Karpenter: A New Approach to Intelligent Autoscaling on Kubernetes




Imagine a familiar scene for anyone working with Kubernetes:
your application is taking off, traffic is growing, and pods are starting to max out CPU usage.
The Horizontal Pod Autoscaler kicks in, spins up new replicas… but then something stops.
Some pods remain stuck in a Pending state — the scheduler can’t find enough room — and you start wondering:
“Why doesn’t Kubernetes scale the nodes too?”
That’s exactly where Karpenter comes into play.
An open-source project born at AWS and now part of the CNCF SIG Autoscaling, Karpenter introduces a new approach to how a Kubernetes cluster grows and dynamically adapts to workload demands.
From the HPA to the limits of the Cluster Autoscaler
Kubernetes is great at scaling pods — but not so much at scaling nodes.
When traffic increases, the Horizontal Pod Autoscaler (HPA) creates new replicas based on metrics such as CPU or memory usage.
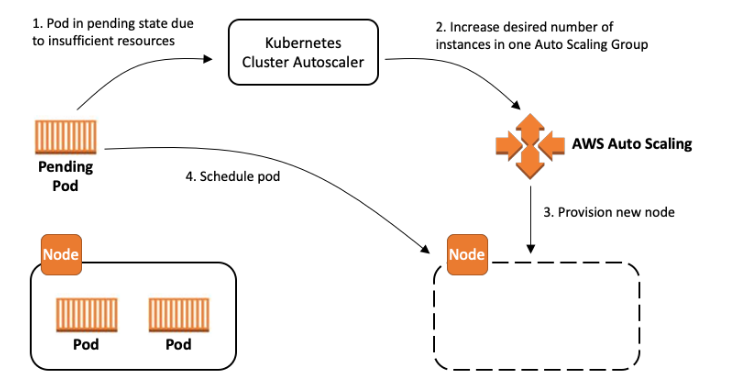
However, if there are no available nodes to run them, the pods remain in a Pending state, waiting for resources to be freed or provisioned.
This “waiting” period is where the Cluster Autoscaler steps in: it monitors unschedulable pods and tries to expand the cluster by adding new EC2 instances.
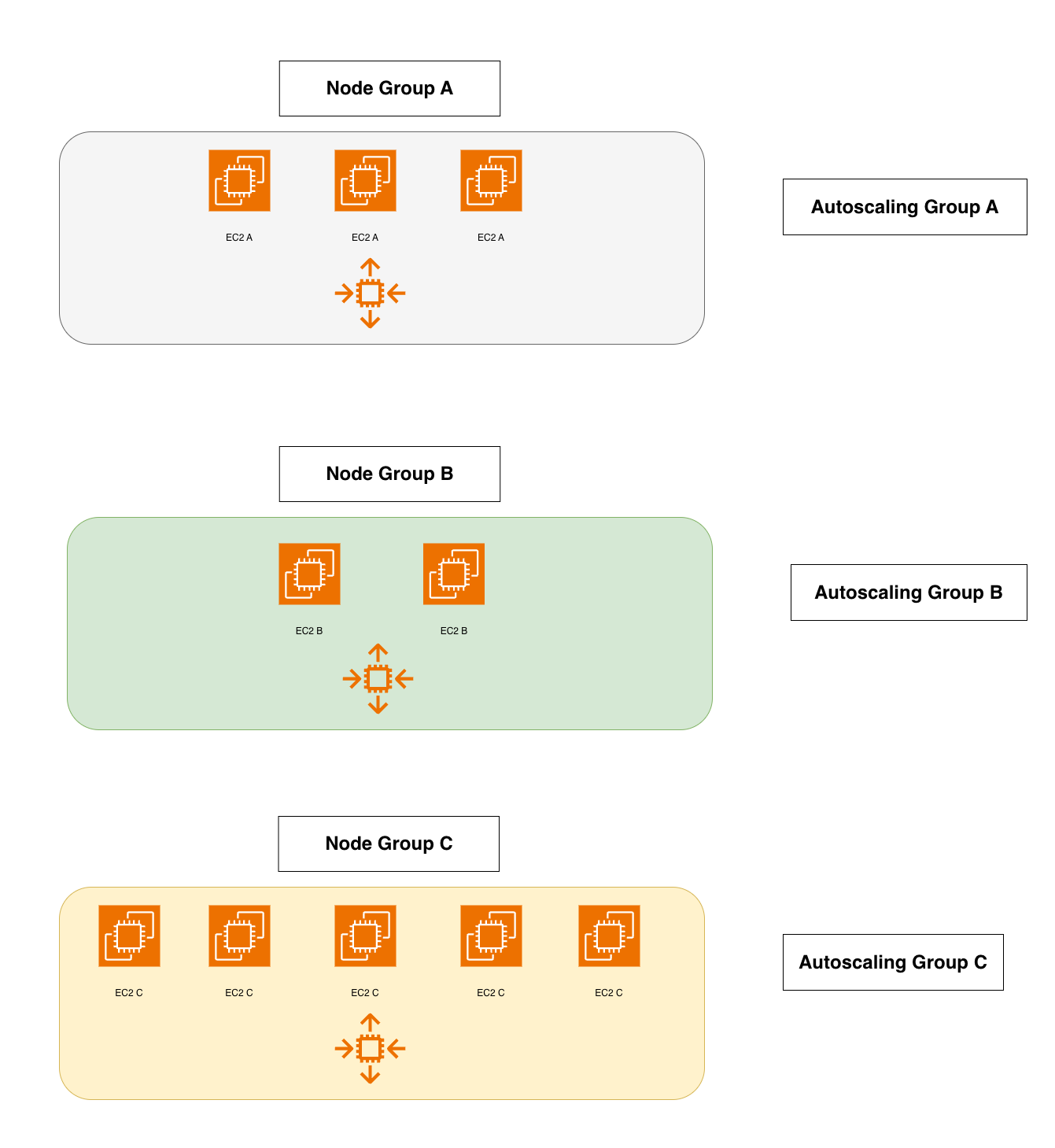
But its operation, based on static node groups, is rather rigid and cumbersome.
Each node group must be defined in advance, with a fixed instance type and uniform size — a typical AWS EKS Cluster Autoscaler best practice.
This model works… until you need flexibility.
If tomorrow you have to run a GPU workload or an AI job, you need to create a new node group, reconfigure autoscaling, and wait several minutes before the new instances are ready.
In today’s cloud world, a few minutes can feel like an eternity.
The Challenges of the Cluster Autoscaler
The Cluster Autoscaler is a good soldier — but it’s armed with outdated weapons.
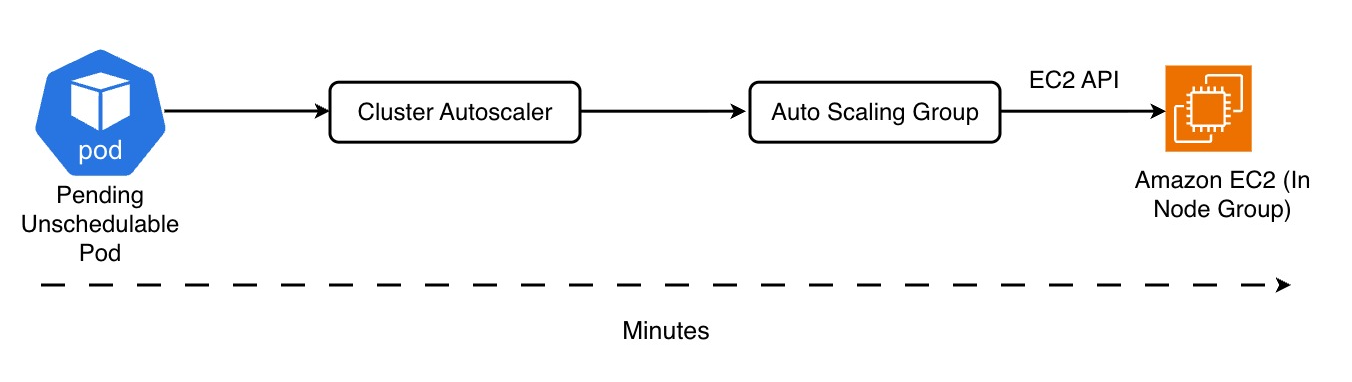
Every time a pod becomes unschedulable, it calls an EC2 Auto Scaling Group, which in turn launches an instance. This chain — CA → ASG → EC2 — introduces latency.
Moreover, managing node groups is an operational nightmare: you need to know in advance which instance types you’ll use, how they’ll be distributed across Availability Zones, and whether you’ll need GPUs or local storage.
The result?
Slow scalability, limited flexibility, often higher-than-necessary costs, and constant micromanagement of the infrastructure.
Enter Karpenter
When AWS announced Karpenter, the goal was clear:
“Simplify node management by letting Kubernetes dynamically choose the most suitable resource for each workload.”
Karpenter is a next-generation autoscaler, designed to be both cloud-native and Kubernetes-native (official documentation and introductory guide).
It no longer communicates through Auto Scaling Groups — instead, it talks directly to the EC2 APIs, making provisioning extremely fast, usually within a few dozen seconds to one or two minutes depending on the AMI, DaemonSets, and network configuration.
Karpenter significantly reduces latency compared to the traditional Cluster Autoscaler, though it isn’t truly “instant.”
It’s open source, a CNCF Sandbox Project, and is now supported on Azure and other cloud providers as well.
Technical note: the AWS provider remains the most mature. For Azure, a dedicated provider is maintained by the community and Microsoft — still evolving and with some architectural differences.
Other providers are currently experimental or unofficial.
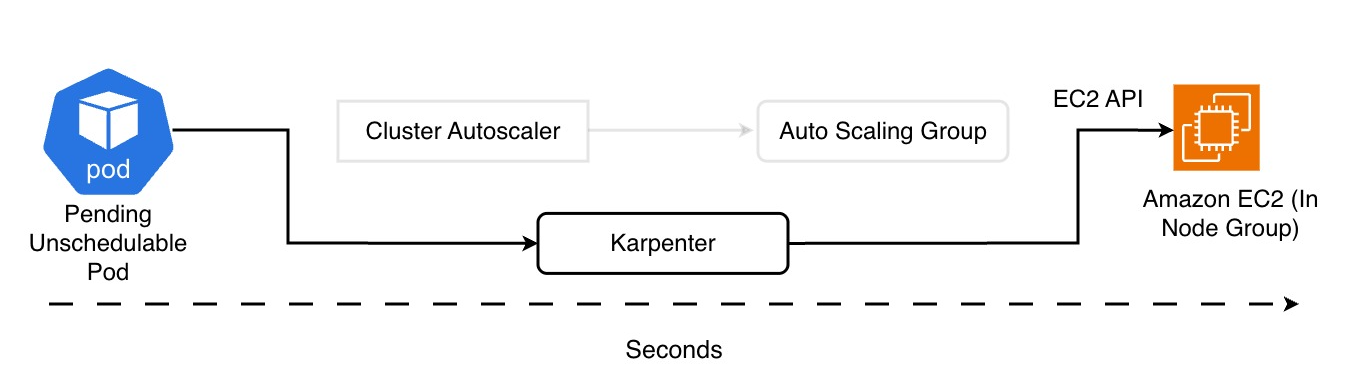
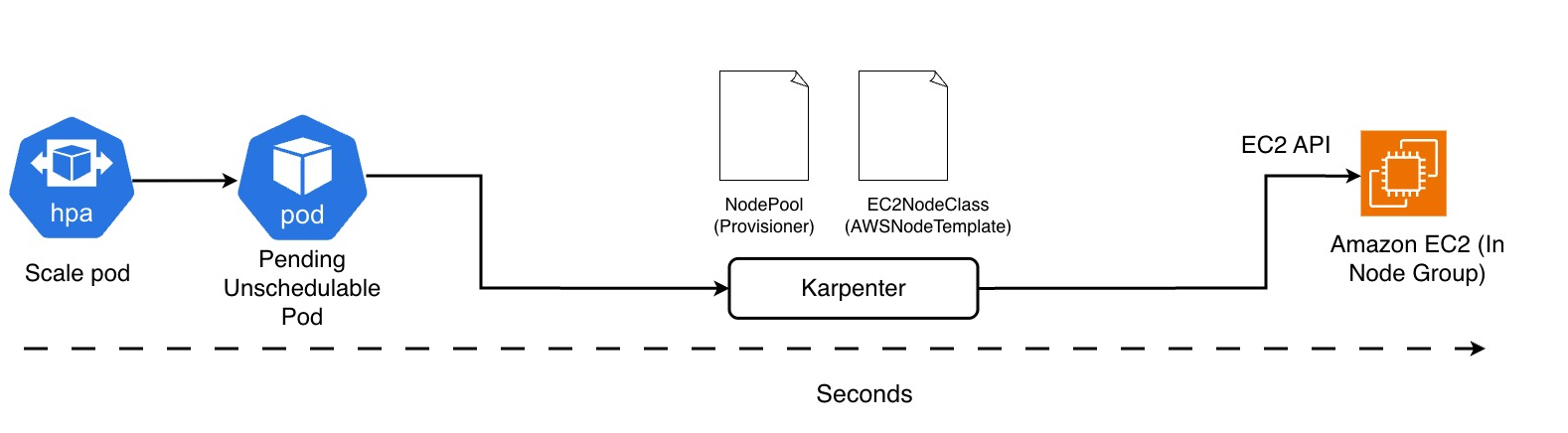
In practice, when a pod cannot be scheduled, Karpenter steps in within seconds:
it evaluates the requested resources, selects the most appropriate instance type, and provisions an optimized node for that specific workload — minimizing the need for manual configuration.
Technical note: according to the official AWS documentation and CNCF guidelines, node provisioning with Karpenter can take less than one minute on AWS.
This timing is realistic under favorable conditions — for example, when AMIs are already available, bootstrap is fast, and networking is ready — but it can vary depending on the environment and cluster configuration.
How Karpenter Really Works
The beating heart of Karpenter revolves around two key Kubernetes resources:
- NodePool – defines the provisioning rules: which EC2 instances to use, in which Availability Zones, with what architecture or cost policy.
- EC2NodeClass – specifies the “physical” details of the node: AMI, Security Group, subnet, IAM Role, tags, and so on.
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: general-purpose
spec:
template:
spec:
nodeClassRef:
name: default-ec2
requirements:
- key: "kubernetes.io/arch"
operator: In
values: ["amd64"]
limits:
resources:
cpu: 1000
memory: 4Ti
disruption:
consolidationPolicy: WhenUnderutilized
consolidateAfter: 30s
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default-ec2
spec:
amiFamily: AL2
role: "KarpenterNodeRole"
subnetSelector:
karpenter.sh/discovery: my-cluster
securityGroupSelector:
karpenter.sh/discovery: my-cluster
NodePool + EC2NodeClass + EC2
When a pod becomes Pending/Unschedulable, Karpenter checks the existing NodePools, evaluates the constraints (architecture, family, instance type, Availability Zone, cost, and availability), and creates the best possible EC2 instance for that workload.
But Karpenter’s job doesn’t end with simply creating new nodes.
One of its most advanced features is consolidation — a mechanism that continuously analyzes cluster utilization and automatically replaces underused or unnecessary nodes.
This reduces operational costs and improves overall efficiency, all without impacting running workloads.
Alongside it, drift detection identifies discrepancies between the desired configuration and the actual state of the nodes — for example, changes in AMIs, labels, or security settings.
When a drift is detected, Karpenter can transparently reprovision the affected nodes to restore consistency.
These capabilities, often overlooked in introductory overviews, represent the real leap forward compared to traditional autoscalers: Karpenter doesn’t just scale — it keeps the cluster cleaner, more efficient, and compliant with DevOps policies over time.
The result is a data plane that adapts dynamically, reducing waste and operational rigidity.
And if you want fine-grained control, you can define limits, priorities, and constraints directly within your NodePool and NodeClass YAML manifests.
Spot Instances and Predictive Intelligence
One of the most interesting aspects of Karpenter is how it handles Spot instances.
Spot instances are inexpensive but volatile — AWS can reclaim them with only two minutes’ notice.
Karpenter listens to EventBridge events, intercepts the Spot Interruption signal, and within those 120 seconds provisions a replacement node — deciding whether to launch another Spot instance or switch to an On-Demand one, depending on cost and availability (official documentation).
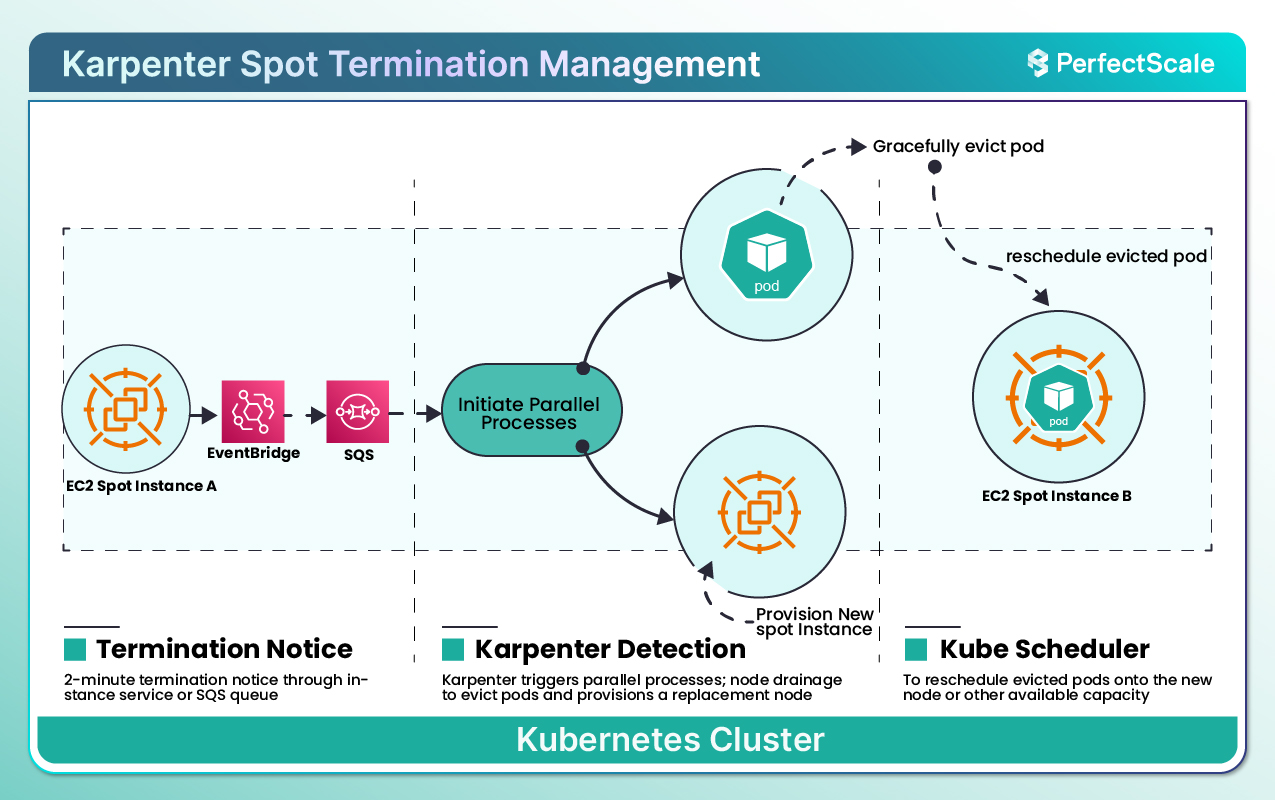
All of this happens with minimal human intervention and in full compliance with Kubernetes rules — pod draining, automatic scheduling, and minimized downtime.
Technical note: Karpenter can significantly reduce disruption during Spot interruptions, but it cannot guarantee zero downtime in every scenario; this depends on the PodDisruptionBudgets, the number of replicas, and the available capacity.
Smart Scheduling: Affinity, Labels, and Team Isolation
Karpenter doesn’t replace the Kubernetes scheduler — it enhances it.
You can continue using nodeSelector, affinity, taints, and tolerations to control where your pods should run.
Want your CI/CD workloads to run only on Spot instances?
Simply label the nodes provisioned by Karpenter with capacity-type=spot and use a nodeSelector in your deployments.
apiVersion: apps/v1
kind: Deployment
metadata:
name: ci-runner
spec:
replicas: 3
selector:
matchLabels:
app: ci-runner
template:
metadata:
labels:
app: ci-runner
spec:
nodeSelector:
karpenter.sh/capacity-type: spot
tolerations:
- key: "workload-type"
operator: "Equal"
value: "ci"
effect: "NoSchedule"
containers:
- name: runner
image: myregistry/ci-runner:latest
resources:
requests:
cpu: "500m"
memory: "512Mi"
CI/CD Deployment on Spot Instances
Have workloads that require GPUs or dedicated hardware?
You can create a specific NodePool that targets instance types such as p4d.24xlarge, and use taints/tolerations to ensure that only compatible pods are scheduled there.
Karpenter automatically adds standard labels such as topology.kubernetes.io/zone, simplifying multi-AZ distribution and improving high availability.
Technical note: the addition of topology labels depends on the provider and node image — it’s automatic on AWS, but may vary elsewhere.
NodePool Strategies: Single, Multiple, Weighted
In the real world, clusters are often shared across multiple teams or applications.
Karpenter handles multi-tenant scenarios seamlessly, allowing you to use multiple NodePools at the same time.
You can choose among three strategies:
- Single NodePool: all applications use the same set of instances — simple, but not very flexible.
- Multiple NodePools: each team has its own NodePool with dedicated rules, limits, and labels.
- Weighted NodePools: Karpenter assigns priorities to different node types based on configured weights — for example, it can try Spot or specific On-Demand instances first.
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: gpu-team
spec:
weight: 80
template:
spec:
requirements:
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["p4d.24xlarge"]
---
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: batch-team
spec:
weight: 20
template:
spec:
requirements:
- key: "karpenter.sh/capacity-type"
operator: In
values: ["spot"]
Weighted NodePools
Note: Saving Plans are an AWS billing mechanism and are not visible to Karpenter.
You can manually prefer instance types that align with your cost commitments, but there is no automatic integration with Saving Plans.
The result is a perfect balance between cost control and resource isolation.
Observability: Understanding What Karpenter Does
Karpenter isn’t a “black box” — everything is observable.
Logs can be viewed directly from the controller pods (kubectl logs), and metrics are natively exposed in Prometheus format, making them easy to integrate with Grafana.
Metrics such as:
- average node provisioning time
- number of pending pods
help measure cluster efficiency and optimize costs.
Technical note: Karpenter does not directly expose estimated instance costs; for that, you’ll need external integrations such as Datadog, PerfectScale, or AWS Cost Explorer.
Disruption Management e Pod Disruption Budget
Karpenter is also an active manager of node “health.”
It can automatically terminate underutilized nodes (voluntary disruption) or respond to external events such as Spot interruptions (involuntary disruption).
Before removing a node, it simulates pod rescheduling elsewhere and respects the Pod Disruption Budgets (PDBs) defined by developers.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: web-frontend-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: web-frontend
Example PodDisruptionBudget
This ensures that no maintenance or optimization operation causes downtime, always keeping the minimum required number of pods running.
Karpenter can also consolidate nodes by automatically removing partially utilized ones, reducing costs and improving cluster utilization density.
This feature — called Consolidation — keeps the data plane continuously optimized based on actual workload demand.
Conclusion – More Than an Autoscaler: an Intelligent Orchestrator
Karpenter goes beyond the traditional concept of an autoscaler, offering more dynamic control over the data plane.
It intelligently manages resource provisioning while respecting policies and optimizing costs in near real time.
In dynamic cloud environments, it represents a significant step forward toward more adaptive infrastructure.
Production adoption note: using Karpenter in mission-critical environments (see AWS EKS + Karpenter best practices) requires careful configuration of NodePool, PodDisruptionBudget, and NetworkPolicies.
Clear governance of these elements is essential to fully leverage Karpenter’s flexibility without introducing instability into the cluster.