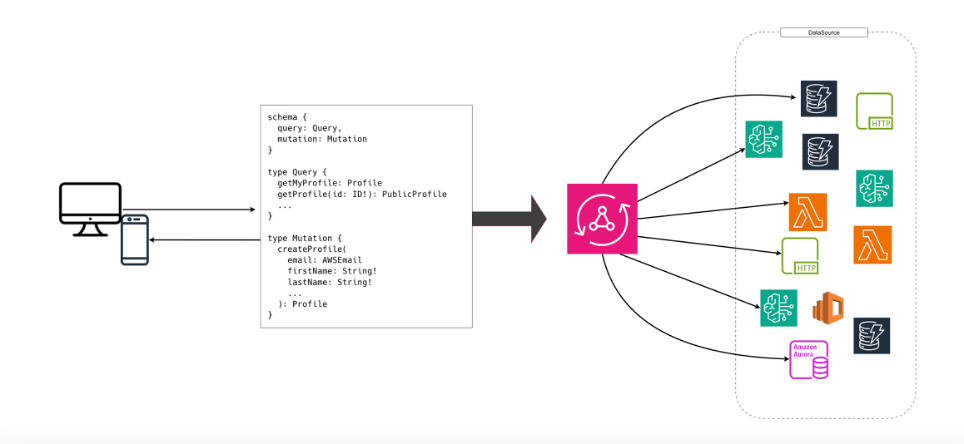
AppSync è un layer orchestratore completamente serverless: riceve le query, autentica gli utenti, risolve i campi attraverso i data source e restituisce la risposta pronta — il tutto con alta disponibilità e pagamento a consumo.
Nativamente si integra con:
- DynamoDB, per letture e scritture rapide e scalabili
- AWS Lambda, per logiche applicative personalizzate
- HTTP, per accedere a servizi REST o API esterne
- EventBridge, per architetture event-driven e notifiche asincrone
- Bedrock, per sfruttare servizi di generative AI
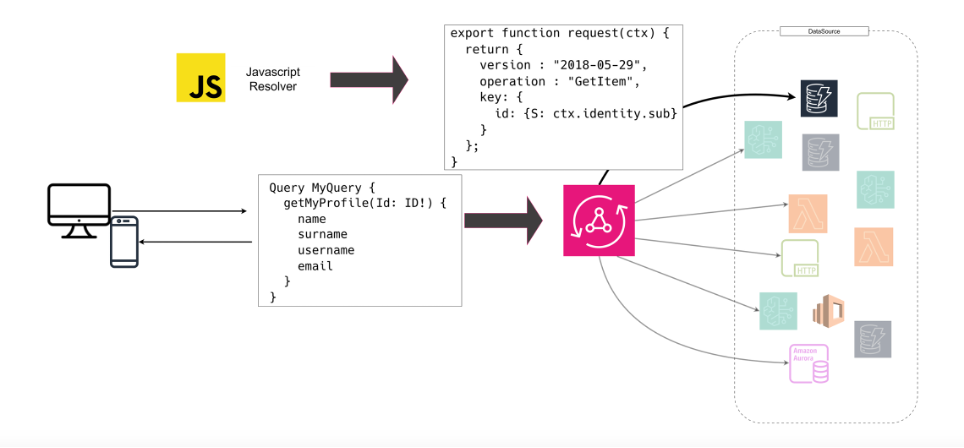
Come AppSync implementa i resolver
In GraphQL ogni campo è risolto da una funzione.
In AppSync, questi resolver diventano componenti configurabili, strettamente integrati con i data source AWS.
È qui che il concetto visto prima prende forma concreta.
1. Unit resolver
È il tipo più semplice: associa un campo a un’unica operazione verso un data source.
Si configura tramite VTL (Velocity Template Language) o, più recentemente, tramite JavaScript resolver.
Questo approccio “dichiarativo” consente di modellare logiche anche complesse senza scrivere codice server-side, rendendo il flusso prevedibile e a bassa latenza.
2. Pipeline resolver
Quando un’operazione richiede più step — ad esempio, validare un input, arricchire dati da più sorgenti, e comporre una risposta finale — AppSync permette di concatenare fino a dieci funzioni di resolver in sequenza.
Ogni funzione ha il proprio data source e si passa il risultato alla successiva tramite ctx.prev.result.
È come costruire una pipeline: pulita, modulare, riusabile.
Questo modello riduce l’uso di Lambda a casi davvero necessari, migliorando efficienza e costi.
3. Lambda resolver
Per quando serve codice “vero”, AppSync può invocare funzioni AWS Lambda.
Sono perfette per logiche personalizzate, integrazioni con sistemi esterni o trasformazioni non gestibili con i template.
AppSync ottimizza anche questo percorso grazie al batch invoke, che raggruppa più risoluzioni nella stessa invocazione per minimizzare round-trip e cold start.
Esempio di javascript resolver
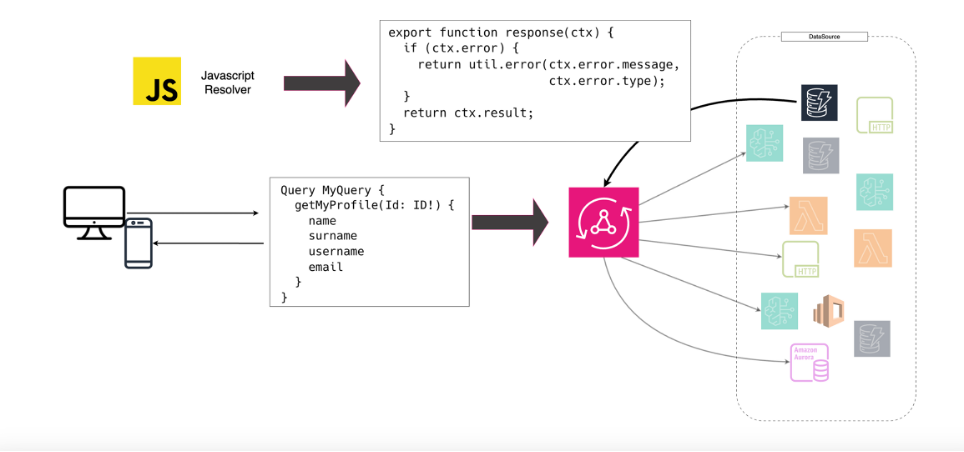
Caching e performance
AppSync offre un sistema di caching per resolver, configurabile per singola operazione o campo.
A differenza di un cache globale, questo approccio è più granulare e consente di massimizzare la hit ratio, riducendo la pressione su DynamoDB o Lambda.
In progetti reali, una cache ben posizionata può raggiungere oltre il 95–99% di hit, abbattendo costi e latenza.
Consiglio pratico: usa caching per-resolver nei campi “freddi” o altamente riutilizzati, come liste statiche, lookup o metadati. Evita di usarlo per richieste mutate frequentemente o personalizzate per utente.
Scalabilità e affidabilità native
AppSync eredita la scalabilità dei servizi AWS su cui poggia.
Non ci sono istanze da mantenere: scala automaticamente in base al carico, gestendo simultaneamente milioni di richieste.
E poiché i resolver operano vicino ai data source (spesso nello stesso piano AWS), la latenza rimane bassa e prevedibile anche sotto carico elevato.
Perché un approccio gestito è più efficiente
Costruire un server GraphQL “a mano” significa occuparsi di autenticazione, throttling, logging, scaling, e connessioni real-time.
AppSync integra tutto questo di default:
- la sicurezza si basa su IAM, Cognito e OIDC
- le subscription (real-time) si appoggiano a WebSocket gestiti
- il monitoraggio si integra con CloudWatch e X-Ray
- e tutto il piano di esecuzione è serverless
In altre parole, AppSync non è solo un’implementazione di GraphQL: è una piattaforma di orchestrazione dei dati.
Un livello intermedio che collega API, servizi e fonti eterogenee, mantenendo però l’esperienza GraphQL intatta per il client.
Il risultato: un GraphQL che cresce con te
Con AppSync puoi partire piccolo — ad esempio, mettendo un’interfaccia GraphQL davanti a un paio di API REST esistenti — e poi farlo evolvere aggiungendo nuovi data source, pipeline resolver e caching.
Tutto senza riscrivere né preoccuparsi di scaling o provisioning.
In pratica, AppSync ti permette di concentrarti su ciò che davvero conta: la logica applicativa, la qualità dello schema, e l’esperienza di chi quei dati li consuma.
Autenticazione, sicurezza e real-time: GraphQL che conosce i suoi utenti
In un mondo perfetto, ogni richiesta GraphQL avrebbe un solo scopo: ottenere o modificare dati.
Nel mondo reale, invece, le query arrivano da utenti diversi, ruoli diversi, sistemi diversi — e non tutto è accessibile a tutti.
Per questo AWS AppSync integra la sicurezza e l’autenticazione nel cuore stesso del servizio.
Non come un filtro esterno, ma come parte del modello GraphQL: ogni campo, ogni operazione, ogni subscription può essere protetta con regole granulari, dichiarate direttamente nello schema.
Autenticazione multipla: più identità, un solo schema
AppSync supporta più provider di autenticazione contemporaneamente, e questo è uno dei suoi punti di forza.
Puoi permettere a un’app mobile di autenticarsi con Amazon Cognito User Pools, far parlare un microservizio interno tramite IAM, e aprire l’API a un partner esterno con OIDC o API key — tutto nello stesso endpoint GraphQL.
Ogni tipo di autenticazione può essere associato a operazioni diverse nello schema.
Esempio:
- un utente autenticato tramite Cognito può eseguire query e mutation sul proprio profilo (
@aws_cognito_user_pools) - un servizio interno, autenticato via IAM, può invocare mutation di sistema (
@aws_iam) - un partner esterno può accedere solo a un sottoinsieme pubblico di dati (
@aws_api_key)
Questa flessibilità permette di modellare scenari complessi senza moltiplicare gli endpoint o mantenere gateway separati.
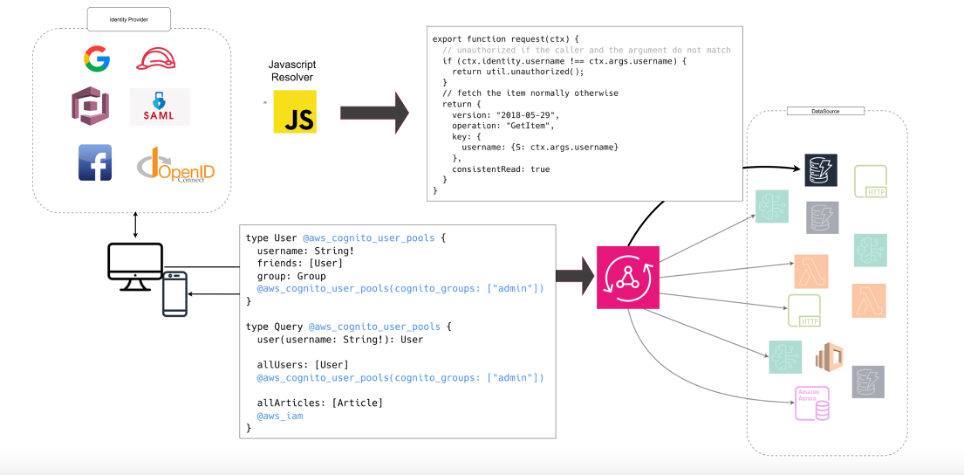
Nota tecnica: le direttive di autorizzazione (@aws_cognito_user_pools, @aws_iam, @aws_oidc, @aws_api_key) vengono interpretate da AppSync durante la risoluzione della query, prima ancora di invocare i resolver.
In questo modo, i controlli di accesso avvengono a livello di schema, non a posteriori.
type User @aws_cognito_user_pools {
username: String!
friends: [User]
group: Group
@aws_cognito_user_pools(cognito_groups: ["admin"])
}
type Query @aws_cognito_user_pools {
user(username: String!): User
allUsers: [User]
@aws_cognito_user_pools(cognito_groups: ["admin"])
allArticles: [Article]
@aws_iam
}
Ruoli, gruppi e multi-tenant
AppSync si integra nativamente con Amazon Cognito, quindi puoi sfruttare gruppi, ruoli e custom attributes per creare logiche di multi-tenant o di accesso basato su ruolo (RBAC).
Ad esempio, puoi aggiungere un attributo tenantId o role al token dell’utente, e usarlo nei resolver per filtrare automaticamente i dati pertinenti.
Questo approccio è particolarmente efficace per applicazioni SaaS multi-tenant:
ogni utente vede solo i propri dati, senza dover mantenere database separati o logiche di filtraggio personalizzate in Lambda.
Sicurezza come parte del contratto
Il bello del modello GraphQL in AppSync è che la sicurezza non è più una serie di regole sparse tra gateway, middleware e funzioni:
è dichiarativa.
Vive nello schema, vicino ai tipi e alle operazioni che protegge.
Questo riduce gli errori, rende le policy leggibili e mantiene allineato il comportamento tra client e server.
In altre parole, lo schema non definisce solo “cosa si può chiedere”, ma anche “chi può chiederlo”.
Mettendo tutto insieme
Subscription: real-time gestito, senza codice
Un’altra delle complessità classiche di GraphQL self-hosted è la gestione del real-time.
Le subscription esistono nello standard GraphQL, ma la specifica non dice come debbano essere trasportate o mantenute: WebSocket, Server-Sent Events, polling — ogni implementazione deve inventarsi la propria soluzione.
AppSync, invece, lo fa per te.
Offre un’infrastruttura WebSocket completamente gestita, che gestisce automaticamente connessioni, filtri e distribuzione degli eventi in base alle regole definite nello schema.
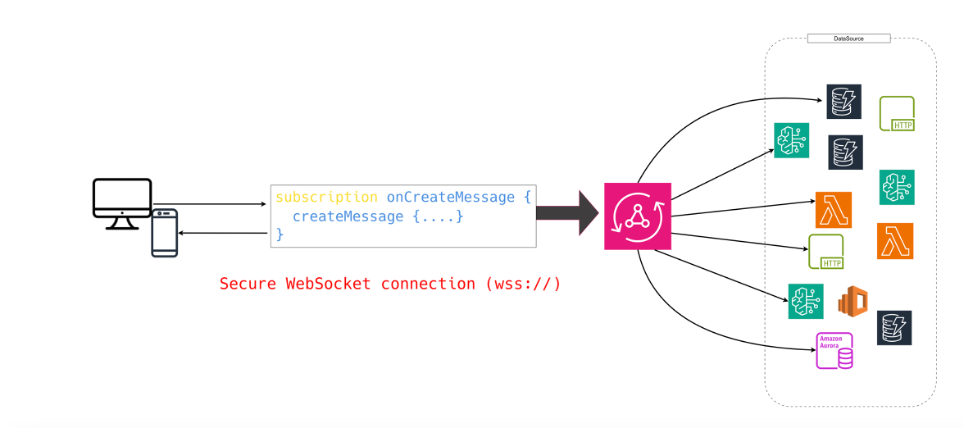
Il meccanismo è semplice ma potente:
- definisci una subscription legata a una o più mutation (es.
onNewPostche si attiva sucreatePost) - il client si iscrive tramite lo stesso endpoint GraphQL
- AppSync tiene viva la connessione e recapita solo gli eventi pertinenti, in modo sicuro e filtrato
Un layer di fiducia unico
Combinando sicurezza, autenticazione e real-time, AppSync diventa non solo un motore GraphQL, ma un piano di fiducia centralizzato.
Ogni query è autenticata, ogni campo può essere protetto, ogni evento viene consegnato solo a chi ne ha diritto.
E tutto questo avviene prima che il tuo codice applicativo entri in gioco.
È un modello in cui la sicurezza non è un’aggiunta, ma una caratteristica strutturale.
Un’architettura che ti permette di concentrarti sulla logica di business, sapendo che identità, accesso e comunicazione in tempo reale sono già parte integrante della piattaforma.
Affidabilità, caching e scalabilità: GraphQL che non trema sotto carico
Ogni architettura che cresce, prima o poi, si scontra con la realtà: le prestazioni.
Più utenti, più query, più dati, e improvvisamente quello che funzionava bene in laboratorio comincia a diventare lento, costoso o fragile.
Con le implementazioni tradizionali di GraphQL, questi problemi si traducono spesso in server saturi, logiche di caching complesse o colli di bottiglia sui data source.
AppSync nasce proprio per evitare tutto questo.
Essendo un servizio completamente gestito, eredita la scalabilità, l’affidabilità e le ottimizzazioni dell’infrastruttura AWS, ma le estende con una serie di funzionalità che rendono GraphQL nativamente performante.
Caching: velocità su misura, non copia dei dati
Una delle caratteristiche più intelligenti di AppSync è il caching per resolver.
Invece di tenere una cache globale dell’intera query (che rischia di invalidarsi troppo spesso), AppSync permette di definire cache per singolo campo o operazione.
Questo approccio granulare offre due vantaggi enormi:
- Maggiore controllo: puoi scegliere esattamente cosa mettere in cache e per quanto tempo.
- Hit ratio altissima: i dati più richiesti — come liste statiche, lookup o risultati condivisi — vengono serviti direttamente dalla cache, riducendo fino al 90–99% le chiamate ai data source.
Ogni nodo di cache è completamente gestito (basato su tecnologia simile a Redis) e configurabile in pochi clic o via CloudFormation.
Il caching può anche essere invalidato automaticamente in risposta a mutation, mantenendo la coerenza dei dati senza codice aggiuntivo.
Esempio tipico: in un’app di e-commerce, i resolver che leggono categorie, metadati di prodotto o valute sono perfetti candidati per il caching per-resolver.
In questo modo riduci il carico su DynamoDB o API esterne senza sacrificare la freschezza dei dati.
Batch invoke e riduzione del fan-out
Un altro elemento chiave per le performance è la gestione delle chiamate multiple.
Nei grafi complessi, una query può richiedere centinaia di piccoli resolver, ciascuno dei quali invoca una funzione Lambda o una tabella DynamoDB.
Per evitare il cosiddetto “resolver explosion”, AppSync supporta il batch invoke: un meccanismo che consente di raggruppare più risoluzioni in un’unica chiamata.
In questo modo riduci il numero di round-trip, il tempo di elaborazione e i costi di invocazione Lambda.
È una forma di intelligenza operativa che si attiva dietro le quinte e permette di mantenere le performance costanti anche quando le query diventano sempre più articolate.
Scalabilità automatica: niente più provisioning
Con AppSync non esistono server da dimensionare.
Il servizio scala automaticamente per gestire migliaia di query al secondo senza dover configurare nulla.
Le risorse sottostanti — come DynamoDB, Lambda o HTTP endpoint — seguono lo stesso principio di scalabilità elastica tipico di AWS.
E per le applicazioni ad altissimo traffico, puoi richiedere l’aumento delle quote di throughput tramite Service Quotas o support AWS.
Questo consente di mantenere la stessa architettura anche in presenza di picchi improvvisi, come il lancio di un prodotto o un evento globale.
In pratica: AppSync scala verticalmente e orizzontalmente senza downtime.
Se aumentano le connessioni o il numero di query simultanee, la piattaforma adatta automaticamente le risorse necessarie, mantenendo la latenza sotto controllo.
Affidabilità e resilienza intrinseche
Tutto in AppSync è costruito per essere fault-tolerant.
Ogni componente — dal caching ai resolver, fino alle connessioni WebSocket — è replicato e gestito in più Availability Zone.
In caso di errore, il traffico viene automaticamente reindirizzato, senza impatti sull’API o sull’esperienza utente.
Inoltre, il servizio è stateless, il che significa che non conserva stato applicativo tra richieste: ogni invocazione è indipendente, riducendo il rischio di “cascate di errori” tipiche dei server GraphQL auto-ospitati.
Perché questo modello è più efficiente di un GraphQL self-hosted
In un’implementazione tradizionale, mantenere un server GraphQL ad alte prestazioni richiede:
- scalare manualmente le istanze
- introdurre layer di caching personalizzati
- gestire pool di connessioni e bilanciamento
- scrivere codice per mitigare la latenza tra data source
AppSync fa tutto questo per te, in modo nativo e trasparente.
Non è un “proxy”, ma un motore di orchestrazione distribuito: gestisce il flusso di dati tra client e sorgenti con caching integrato, batch intelligente e scalabilità automatica.
Il risultato è un backend che rimane snello e prevedibile anche sotto carichi intensi, senza compromessi sulla sicurezza o sull’affidabilità.
Observability e troubleshooting: vedere dentro il grafo
Più un sistema diventa intelligente, più serve visibilità per capirlo.
In GraphQL questo è ancora più vero: dietro una singola query possono nascondersi decine di chiamate interne, passaggi di pipeline, funzioni Lambda e accessi a database.
Quando qualcosa rallenta o si rompe, non basta sapere “che la query ha fallito”: serve sapere dove, perché e quanto ha impattato.
Per questo AppSync integra strumenti di observability di livello enterprise, che permettono di seguire ogni richiesta dal momento in cui entra nel sistema fino alla risposta finale.
Senza dover installare agent, log server o tracing custom.
Logging dettagliato: CloudWatch come finestra sul grafo
Il primo strumento da conoscere è AWS CloudWatch, il punto di raccolta di tutti i log operativi di AppSync.
Puoi configurare il livello di dettaglio in base alle esigenze:
- Errore – registra solo le chiamate fallite.
- Tutto – include anche le query riuscite, con tempi di risposta e contesto.
- Verbose – cattura anche il contenuto delle richieste e risposte, i mapping template (VTL/JS), e il context passato tra i resolver.
Attivare la modalità verbose è come accendere la luce in un laboratorio:
vedi esattamente quali campi vengono richiesti, quali resolver vengono invocati, e come si trasformano i dati lungo la pipeline.
È lo strumento perfetto per capire dove una query consuma tempo o dove un template restituisce valori errati.
Nota di esperienza: la modalità verbose va usata con criterio — è preziosa in fase di test e debugging, ma può generare log voluminosi (e quindi costi maggiori) in ambienti di produzione.
Tracing distribuito con AWS X-Ray
Quando vuoi andare oltre il semplice logging e visualizzare l’intero flusso di esecuzione di una query, entra in gioco AWS X-Ray.
AppSync può essere configurato con xrayEnabled: true, e automaticamente ogni richiesta GraphQL genera un trace che mostra la catena di chiamate tra AppSync, i data source (DynamoDB, Lambda, HTTP) e le eventuali funzioni secondarie.
Il risultato è una service map interattiva:
ogni nodo rappresenta un servizio, ogni arco una chiamata, e ogni colore una misura di latenza o errore.
Puoi individuare in pochi secondi dove la query impiega più tempo, quali resolver sono più costosi o dove si verificano errori interni.
E se i tuoi resolver richiamano funzioni Lambda, puoi estendere il tracing anche lì, usando l’SDK X-Ray dentro la funzione.
In questo modo ottieni un quadro end-to-end del flusso: dal client GraphQL fino al singolo database o microservizio.
Suggerimento pratico: per Lambda complesse o architetture con molti microservizi, considera l’integrazione con strumenti come Lumigo, Datadog o New Relic. Offrono interfacce più intuitive per il tracing e l’alerting rispetto a X-Ray, mantenendo compatibilità con i dati raccolti da AppSync.
Metriche e allarmi
Oltre ai log e ai trace, AppSync esporta una serie di metriche quantitative in CloudWatch, come:
- numero di richieste GraphQL al secondo
- tempo medio di risposta
- errori di autorizzazione
- numero di subscription attive
- cache hit/miss ratio
Puoi costruire dashboard personalizzate o configurare allarmi automatici (CloudWatch Alarms) per essere avvisato se la latenza cresce o la cache smette di funzionare correttamente.
Questo ti permette di reagire prima che i problemi diventino visibili agli utenti.
Debugging mirato: dal resolver al campo
Un vantaggio unico del modello GraphQL in AppSync è la tracciabilità per campo.
Ogni resolver, essendo associato a un campo specifico, produce log e metriche autonomi.
Questo significa che puoi analizzare la performance di un singolo campo — ad esempio, user.posts.comments — e capire se il problema è in quel punto, senza dover setacciare l’intera API.
È un livello di visibilità che difficilmente trovi nelle architetture REST tradizionali, dove i problemi si perdono tra endpoint e microservizi.
Come costruire un ciclo di observability efficace
Un setup tipico in produzione include:
- CloudWatch Logs – per raccogliere e analizzare gli eventi di ogni query.
- X-Ray – per il tracing end-to-end tra servizi.
- CloudWatch Metrics + Alarms – per monitorare trend e soglie operative.
- (Facoltativo) Strumenti esterni – per alerting, cost analysis o correlazione tra team.
Con questi strumenti integrati, AppSync diventa un sistema trasparente e governabile: sai cosa succede, quando succede e perché.
L’osservabilità come parte del design
In AppSync, l’osservabilità non è un’aggiunta postuma: è una caratteristica di piattaforma.
Ogni query, resolver e subscription è osservabile nativamente, e i dati raccolti vengono centralizzati senza dover costruire infrastrutture dedicate.
Questo libera tempo e risorse: meno tempo a configurare logging, più tempo a migliorare l’esperienza utente.
In un mondo dove i dati viaggiano tra decine di servizi e componenti serverless, poter “vedere dentro il grafo” è ciò che trasforma un’architettura da potente a affidabile.
Testing e qualità: come si verifica un grafo che vive
In GraphQL, testare non significa solo assicurarsi che “l’API risponda”, ma che l’intero flusso — dallo schema fino ai resolver e ai data source — si comporti in modo coerente.
Ogni campo è un piccolo pezzo di logica, ogni mutation può scatenare catene di eventi, e le subscription tengono in vita connessioni real-time.
È un ecosistema, non una semplice API.
AWS AppSync, pur essendo un servizio completamente gestito, non elimina la necessità di test: la sposta più in alto, verso la validazione del comportamento del grafo.
Vediamo come.
Unit test: il livello più sottile
A livello più basso ci sono i test sui mapping template (VTL o JavaScript resolver).
Questi file trasformano la richiesta GraphQL in una chiamata verso il data source e la risposta in un formato compatibile con lo schema.
Scrivere unit test su questi template ha senso solo per i casi più complessi — ad esempio, quando il resolver esegue trasformazioni o filtri personalizzati.
AWS Amplify mette a disposizione strumenti come amplify-velocity-template e amplify-appsync-simulator, che permettono di eseguire i template localmente con input e output simulati.
In pratica, è come testare le “traduzioni” tra GraphQL e il backend, verificando che il mapping faccia esattamente ciò che ti aspetti.
Integration test: dove si trova il vero valore
La parte più importante del testing in AppSync è quella integrata: testare i resolver reali contro data source veri (DynamoDB, Lambda, HTTP).
Qui non serve mockare: serve esercitare il sistema per davvero.
Esegui una query GraphQL, passa token di autenticazione Cognito o IAM reali, e verifica che il risultato coincida con lo stato dei dati nel backend.
Questi test intercettano:
- errori di autorizzazione (policy IAM mancanti o errate)
- shape dei dati non coerenti tra resolver
- dipendenze non configurate correttamente
È qui che si scoprono il 90% dei problemi reali, quelli che in sviluppo locale non si vedono mai.
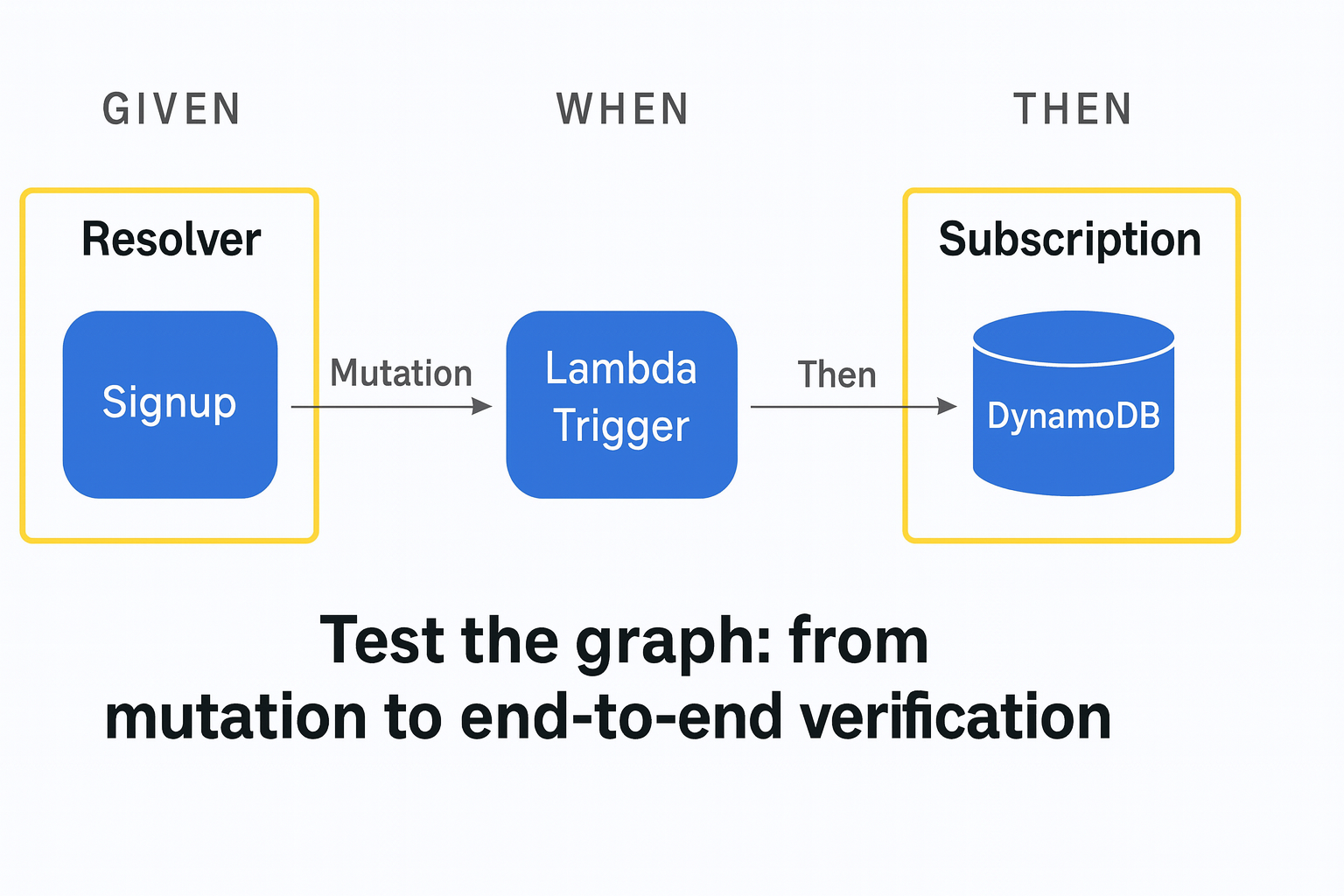
Esempio concreto:
un test che crea un utente con mutation CreateUser, attende il trigger Cognito PostConfirmation (Lambda), e poi verifica che il record sia stato scritto in DynamoDB e che la query getUser lo restituisca correttamente.
Questo è un test end-to-end vero di un flusso AppSync.
End-to-End (E2E): testare il grafo dal punto di vista del client
Il passo successivo è il test end-to-end, che replica l’esperienza del client:
autenticazione, query, mutation, subscription, risposta.
Puoi farlo con strumenti come Postman, GraphQL Playground, o test framework come Cypress, Playwright o Jest (via client GraphQL).
Ogni test parte da una vera autenticazione Cognito, invia richieste all’endpoint AppSync e valida la risposta attesa.
È il modo più diretto per assicurarti che l’intera catena — sicurezza, schema, risoluzione e data source — funzioni come previsto.
E quando usi subscription real-time, puoi testare anche la ricezione degli eventi tramite WebSocket gestiti, verificando che solo gli utenti autorizzati ricevano gli update.
Mock e local simulation: l’ambiente sicuro per sperimentare
AppSync offre anche modalità di simulazione locale grazie ad AWS Amplify.
Puoi lanciare un server AppSync “in miniatura” su cui testare query, resolver e pipeline senza dover deployare tutto su AWS.
È utile nelle fasi iniziali di sviluppo o per verificare modifiche allo schema e ai template prima di promuoverli in ambienti condivisi.
Un vantaggio spesso sottovalutato: questo approccio riduce i costi di test e accelera il ciclo di feedback, soprattutto in team agili.
Testing come disciplina continua
In un ambiente serverless come AppSync, il testing non è una fase, ma una disciplina continua.
Ogni modifica allo schema, ai resolver o ai data source può cambiare il comportamento del grafo.
Per questo è buona pratica automatizzare la validazione con pipeline CI/CD:
- deploy di test temporaneo
- esecuzione dei test GraphQL
- verifica automatica di performance e sicurezza
- solo dopo, promozione in produzione
È un modo per trattare lo schema come codice vivente: evolutivo, tracciabile, testato.
Il risultato: un grafo affidabile nel tempo
Un’API GraphQL ben testata non è solo “funzionante”: è prevedibile.
Ogni campo fa ciò che promette, ogni mutation mantiene la coerenza, e ogni subscription rispetta i filtri e i ruoli definiti.
In un contesto come AppSync, questo significa API stabili, sicure e manutenibili anche su larga scala.
E quando qualcosa cambia — un nuovo campo, una logica diversa, un resolver aggiornato — i test diventano la rete di sicurezza che ti consente di evolvere senza paura.
Conclusione: GraphQL e AppSync, l’equilibrio tra controllo e libertà
Ogni rivoluzione tecnologica inizia con una domanda semplice:
E se ci fosse un modo più naturale di parlare con i nostri dati?
REST ha risposto a quella domanda vent’anni fa, portando ordine dove c’era caos.
Ma oggi, in un mondo di app complesse, esperienze interattive e sistemi distribuiti, il linguaggio dei dati aveva bisogno di evolvere ancora.
GraphQL è quella nuova lingua: più espressiva, più coerente, più vicina a come pensiamo le informazioni.
E AWS AppSync ne è il traduttore perfetto.
Un servizio che prende i principi di GraphQL — schema, resolver, sicurezza, real-time — e li trasforma in una piattaforma completamente gestita, affidabile e pronta a scalare con te.
Con AppSync:
- lo schema diventa la singola fonte di verità del tuo dominio
- i resolver orchestrano i dati tra sorgenti eterogenee
- la sicurezza vive dentro il grafo, non ai margini
- il real-time è integrato, non un add-on
- il caching e lo scaling sono automatici
- l’observability ti permette di vedere tutto ciò che accade, campo per campo
È un modo diverso di pensare le API: non più una collezione di endpoint, ma un sistema vivente che cresce insieme alla tua applicazione.
Da REST a GraphQL, con un approccio graduale
Passare a GraphQL non significa buttare via ciò che esiste.
Significa iniziare a dare forma ai dati nel modo in cui il frontend li consuma davvero.
Puoi cominciare piano:
- Metti AppSync davanti alle tue API REST esistenti, usando resolver HTTP.
- Sposta gradualmente la logica nei pipeline resolver, per comporre dati da più fonti.
- Aggiungi autenticazione Cognito e caching per ottimizzare performance e sicurezza.
- Abilita subscription dove il real-time porta valore reale.
Un passo alla volta, senza forzature.
Fino a ritrovarti con un backend più pulito, osservabile, scalabile e “vicino” ai bisogni del client.
Un equilibrio raro
La vera forza di AppSync non è solo tecnica, ma filosofica:
porta equilibrio tra due mondi che spesso si contrappongono — il controllo e la libertà.
Ti lascia la libertà di modellare il grafo e i dati come vuoi, ma ti solleva dal controllo dell’infrastruttura, delle connessioni, delle istanze, dei log.
È il compromesso ideale tra potenza e semplicità.
Non un framework, non un prodotto “chiuso”, ma un modo nuovo di progettare servizi: dichiarativo, trasparente e scalabile per natura.
L’ultimo miglio
In fondo, scegliere GraphQL e AppSync non è una scelta di strumenti, ma di mentalità.
È passare da un mondo di “endpoint” a un mondo di “relazioni”.
Da API che restituiscono dati a sistemi che esprimono conoscenza.
Da server che rispondono a servizi che collaborano.
E quando vedi una query GraphQL scritta bene — chiara, precisa, leggibile quasi come un pensiero — capisci che non è solo una tecnologia:
è una nuova grammatica per il linguaggio dei dati.
AppSync ti permette di parlarla senza doverla costruire da zero, con la sicurezza e l’efficienza di chi ha già risolto la parte più difficile: far dialogare tutto il resto.
Epilogo
In ogni riga di codice GraphQL c’è l’idea di un mondo più coerente, dove client e server parlano la stessa lingua.
E in ogni riga di configurazione AppSync, c’è la promessa che quella lingua possa scalare, vivere e crescere — senza mai diventare un peso.
Non serve adottarlo tutto e subito.
Serve cominciare, con una query, uno schema e un piccolo grafo.
Il resto — come in ogni buona architettura — verrà da sé.