Architetture Serverless su AWS: cosa sono e perché usarle?



Nel mondo dell’IT, tutto nasce da un’esigenza ed ogni cosa ha uno scopo. Esistono pro e contro per ogni soluzione: la cosa migliore è conoscerli entrambi e, in base a questi, scegliere la soluzione che si adatta di più alle proprie esigenze.
Immaginiamo di essere una giovane startup, appena creata, quindi con tutti i dubbi sul futuro: non sapere se la propria idea possa portare a qualcosa, ma comunque voler osare per dire la sua nel mondo di oggi.
Naturalmente, una delle prime cose a cui pensa chi si trova a voler aprire una startup sono i costi. Ovvero: voglio investire nella mia idea, ma fino a quanto mi posso spingere se non mi è garantito un ritorno economico?
In questo caso, l’adozione di un’architettura serverless su AWS può essere una soluzione che ha i suoi pro e i suoi contro. Però, prima di rispondere a questo, dobbiamo domandarci: che cos’è il cloud? E che cos’è AWS?
Che cos’è il cloud
Modello di erogazione di risorse IT (server, storage, database, reti, software) via Internet, a consumo, scalabili e gestite da un provider.
Pro del cloud
Scalabilità elastica: risorse su/giù in pochi minuti.
- Pay-as-you-go: paghi ciò che usi.
- Time-to-market rapido: servizi pronti all’uso.
- Affidabilità: alta disponibilità e DR integrabili.
- Gestione semplificata: meno hardware da mantenere.
Contro del cloud
- Costo variabile: rischi di spesa se non controlli l’uso.
- Dipendenza dal provider (lock-in).
- Latenza/compliance: vincoli di dati/paese e prestazioni.
- Visibilità limitata sull’infrastruttura fisica.
Che cos’è AWS
Amazon Web Services: piattaforma cloud di Amazon con servizi IaaS/PaaS/SaaS (compute, storage, database, AI, rete, sicurezza) disponibile globalmente.
Pro di AWS
- Ampiezza di servizi (compute, data, ML, IoT, serverless) e integrazioni mature.
- Copertura globale con molte regioni/zone.
- Ecosistema e supporto: documentazione, community, marketplace.
- Affidabilità e sicurezza con standard e certificazioni diffuse.
- Strumenti FinOps/ops (tagging, Cost Explorer, CloudWatch) ben integrati.
Contro di AWS
- Curva di apprendimento ripida (molti servizi e opzioni).
- Pricing complesso; stime e ottimizzazioni non banali.
- Lock-in su servizi gestiti/proprietari (es. Lambda, DynamoDB).
Una startup che passa al cloud ha una marcia in più, perché il cloud si prende in carico molti aspetti che prima dovevano essere gestiti manualmente da persone specializzate, oltre ai costi di infrastruttura (manutenzione dei server, elettricità, raffreddamento, ecc.).
Quindi, per una startup che non ha ben chiaro quali saranno i propri guadagni, l’adozione del cloud permette una gestione più semplice dell’infrastruttura (in quanto il cloud la gestisce per lei) e di avere meno figure operative che se ne occupano. E questo, se gestito bene, può portare a una riduzione di quei costi fissi che, per una startup appena creata, non sono l’ideale, dato che non si sa come il business possa evolversi.
Sembra tutto fantastico, però – come ogni cosa – ha i propri pro e contro. Analizziamo bene cosa significa serverless e come può portare un valore aggiunto.
Che cos’è un’architettura serverless?
Innanzitutto, come spesso ci si confonde, serverless non significa “senza server”: non è magia, il codice dovrà girare sempre da qualche parte; la cosa interessante e potente è che tu non sai né dove né su quale macchina, e sai che sarà in esecuzione solo quando viene chiamato.
Questo comporta grandissimi vantaggi:
- Non gestisco io l’infrastruttura, non la manutengo e quindi sarà il cloud a preoccuparsi di garantirmi che, quando chiamo il mio codice, questo venga sempre eseguito.
- Non ho costi fissi, perché paghi solo per l’esecuzione e l’invocazione del codice. È diverso dall’avere server online 24 ore su 24 anche quando magari nessuno sta usando l’applicazione. E, per una startup, non avere costi fissi quando non si ha la certezza dei ricavi è una marcia in più.
AWS e i servizi serverless che offre
AWS offre centinaia di servizi serverless e si possono creare applicazioni scalabili e avanzate con essi, ma per un’infrastruttura di base ne bastano solo tre (API Gateway, Lambda e DynamoDB).
Che cos’è una Lambda?
AWS Lambda implementa il modello cloud “Function as a Service”: scrivo funzioni, definisco i trigger e AWS le esegue on demand, scalando automaticamente e senza gestire server.
AWS Lambda è il servizio serverless di AWS che esegue il tuo codice in risposta a eventi (es. richieste API, messaggi da code/stream, upload su S3, cron) senza dover gestire server. Tu carichi una function (es. in Node.js, Python, Java, Go, .NET, Ruby), imposti memoria/timeout/trigger e Lambda la avvia su richiesta, scalando automaticamente. La Lambda può essere scritta in vari linguaggi di programmazione, ed ogni Lambda può essere scritta in un linguaggio diverso: è quindi possibile usare il linguaggio più adatto in base al caso d’uso e a ciò che fa quella singola funzione.
Come si paga: a consumo, in base al numero di invocazioni e alla durata/risorse usate (GB-secondi).
Punti chiave: scaling automatico, integrazione stretta con servizi AWS (API Gateway, SQS, EventBridge, DynamoDB, S3), versioni/alias, variabili d’ambiente, IAM, livelli (layers) ed estensioni.
Limiti/attenzioni: cold start (ritardo alla prima esecuzione), timeout massimo per invocazione, file system effimero (/tmp), e lock-in su modelli/eventi AWS.
Che cos’è il cold start time?
Ricordate quando si è detto che la Lambda è un pezzo di codice eseguito on demand da qualche parte? Il cold start time è il tempo che la Lambda impiega per “svegliarsi”, cioè caricare tutti i contesti prima di eseguire il codice in essa contenuto.
Abbiamo quindi il vantaggio di eseguire un pezzo di codice quando vogliamo senza dover necessariamente avere una macchina accesa in attesa che qualcuno la utilizzi; d’altra parte, la prima volta che viene chiamata impiegherà un po’ per avviarsi.
Che cos’è un API Gateway?
È un servizio gestito per creare, pubblicare, proteggere e monitorare API HTTP/REST/WebSocket che fanno da “porta d’ingresso” a backend come AWS Lambda, servizi in VPC, EC2 o altri endpoint.
Punti chiave
- Autenticazione/autorizzazione: IAM, Cognito, Lambda authorizer.
- Throttling, rate limiting, caching opzionale, trasformazioni request/response, stages e deployment.
- Custom domain, usage plans/keys, logging/metriche con CloudWatch, integrazione con WAF; supporto Private API e VLink.
- Costo: pay-per-request (+ eventuale cache oraria e transfer).
Pro/Contro (in breve)
- Serverless e scalabile, feature ricche, sicurezza integrata.
Configurazione complessa per casi avanzati; latenza/costi possono crescere ad alto throughput (valutare ALB o CloudFront in alcuni scenari).
Che cos’è Amazon DynamoDB
È un database NoSQL key-value/document completamente gestito, con latenza a singola cifra di millisecondo, scalabile e altamente disponibile (multi-AZ), pensato per carichi variabili e massivi.
Punti chiave
- Modello dati: partizione (hash key) + opzionale sort key; GSI/LSI per query alternative.
- Modalità capacità: on demand (a richiesta) o provisioned con auto scaling.
- Streams (eventi di cambiamento), TTL, transazioni, backup/restore, Global Tables (multi-regione), DAX (cache in-memory).
- Costo: in base a richieste (RCU/WCU o on demand), storage, stream/backup/replica.
Pro/Contro (in breve)
- Scalabilità “infinita”, prestazioni prevedibili, zero gestione server/patch, HA nativa.
- Richiede data modeling per pattern di accesso (denormalizzazione); niente join/query ad hoc complesse; item ≤ 400 KB; attenzione a “hot partition” e ai costi di scan.
Anche in questo caso è uno strumento molto potente, ma per ottenere i vantaggi massimi bisogna strutturare i dati in modo appropriato, così da ottenere benefici sia economici sia di scalabilità.
Vediamo un esempio di architettura dove tutti e tre servizi coesistono
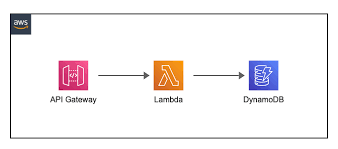
-
Client → API Gateway
Un’app o un browser fa una richiesta HTTP/HTTPS (es.POST /orders).
API Gateway è la "porta d’ingresso": controlla l’autenticazione (IAM/Cognito/authorizer), applica rate limiting e valida il payload. -
API Gateway → Lambda
Se tutto ok, API Gateway invoca la funzione Lambda passando la richiesta (metodo, path, header, body).
Qui non gestisci server: Lambda si avvia, anche in parallelo, e scala da sola. -
Dentro Lambda (logica applicativa)
La funzione:
- legge il body (es. JSON),
- fa validazioni/regole di business,
- prepara l’operazione per il DB (chiave di partizione, attributi, ecc.).
-
Lambda → DynamoDB
Con l’SDK AWS, la funzione esegue operazioni su DynamoDB (PutItem,GetItem,UpdateItem,Query…).
L’execution role di Lambda deve avere i permessi minimi necessari sulle tabelle. -
DynamoDB risponde a Lambda
DynamoDB conferma l’esito (ok, condizione fallita, item non trovato, ecc.).
La funzione gestisce eventuali errori (retry logico, idempotenza, mapping dei messaggi). -
Lambda → API Gateway → Client
Lambda costruisce la response (status code + body).
API Gateway la inoltra al client (eventuali trasformazioni/header).
Serverless (Pro/Contro)

Conclusione
Il serverless è un paradigma molto valido per evitare di imbattersi in costi fissi. Però, come in ogni caso, va studiato e usato bene in base al proprio bisogno: non è la bacchetta magica che risolve ogni tipo di problema. Bisogna saperlo usare poiché, essendo molto potente, non è di facile configurazione e, in caso di configurazione errata, è possibile imbattersi in costi alti e inattesi. È l’ideale per evitare costi fissi e gestire carichi imprevedibili, ma si paga a consumo: prima di adottarlo bisogna fare un’analisi approfondita del proprio business e capire di cosa si ha bisogno e cosa ci si aspetta.