LLM e Pesi: una breve descrizione
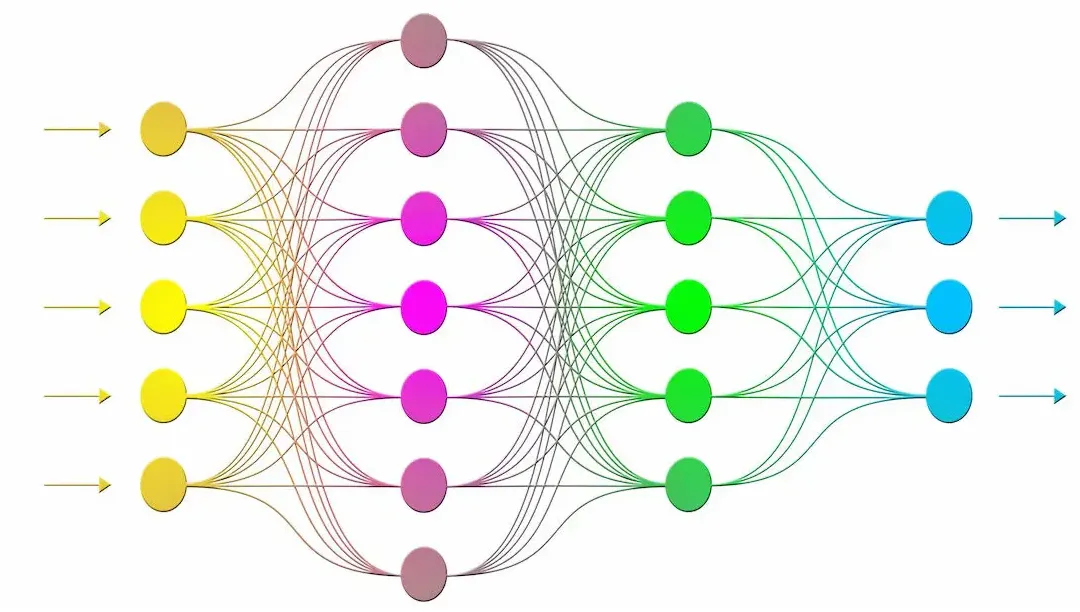
I modelli LLM sono reti neurali che stanno rivoluzionando il modo in cui le macchine comprendono e generano il linguaggio naturale. Un elemento chiave di questi modelli sono i “pesi” e la loro disponibilità nei modelli “open-source”
Le reti neurali sono estremamente grandi e costituite da numerosi livelli ognuno con numeri nodi. Ogni nodo di un livello è connesso a tutti i nodi del livello successivo, ogni connessione ha un peso che è un parametro numerico che determina la forza della connessione. Questi pesi vengono ricavati ed ottimizzati durante l’addestramento del modello in base alle prestazioni che si vogliono ottenere.
Le reti neurali, in particolare gli LLM basate su trasformatori, possono contenere miliardi di parametri. Un piccolo elenco sicuramente non esaustivo:
| Modello | Architettura | Parametri | Altre informazioni |
|---|---|---|---|
| LLaMA 3 | Transformer | 8B e 70B | Addestrato su 15 trilioni di token, supporto multilingue, ottimizzato per codifica e generazione creativa |
| GPT-NeoX | Transformer | fino a 20B | Progetto di EleutherAI, addestrato su Pile, un vasto dataset open source |
| BLOOM | Transformer | 176B | Creato da BigScience, supporta 46 lingue e 13 linguaggi di programmazione |
| T5 | Transformer | fino a 11B | Progetto di Google, ottimizzato per compiti di NLP come traduzione e riassunto |
| Mistral | MoE | fino a 12B | Utilizza un'architettura MoE per migliorare l'efficienza e la scalabilità |
| DeepSeek | MoE | fino a 671B | Modello avanzato con velocità di inferenza migliorata, supporta multilingue |
| Qwen | MoE e Dense | fino a 72B | Modelli di Alibaba Cloud, supportano multilingue e vari compiti di NLP |
| Gemma | Transformer | 2B e 7B | Modelli di Google DeepMind, basati sulla ricerca Gemini, disponibili in versioni base e istruzione-tuning |
| Phi | Transformer | 2.7B e 14B | Modelli di Microsoft, ottimizzati per compiti di ragionamento complesso e applicazioni avanzate |
I modelli rilasciati in modalità “open source” oltre a descrivere l’architettura ed altre informazioni sulle specificità del linguaggio rendono disponibili i pesi del modello che ne determinano il comportamento. In genere i modelli sono distribuiti fra GitHub, Hugging Face e Kaggle.
Come sono calcolati
Il modello LLM, ossia l’architettura della rete neurale ( per esempio Transformers), nodi e pesi, vengono addestrati utlizzando enormi quantità di dati molti dei quali disponibili in modaltà open-source, altri quelli sintentici spesso prodotti da altri modelli o da società specializzate altri ancora semplicemente tramite crawler da internet o altre modalità sempre più spesso non dichiarate per i modelli privati.
La valorizzazione dei pesi avviene in modalità iterativa fino a quando il token successivo e la sequenza precedente di token di input non soddisfano le esigenze. Questo processo avviene tramite diverse tecniche, tra cui l’ autoapprendimento, che insegnano al modello come regolare i parametri.
Come sono organizzati
Quando un modello viene pubblicato, i pesi vengono salvati in file speciali. Questi file permettono ad altri sviluppatori di usare il modello senza doverlo addestrare di nuovo ed adattarlo a compiti specifici (fine-tuning) perché i pesi iniziali sono già ben impostati a condizione che la struttura della rete sia compatibile, numero di nodi e la disposizione degli strati devono essere adatti ai pesi pre-addestrati. Ci sono comunque tecniche per adattare modelli leggermente diversi.
Questi valori numerici, regolati durante la fase di addestramento per minimizzare l’errore, sono organizzati in matrici e vettori.
Una matrice è una tabella di numeri disposti in righe e colonne. In una rete neurale, ogni strato ha una matrice di pesi che connette i neuroni di quello strato con quelli del successivo mentre.
Un vettore è una lista di numeri disposti in una singola colonna o riga. I vettori sono spesso utilizzati per rappresentare i pesi di un singolo neurone o i bias (valori aggiuntivi) in uno strato
Esempio di calcolo
Prendiamo in considerazione una rete neurale semplice denominata feedforward:
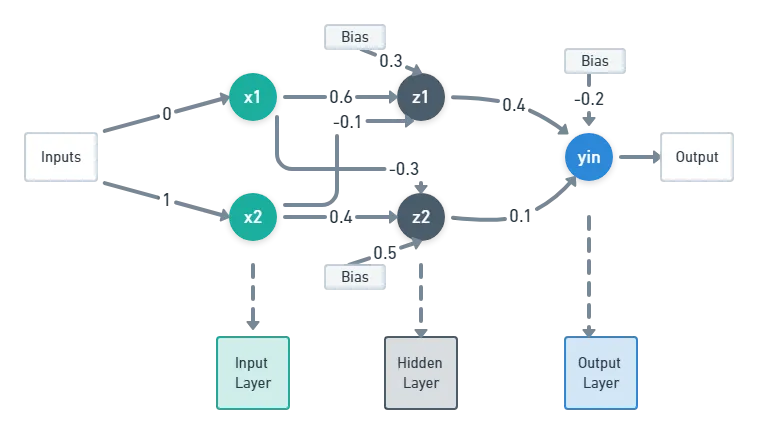
Questa rete molto semplice ha solo 3 strati:
- Strato di Input: Il Vettore di Input (x) rappresenta i dati iniziali che vengono inseriti nella rete.
- Strato Nascosto: La Matrice di Pesi (W_1) connette i neuroni dello strato di input con quelli dello strato nascosto ed il Vettore di Bias (b_1) aggiunge un valore costante ai neuroni dello strato nascosto per migliorare la flessibilità del modello.
- Strato di Output: La Matrice di Pesi (W_2) connette i neuroni dello strato nascosto con quelli dello strato di output ed il Vettore di Bias (b_2) aggiunge un valore costante ai neuroni dello strato di output.
Processo di Calcolo
Prima giusto due definizioni:
Prodotto Matriciale: Quando si moltiplicano due matrici, il simbolo (\cdot) indica il prodotto matriciale. Questo tipo di moltiplicazione combina le righe di una matrice con le colonne di un’altra matrice per produrre una nuova matrice.
Prodotto Vettoriale: Quando si moltiplica una matrice per un vettore, il simbolo (\cdot) indica il prodotto tra la matrice e il vettore. Questo prodotto combina le righe della matrice con gli elementi del vettore per produrre un nuovo vettore.
Le attività che compongono il calcolo:
- Calcolo nello Strato Nascosto: Prodotto vettoriale fra il vettore di input X con la matrice dei pesi W_1 + vettore dei bias b_1. Il risultato sarà un vettore di attivazioni “h”.
- Calcolo nello Strato di Output: Prodotto vettoriale fra il vettore h e la matrice dei pesi W_2 + vettore bias b_2. il risultato sarà il vettore di output “y” (nell’esempio costituito da un unico valore).

Conclusione
La pubblicazione dei pesi permette alla comunità scientifica di verificare i risultati, fare ulteriori studi e migliorare il modello. Inoltre, consente di confrontare diversi modelli su vari set di dati, stabilendo benchmark di prestazione e identificando le migliori pratiche.
In sintesi, pubblicare i pesi di un modello LLM aiuta la ricerca, l’innovazione tecnologica e la formazione nell’intelligenza artificiale, creando un ambiente più aperto e collaborativo.
Questo articolo è anche presente in https://mwzero.medium.com/llm-e-pesi-una-breve-descrizione-406ea9c26bf8
Seguimi su https://www.linkedin.com/in/farinamaurizio/.
L’articolo sopra è personale e non rappresenta necessariamente le posizioni, le strategie o le opinioni del mio datore di lavoro.