La nuova scarsità non sarà il codice, ma la capacità di portarlo in produzione

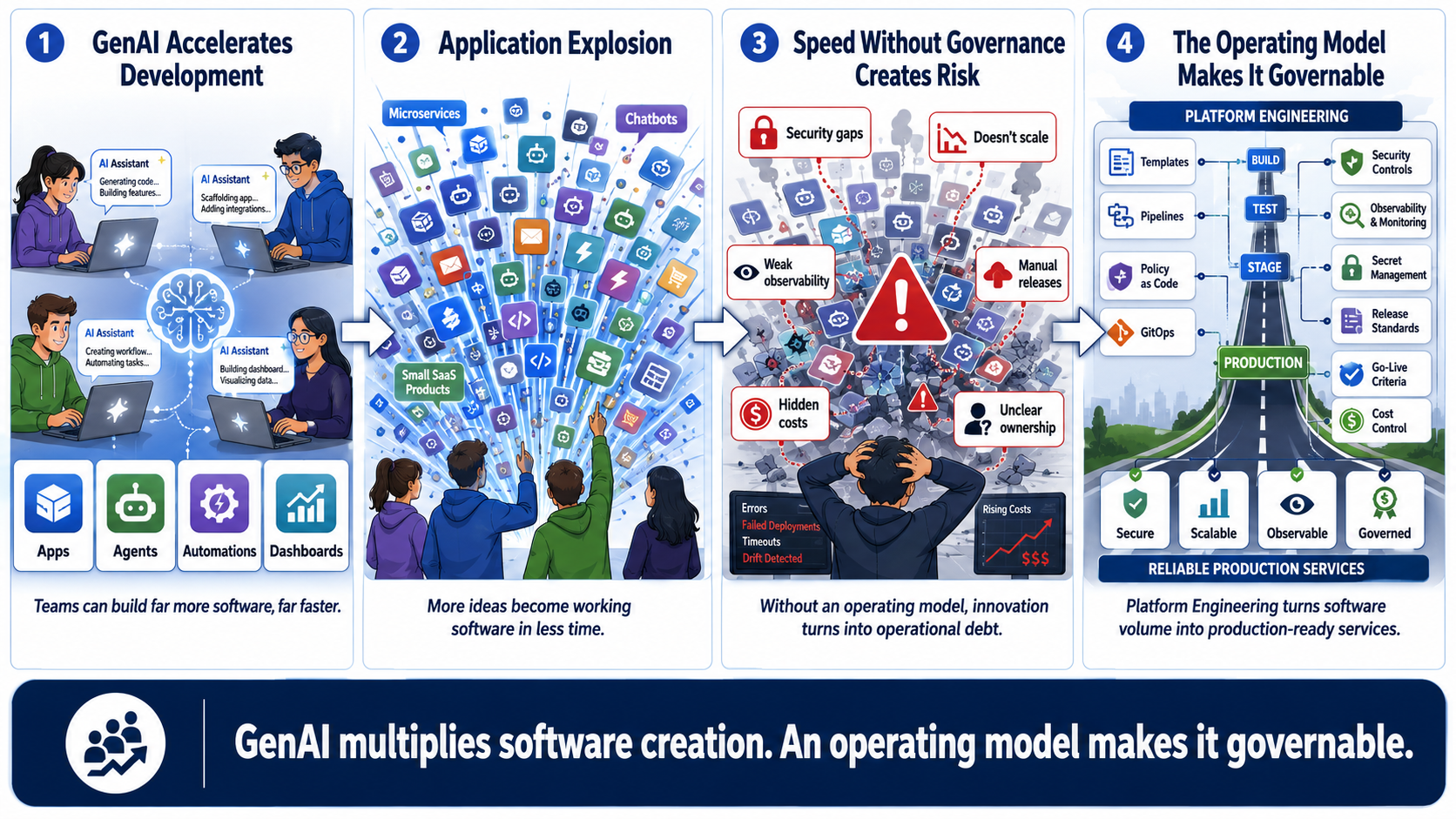
La GenAI sta cambiando il modo in cui costruiamo software.
Non perché abbia reso improvvisamente semplice tutto ciò che riguarda lo sviluppo applicativo. Questa sarebbe una lettura superficiale. Architettura, qualità del codice, sicurezza, conoscenza del dominio, capacità di revisione e consapevolezza tecnica restano competenze fondamentali.
Ma sarebbe altrettanto ingenuo negare l’evidenza opposta: una parte della barriera d’ingresso si è abbassata.
Oggi è più semplice generare una prima versione di un’applicazione, scrivere API, produrre interfacce, creare test, assemblare componenti, documentare codice, costruire automazioni e validare rapidamente un’idea.
Coding assistant, framework maturi, template, librerie e strumenti AI stanno aumentando la produttività dei team e rendendo più accessibile la fase di creazione.
Questo non elimina il mestiere dello sviluppo.
Lo sposta.
Perché quando diventa più facile creare software, il valore non sparisce. Si sposta verso ciò che resta difficile: portare quel software in produzione, renderlo sicuro, osservarlo, scalarlo, proteggerne i dati, governarne i costi, gestire ambienti e tenant, garantire continuità operativa e sapere chi interviene quando qualcosa non funziona.
La GenAI abbassa la barriera della creazione.
Ma alza la soglia minima della produzione.
E probabilmente una parte importante del valore, nei prossimi anni, si giocherà proprio qui.
Prototipo, prodotto, servizio
Nel software (come in qualunque altro campo) capita spesso di usare parole diverse come se indicassero la stessa cosa.
Prototipo, prodotto e servizio, per esempio, vengono spesso usati in modo intercambiabile. In realtà descrivono livelli molto diversi di maturità.
Un prototipo serve a dimostrare che qualcosa può funzionare.
Un prodotto risolve davvero un problema per qualcuno.
Un servizio, invece, è qualcosa che può essere erogato nel tempo. Deve poter essere gestito, osservato, messo in sicurezza, misurato, supportato e mantenuto senza dipendere ogni volta da interventi artigianali.
Questa distinzione diventa centrale nell’era della GenAI.
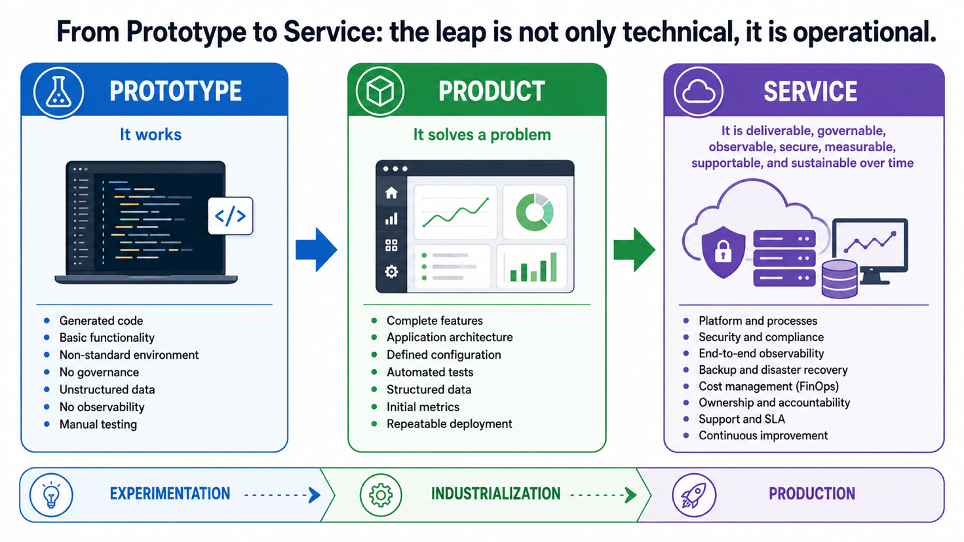
La GenAI può rendere più veloce arrivare al prototipo. In alcuni casi può accelerare anche la costruzione del prodotto. Ma non trasforma automaticamente quel prodotto in un servizio.
Tra un’applicazione che funziona e un servizio che può essere erogato in modo affidabile esiste una distanza precisa.
Quella distanza si chiama modello operativo.
Un servizio richiede ambienti coerenti, processi di rilascio, responsabilità chiare, sicurezza, osservabilità, backup, restore, gestione di RTO e RPO, controllo dei dati, criteri di isolamento, controllo dei costi e supporto.
Ma soprattutto richiede decisioni architetturali e organizzative che non possono essere delegate alla sola generazione del codice.
È in questa distanza tra prototipo, prodotto e servizio che molte iniziative rischiano di fermarsi.
Non perché l’idea non sia buona.
Non perché il codice non funzioni.
Ma perché manca la capacità di industrializzarlo.
Dal software generato al software governato
Nei prossimi anni nasceranno molte più applicazioni rispetto al passato.
Alcune saranno prodotti SaaS. Altre saranno strumenti interni. Altre ancora saranno agenti AI, automazioni operative, dashboard, micro-servizi verticali o piccoli software costruiti per risolvere problemi molto specifici.
La differenza è che molte di queste soluzioni nasceranno più velocemente.
Un team potrà costruire in poche settimane ciò che prima avrebbe richiesto mesi. Un’azienda potrà trasformare un’esigenza interna in una prima soluzione funzionante. Un founder potrà validare un’idea con meno capitale iniziale. Un reparto IT potrà produrre strumenti verticali per supportare processi specifici.
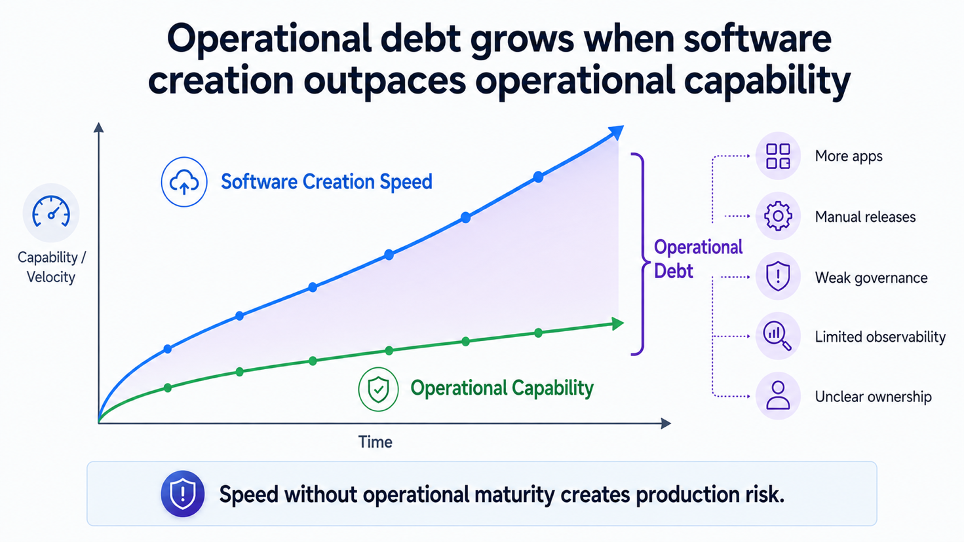
Questa accelerazione, però, introduce un problema nuovo.
Se ogni applicazione nasce rapidamente ma viene rilasciata in modo artigianale, senza standard comuni, senza gestione dei secret, senza osservabilità, senza criteri di sicurezza, senza ambienti coerenti, senza ownership operativa e senza una chiara lettura dei costi, il risultato non è innovazione scalabile.
È debito operativo.
Il collo di bottiglia non sarà più soltanto scrivere codice.
Sarà governare la crescita del software prodotto.
La domanda non sarà più soltanto:
“Quante applicazioni siamo in grado di generare?”
La domanda diventerà:
“Quante applicazioni siamo in grado di portare in produzione senza perdere controllo?”
Questa è la differenza tra software generato e software governato.
Il software generato nasce velocemente.
Il software governato può essere rilasciato, osservato, protetto, aggiornato, misurato, ripristinato e sostenuto nel tempo.
L’agente AI che funziona in demo
Prendiamo un esempio concreto.
Un team costruisce in due settimane un agente AI per consultare ticket interni, knowledge base e documentazione tecnica.
La demo funziona. Le risposte sono convincenti. Il valore è evidente.
Il management vede subito un possibile impatto su supporto, operations e produttività interna.
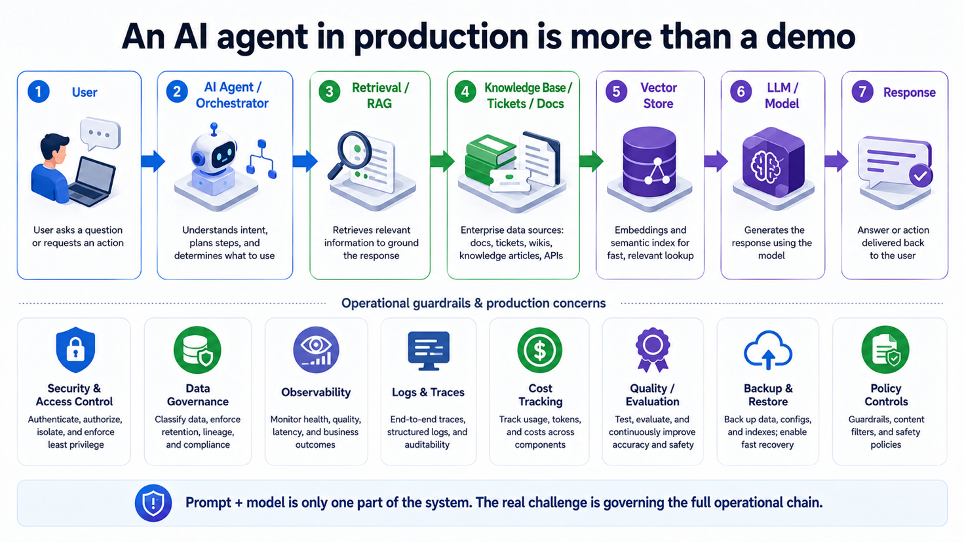
Poi però arrivano le domande vere.
Dove finiscono i dati usati nei prompt?
Gli embedding sono segregati per cliente, dominio o tenant?
Il vector store contiene informazioni sensibili?
I log salvano parti delle conversazioni?
Le trace includono dati cliente?
Chi può accedere alle sessioni?
Quanto costa ogni richiesta?
Il costo è attribuibile per team, prodotto o tenant?
Cosa succede se l’indice vettoriale deve essere ricostruito?
Esiste un backup?
Esiste un restore testato?
Chi approva il go-live?
Chi interviene se l’agente inizia a rispondere male?
Come si misura la qualità del servizio?
Quali dati possono essere inviati a un modello esterno e quali devono restare dentro un perimetro controllato?
È qui che il prototipo smette di essere un esperimento e deve diventare un servizio.
Ed è qui che molte organizzazioni scoprono che la parte difficile non era far rispondere l’agente in demo.
La parte difficile era renderlo affidabile, sicuro, governabile e sostenibile in produzione.
Un agente AI in produzione non è solo prompt più modello.
È una catena operativa fatta di dati, autorizzazioni, retrieval, vector store, modelli, log, trace, metriche, costi, policy, backup, qualità delle risposte, ownership e processi di intervento.
Se questa catena non è governata, l’agente può anche funzionare.
Ma resta una demo che continua a girare.
Il modello operativo: la vera base della produzione
Quando si parla di applicazioni moderne, Kubernetes viene spesso citato come risposta automatica.
Ma Kubernetes, da solo, non è la soluzione.
Un cluster non è un modello operativo.
Un namespace non è una strategia multi-tenant.
Un Helm chart non è un processo di rilascio.
Un deployment riuscito non è sinonimo di produzione governata.
Il valore non sta nel “far girare applicazioni su Kubernetes”. Questo, in molti casi, è ormai solo un pezzo del problema.
Il valore sta nel costruire una piattaforma operativa capace di gestire applicazioni, prodotti, clienti, ambienti, configurazioni, policy, dati e costi in modo coerente.
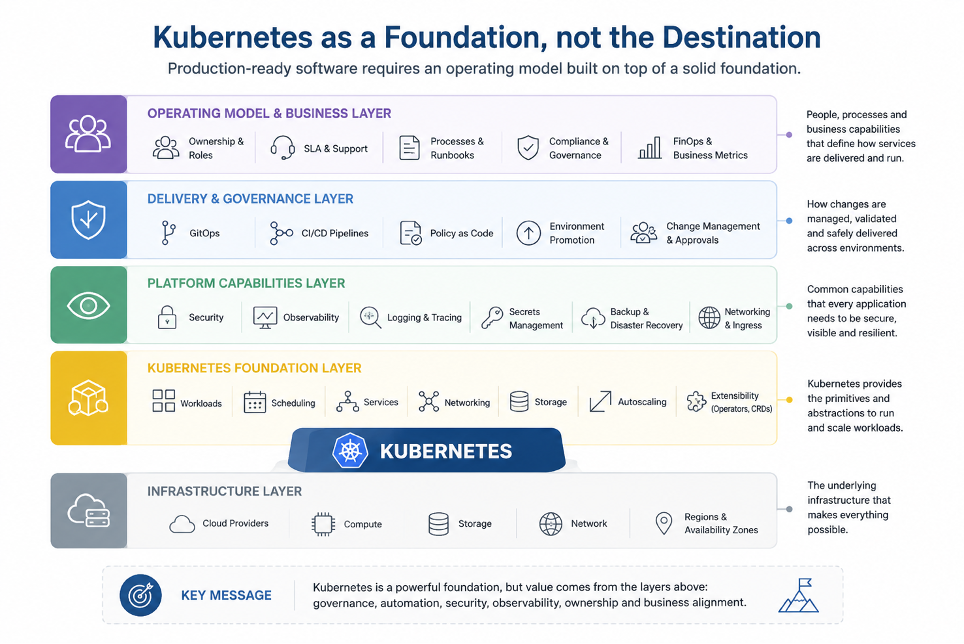
Kubernetes può essere una base molto potente, perché fornisce un linguaggio comune per workload, configurazioni, networking, policy, autoscaling, estensioni e automazione.
Ma deve essere inserito in un modello più ampio.
Un modello in cui:
- Git diventa la fonte della verità.
- Le modifiche sono dichiarative, versionate e revisionabili.
- Le applicazioni sono separate dalle capability di piattaforma.
- Gli ambienti seguono processi di promotion controllati.
- La sicurezza è integrata nel ciclo di delivery.
- I secret sono gestiti fuori dai repository applicativi.
- L’osservabilità è prevista fin dall’inizio.
- Backup e restore sono parte del disegno, non un’aggiunta tardiva.
- I costi sono attribuibili e le responsabilità operative sono chiare prima del go-live.
Questo è il passaggio culturale: Kubernetes non è la destinazione, ma la foundation su cui costruire un sistema operativo applicativo.
GitOps: rendere governabile il cambiamento
Quando il numero di applicazioni cresce, la governance non può dipendere da conoscenza implicita, procedure manuali o interventi diretti sugli ambienti.
Serve un modo per descrivere lo stato desiderato, versionarlo, approvarlo, applicarlo e verificarlo.
GitOps risponde a questa esigenza.
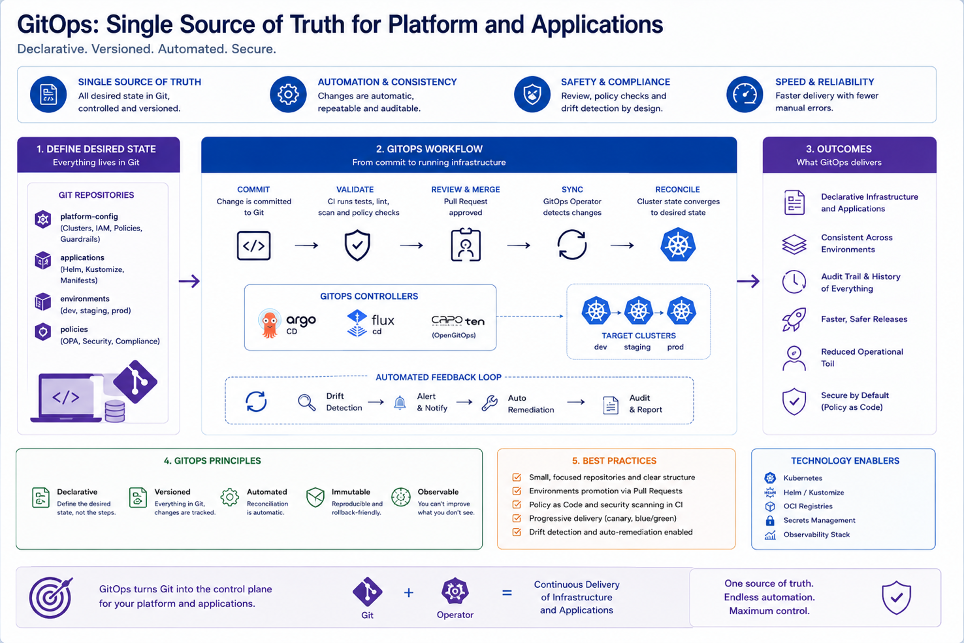
Il punto non è semplicemente usare Argo CD, Flux o un altro tool.
Il punto è introdurre un principio: ciò che esiste negli ambienti deve essere ricostruibile a partire da una fonte dichiarativa, tracciata e revisionata.
Questo cambia il modo in cui si gestisce la produzione.
Le differenze tra DEV, UAT e PROD non devono essere nascoste in configurazioni manuali. Le personalizzazioni cliente non devono diventare eccezioni difficili da ricostruire. Le modifiche non devono avvenire direttamente sui cluster, ma attraverso processi di review, approvazione e riconciliazione.
In un modello GitOps maturo, il deploy non è un comando lanciato da qualcuno.
È l’effetto di una modifica dichiarativa approvata.
Questa differenza diventa fondamentale quando si gestiscono più prodotti, più clienti e più ambienti.
Senza una fonte della verità, ogni ambiente diventa una variante non documentata.
E quando ogni ambiente racconta una storia diversa, la produzione diventa fragile.
Separare ciò che è comune da ciò che è specifico
Uno degli errori più frequenti nei percorsi cloud-native è mischiare tutto.
Componenti di piattaforma, configurazioni applicative, ingress, logging, monitoring, secret, policy, pipeline, runtime configuration, dipendenze e workload finiscono nello stesso spazio logico e spesso negli stessi repository.
All’inizio sembra più veloce, nel tempo diventa ingestibile.
Un modello operativo serio deve distinguere ciò che appartiene alla piattaforma da ciò che appartiene al prodotto.

La piattaforma dovrebbe fornire le capability comuni:
- Networking.
- Ingress.
- DNS.
- Certificati.
- Secret management.
- Policy runtime.
- Osservabilità: logging, monitoring e tracing.
- Backup.
- Sicurezza di base.
- Automazione operativa.
- Naming convention.
- Labeling e tagging.
- Standard di rilascio.
Le applicazioni dovrebbero concentrarsi sul dominio di prodotto:
- Workload.
- Configurazioni funzionali.
- Dipendenze specifiche.
- Feature flag.
- Integrazioni.
- Personalizzazioni cliente.
- Logiche applicative.
Questa separazione non è un dettaglio tecnico.
È ciò che permette di scalare.
Se ogni prodotto reinventa il proprio modo di gestire logging, secret, ingress, monitoring, policy e rilascio, ogni nuovo cliente aumenta la complessità. Ogni eccezione diventa strutturale. Ogni ambiente diventa più difficile da governare.
Una piattaforma ben progettata fa l’opposto.
Standardizza ciò che può essere comune e consente override controllati dove servono davvero.
Non elimina la complessità, la organizza.
Data sovereignty e multi-tenancy: il controllo non è un dettaglio
Nel mondo SaaS tradizionale la sovranità del dato era già un tema importante.
Nel mondo GenAI diventa ancora più rilevante.
Le applicazioni AI non manipolano solo dati applicativi classici. Spesso lavorano su documenti, ticket, conversazioni, knowledge base, log, eventi, embedding, prompt, output generati, trace di esecuzione e contesti recuperati da sistemi interni.
Questo cambia la natura del problema.
Non basta chiedersi dove gira l’applicazione.
Bisogna chiedersi dove vivono i dati, dove vengono processati, dove vengono indicizzati, dove vengono loggati, dove vengono copiati, dove vengono conservati e chi può accedervi.
In un’architettura GenAI, la sovranità del dato non riguarda solo il database principale.
Riguarda l’intera catena: storage, database, object storage, vector store, sistemi di logging, tracing, monitoring, backup, pipeline di ingestion, servizi di embedding, modelli utilizzati, prompt, risposte, audit log, ambienti di test, repliche e disaster recovery.
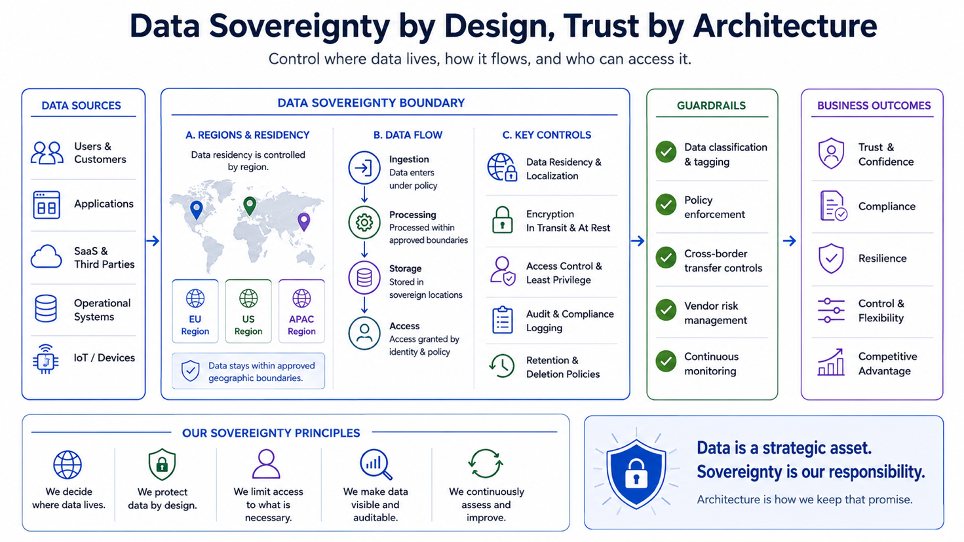
Un dato può uscire dal perimetro non solo perché viene salvato nel posto sbagliato, ma perché viene inviato a un servizio esterno, scritto in un log, copiato in un ambiente non governato, indicizzato in un vector database, incluso in una trace, usato in un prompt o replicato in una regione non prevista.
Per questo la data sovereignty non può essere trattata come una nota legale a fine progetto.
Deve diventare un principio architetturale.
Significa progettare ambienti con criteri chiari di localizzazione del dato, isolamento, cifratura, segregazione tenant, gestione degli accessi, auditabilità, retention e controllo dei flussi verso servizi esterni.
Qui entra anche il tema della multi-tenancy.
Nel SaaS, il multi-tenancy viene spesso ridotto a una scelta architetturale: database condiviso o database separato, namespace condiviso o cluster dedicato, isolamento logico o isolamento fisico.
In realtà è una decisione di modello operativo.
Un cliente può richiedere isolamento per motivi di compliance, un altro per requisiti di performance, un altro per separazione dei dati, un altro ancora per vincoli contrattuali o geografici.
Alcuni prodotti possono convivere su ambienti condivisi. Altri richiedono cluster dedicati. Alcuni componenti possono essere comuni. Altri devono essere separati. Alcune configurazioni possono essere standardizzate. Altre devono essere cliente-specifiche.
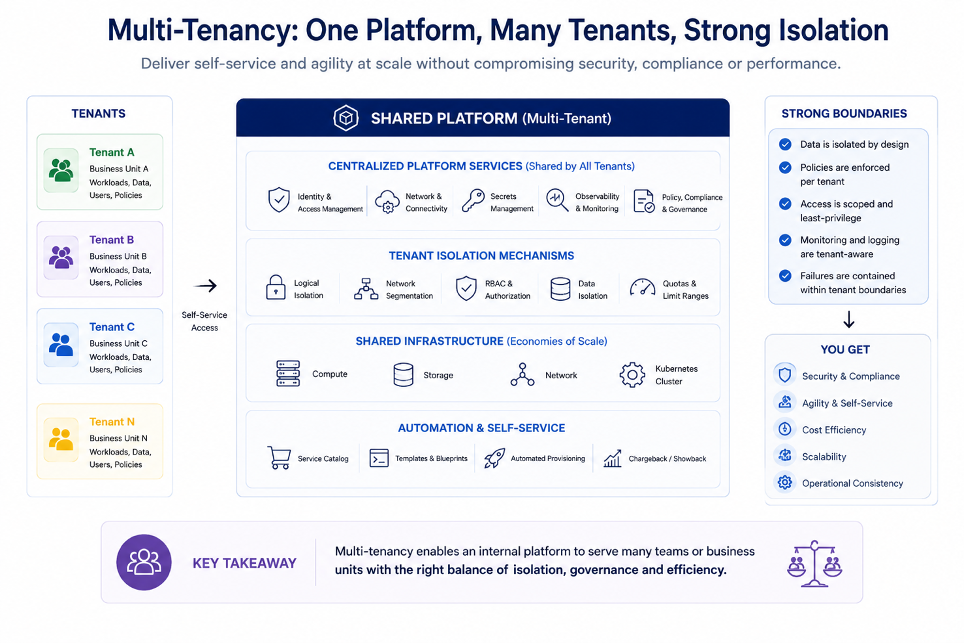
Non esiste una topologia valida per tutti.
Serve un modello capace di decidere tra ambienti condivisi, cluster per prodotto, cluster per cliente, componenti comuni, componenti dedicati e configurazioni specifiche.
Questa scelta deve essere guidata da criteri espliciti: criticità del servizio, tipo di dato trattato, compliance, carico applicativo, dipendenze stateful, SLA, RPO, RTO, personalizzazioni, costi e complessità operativa.
La flessibilità senza governance genera caos.
La standardizzazione senza flessibilità genera rigidità.
Una piattaforma matura deve stare nel mezzo.
Sicurezza, osservabilità e resilienza non sono checklist
Quando si parla di produzione, è facile trasformare tutto in un elenco di strumenti.
SAST, SCA, secret scanning, image scanning, policy engine, RBAC, NetworkPolicy, Prometheus, Grafana, Loki, Tempo, backup, restore, disaster recovery.
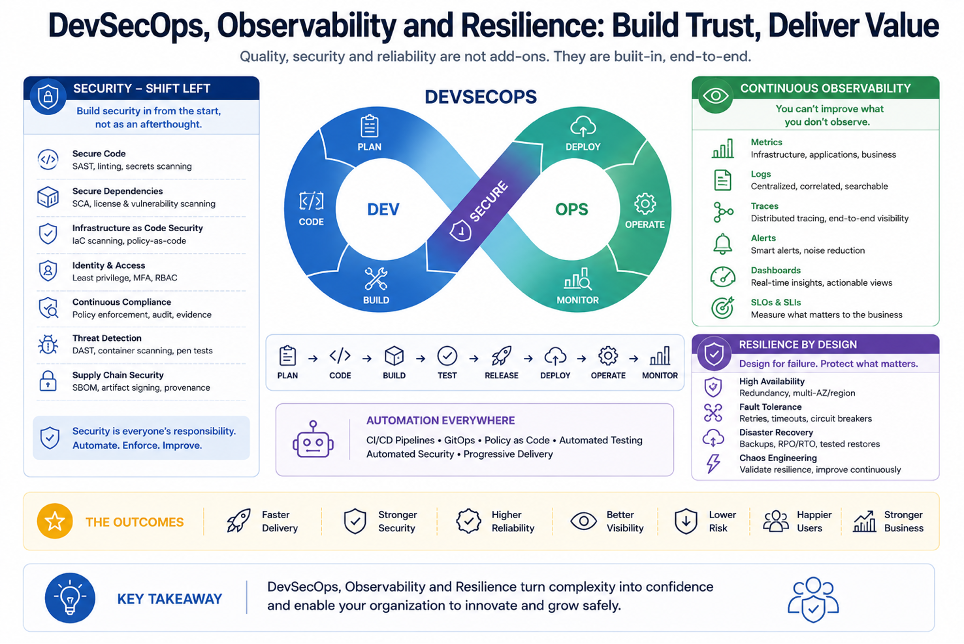
Sono tutti elementi importanti.
Ma il punto non è collezionare tool.
Il punto è costruire un percorso in cui ogni applicazione possa arrivare in produzione con un livello minimo di controllo.
La sicurezza deve impedire che la velocità produca esposizione al rischio.
L’osservabilità deve impedire che un servizio diventi una scatola opaca.
La resilienza deve impedire che un errore si trasformi in perdita irreversibile.
Il backup deve essere collegato al restore.
Il monitoraggio deve essere collegato agli incident.
Gli alert devono essere collegati a responsabilità e runbook.
Le policy devono essere collegate ai rischi reali.
I controlli devono essere integrati nel flusso, non aggiunti a valle.
Questo è particolarmente vero per le applicazioni AI.
Un sistema AI può rispondere, ma rispondere male. Può degradare nella qualità. Può recuperare contesto sbagliato. Può consumare più del previsto. Può invocare tool esterni. Può dipendere da vector store, code, API, documenti, modelli e pipeline di ingestion.
La produzione di sistemi AI richiede quindi una forma più ampia di osservabilità.
Non solo infrastruttura.
Ma comportamento, costo, qualità, dipendenze, dati utilizzati e impatto sul servizio.
Senza questa visibilità, non si ha un servizio enterprise.
Si ha una demo che continua a girare.
Senza ownership non esiste produzione
C’è un tema meno tecnico, ma decisivo: la responsabilità.
Molte piattaforme falliscono non perché mancano strumenti, ma perché mancano ownership e processi chiari.
Chi approva il rilascio?
Chi gestisce le configurazioni?
Chi monitora il servizio?
Chi interviene in caso di anomalia?
Chi mantiene le pipeline?
Chi gestisce backup e restore?
Chi valuta un rischio di sicurezza?
Chi comunica con il cliente?
Chi decide se un prodotto può andare in produzione?
Senza queste risposte, non esiste un vero modello operativo.
La produzione non è solo un ambiente.
È un’assunzione di responsabilità.

Per questo un modello SaaS deve includere ruoli, processi approvativi, escalation, runbook, criteri di go-live, gestione degli incident, post-mortem e responsabilità tra platform team, product team, development, operations, security e delivery.
La tecnologia abilita.
Ma l’ownership rende il servizio credibile.
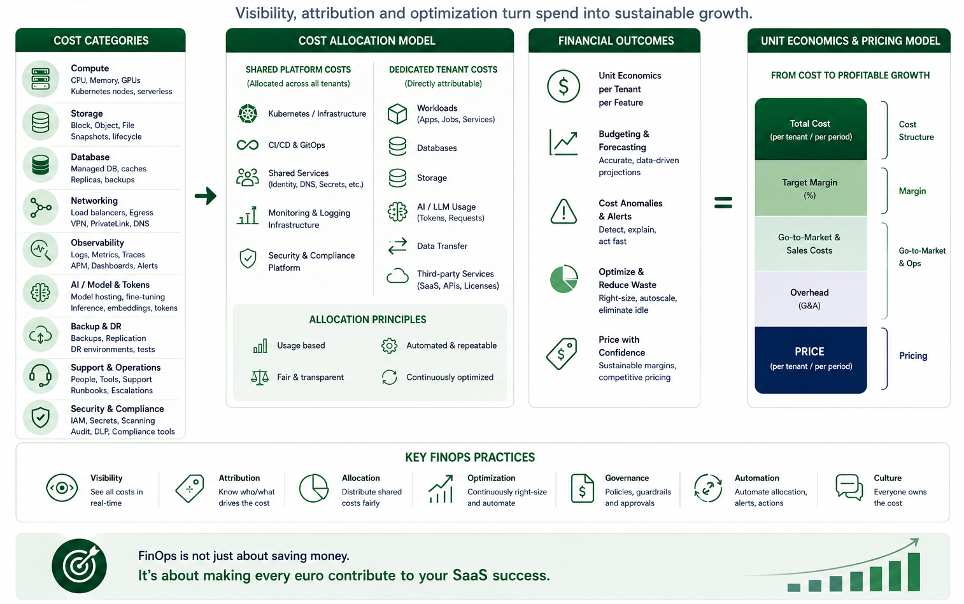
FinOps: se non conosci il costo, non hai un vero SaaS
Un prodotto SaaS può essere tecnicamente corretto e commercialmente fragile.
Succede quando non esiste una lettura chiara dei costi.
Quanto costa servire un cliente?
Quanto costa un ambiente UAT?
Quanto costa mantenere log e trace per novanta giorni?
Quanto incide un cluster dedicato?
Quanto costa un tenant con requisiti di isolamento più elevati?
Quanto costano backup, storage, networking, componenti stateful, osservabilità e traffico verso servizi AI esterni?
Senza queste risposte, il prezzo del servizio viene costruito su percezioni, non su dati.
FinOps, in un modello SaaS, non è solo ottimizzazione della bolletta cloud.
È capacità di collegare architettura, livelli di servizio, isolamento, consumo e marginalità.
È ciò che permette di capire quando una componente può essere condivisa, quando deve essere dedicata, quando un cliente richiede un modello diverso e quando una scelta tecnica impatta direttamente la sostenibilità economica del servizio.
Un SaaS non deve solo funzionare.
Deve reggere economicamente.
Platform Engineering: costruire la strada verso la produzione
In questo scenario, il Platform Engineering diventa strategico.
Non come layer burocratico.
Non come accumulo di strumenti.
Non come tentativo di standardizzare tutto fino a bloccare i team.
Il Platform Engineering ha valore quando costruisce una strada sicura, ripetibile e governata per portare software in produzione.
Una buona piattaforma non elimina le competenze.
Non nasconde ogni dettaglio.
Non trasforma gli sviluppatori in utenti passivi.
Una buona piattaforma riduce la complessità accidentale e lascia visibile la complessità essenziale.
Offre template, pipeline, policy, automazione, osservabilità, secret management, standard di rilascio, controlli di sicurezza, criteri di go-live e modelli di configurazione.
Permette ai team di muoversi più velocemente dentro un perimetro più sicuro.
Nel mondo GenAI questo diventa ancora più importante.
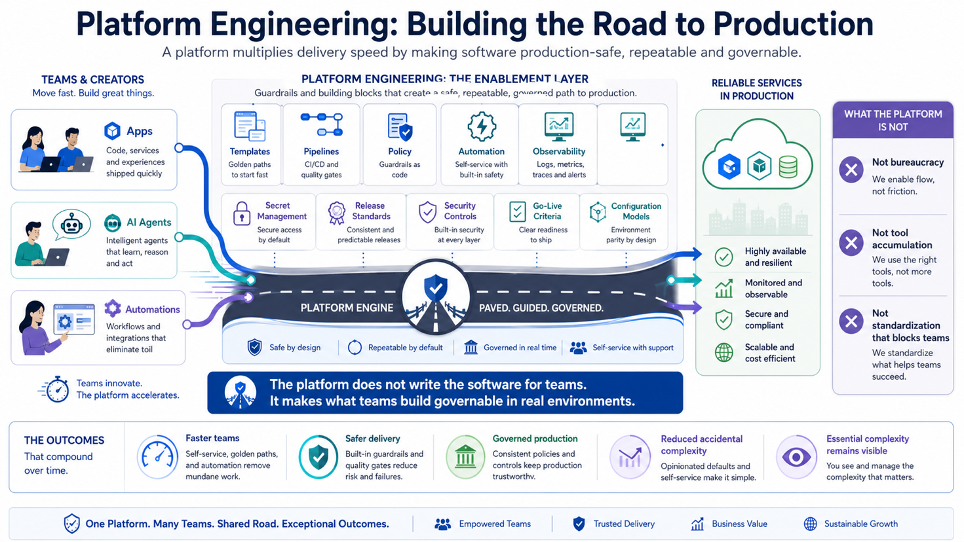
Se ogni team può generare rapidamente nuove applicazioni, agenti o automazioni, l’organizzazione deve fornire un modo altrettanto rapido e controllato per portarli in ambienti reali.
La piattaforma diventa il moltiplicatore della capacità produttiva.
Non perché produce codice al posto dei team.
Ma perché rende governabile ciò che i team producono.
Il futuro premierà chi sa industrializzare
La prossima ondata di innovazione non sarà misurata solo dal numero di applicazioni create.
Sarà misurata dal numero di applicazioni che riusciremo a rendere affidabili.
Quante possono andare in produzione?
Quante possono rispettare policy di sicurezza?
Quante possono garantire data sovereignty?
Quante possono essere monitorate?
Quante possono essere scalate?
Quante possono essere ripristinate?
Quante possono essere aggiornate senza perdere controllo?
Quante possono essere attribuite a un costo sostenibile?
Quante possono supportare clienti diversi senza trasformarsi in eccezioni ingestibili?
Questa sarà la vera selezione.
La GenAI rende più economico generare software, ma non rende automaticamente più economico gestirlo.
Se manca un modello operativo, il costo della complessità arriva dopo: ambienti disallineati, configurazioni manuali, dati dispersi, audit difficili, costi non attribuiti, release fragili, incidenti lenti da diagnosticare e responsabilità poco chiare.
La differenza tra sperimentazione e business sarà qui.
Conclusione
Il codice è una parte del prodotto, non è il prodotto intero.
Il prodotto reale comprende tutto ciò che serve per erogarlo: piattaforma, dati, sicurezza, osservabilità, pipeline, ambienti, configurazioni, backup, processi, ruoli, costi e responsabilità.
La GenAI renderà più semplice creare applicazioni.
Ma proprio per questo renderà più evidente la distanza tra creare software e gestire servizi.
La nuova scarsità non sarà il codice, sarà la capacità di trasformare quel codice in un servizio affidabile, sicuro, governato, conforme e sostenibile.
La GenAI abbassa la barriera dello sviluppo. Il mercato alzerà la barra della produzione.