Il problema non è AWS. È pensare ancora per account singolo



C’è un momento in cui capisci se un team sta davvero iniziando a usare AWS in modo maturo. Non è quando scopre Terraform. Non è quando mette su il primo cluster Kubernetes. Non è nemmeno quando automatizza una pipeline decente.
È quando smette di ragionare come se tutto dovesse vivere dentro un solo account.
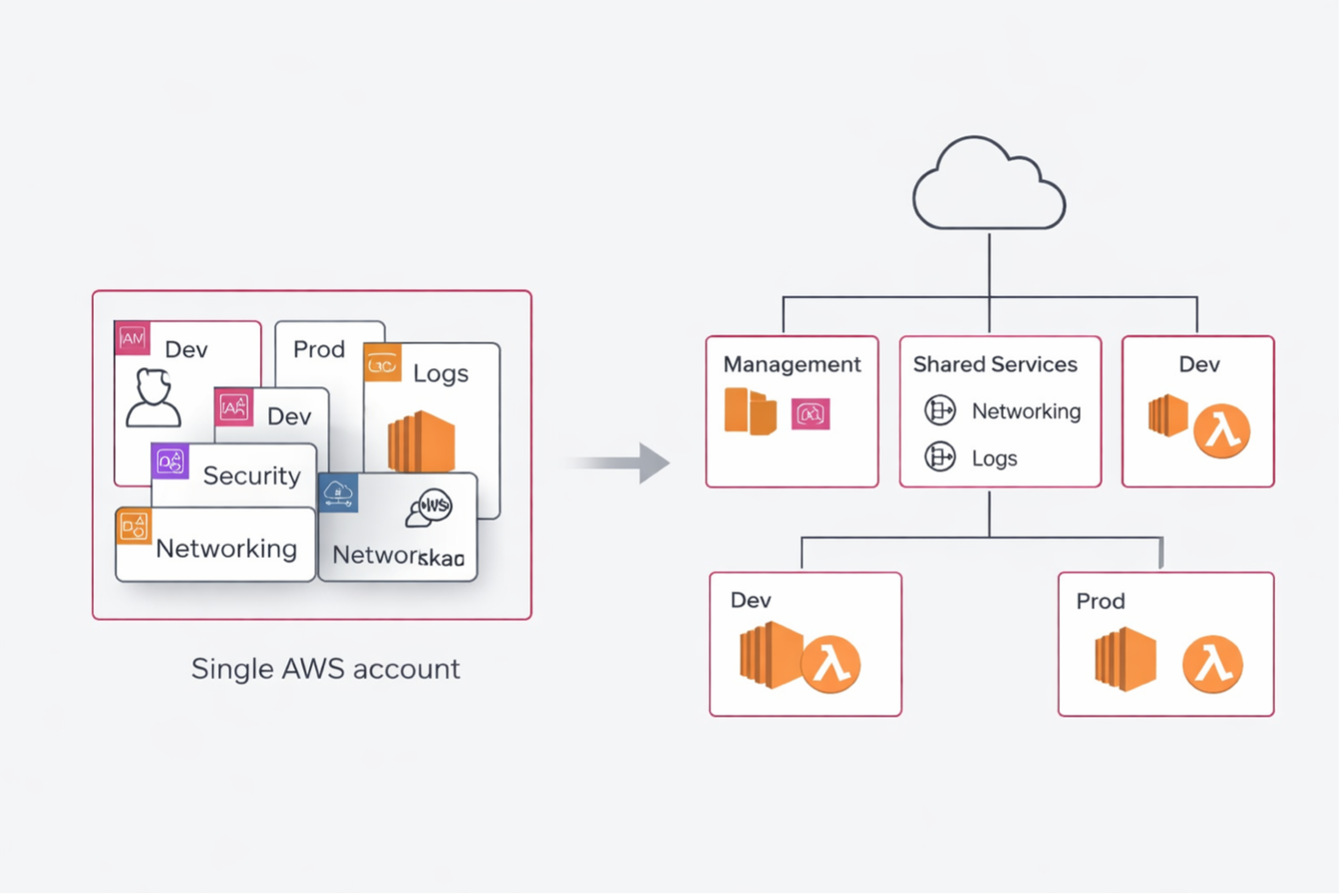
All’inizio l’account unico sembra persino una buona idea. È semplice, veloce, ordinato solo in apparenza. Hai un posto solo dove mettere networking, IAM, log, workload, ambienti, test, produzione. Per qualche settimana sembra perfino efficiente.
Poi il team cresce. Arrivano ambienti diversi, permessi più fini, audit, cost attribution, separazione delle responsabilità, vincoli di sicurezza. E quello che all’inizio sembrava “semplice” diventa soltanto un accumulo di eccezioni.
Il punto, per me, è molto semplice: un account singolo può andare bene per iniziare, ma smette presto di essere un modello operativo.
Quando l’account unico smette di essere comodo
Il primo problema è la separazione degli ambienti. Tenere dev e prod nello stesso account è una scorciatoia che inizia quasi sempre con buone intenzioni e finisce con permessi troppo larghi, naming confuso, risorse difficili da governare e un blast radius inutile.
Il secondo problema è proprio il blast radius. In un account unico, un errore di configurazione, una policy sbagliata o un’operazione lanciata con privilegi troppo ampi possono toccare molto più di quanto dovrebbero.
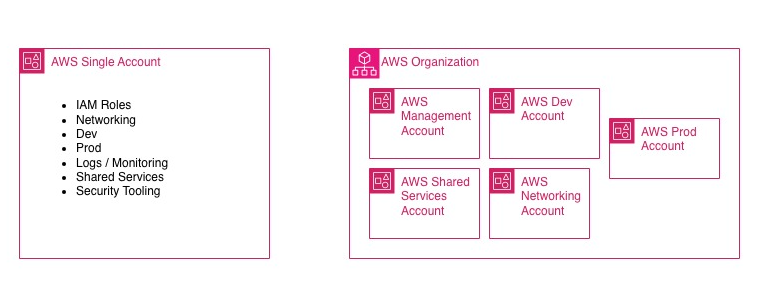
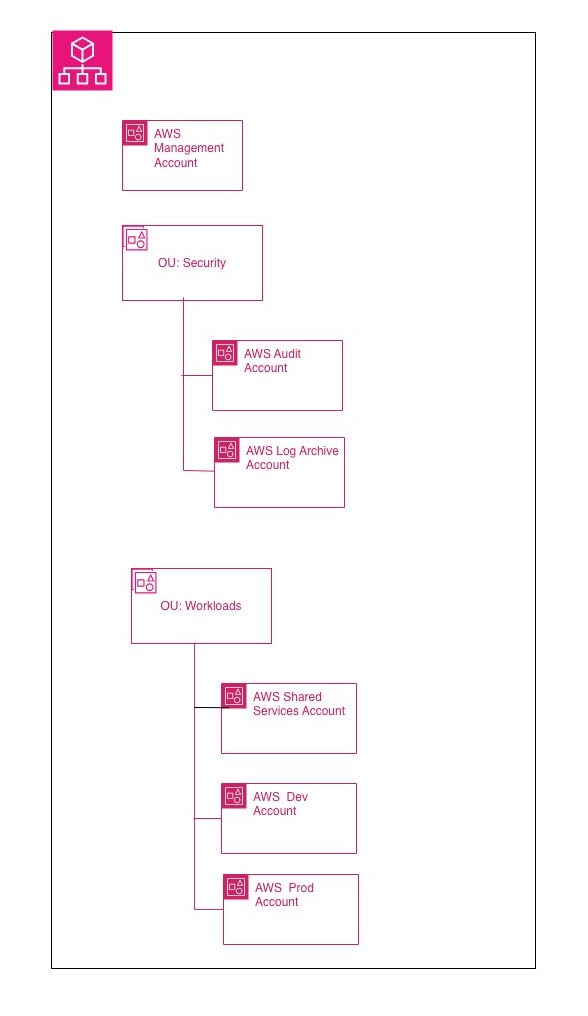
Il terzo è la governance. AWS Organizations nasce proprio per gestire account multipli con policy e confini centralizzati, invece di trattare la crescita come una somma di workaround.
Separare gli account non basta
Qui secondo me c’è l’equivoco più comune: creare più account e pensare di aver risolto il problema.
No. Hai solo distribuito il problema su più contenitori.
Un ambiente multi-account ha senso solo se introduce confini chiari: chi amministra, chi deploya, chi osserva, chi può assumere ruoli cross-account, cosa può essere condiviso e cosa no. Senza questo, il multi-account non è un modello: è solo una moltiplicazione del disordine.
È qui che entrano in gioco Organizations, le OU e le Service Control Policies.
Le SCP non sono IAM
Questo è il punto su cui vedo più confusione, anche in team che su AWS lavorano da un po’.
Le Service Control Policies non servono a concedere accesso. Non danno permessi a utenti o ruoli. Definiscono il perimetro massimo di ciò che può essere fatto dentro gli account membri dell’organizzazione. Il permesso effettivo continua a essere concesso da policy IAM o da resource-based policy. In pratica: IAM concede, ma una SCP può comunque bloccare. AWS le descrive infatti come guardrail grossolani, non come meccanismo di grant. Inoltre si applicano agli account membri, incluso il root user di quei member account, ma non agli utenti e ai ruoli del management account.
Per questo, secondo me, le SCP vanno usate per fare poche cose ma importanti: impedire certe region, bloccare operazioni distruttive, evitare disattivazioni di controlli di sicurezza, imporre guardrail organizzativi. Non per riscrivere IAM con un altro nome.
L’accesso umano non dovrebbe passare da utenti sparsi negli account
Se il multi-account è serio, anche l’accesso umano deve esserlo.
Il punto di ingresso sensato, oggi, non è una collezione di utenti IAM locali distribuiti negli account, ma IAM Identity Center collegato a un identity provider centralizzato oppure usato come directory centralizzata. AWS lo presenta come la soluzione per connettere gli utenti della workforce agli account AWS e alle applicazioni, e nelle linee guida di sicurezza raccomanda questo approccio per avere SSO, gestione centralizzata e un’unica fonte identitaria. Quando abiliti IAM Identity Center, il tipo di istanza raccomandato è proprio quello organization instance.
Tradotto in pratica: l’utente entra una volta, vede solo gli account e i ruoli che gli competono, e non hai bisogno di distribuire utenti locali ovunque. Questo non sostituisce STS: lo rende finalmente usabile in modo pulito per le persone.
STS è il vero collante operativo
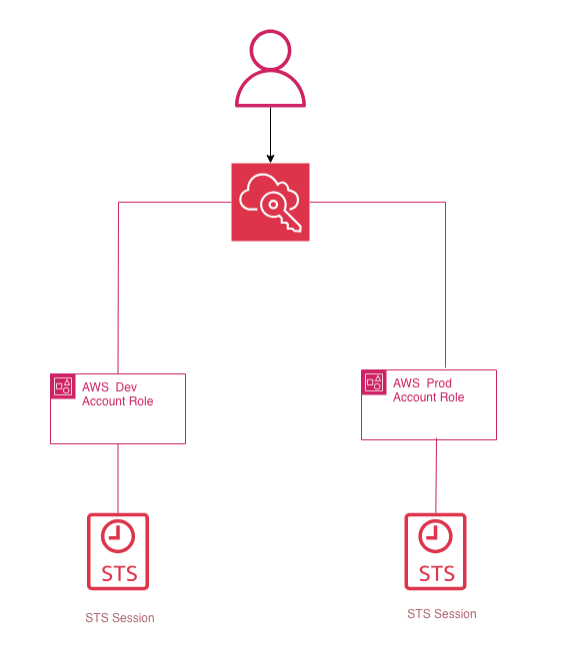
Il multi-account funziona davvero quando smetti di pensarlo in termini di utenti duplicati e inizi a pensarlo in termini di trust + credenziali temporanee.
AWS STS, tramite AssumeRole, restituisce credenziali temporanee con durata limitata: access key, secret key e session token. Sono la base tecnica dei ruoli e della federazione. Non appartengono in modo permanente all’identità che le usa, scadono, e sono il modo corretto per fare accesso intra-account e cross-account senza disseminare credenziali statiche. AWS raccomanda in generale di usare ruoli e credenziali temporanee per utenti umani e workload.
È per questo che, in un’architettura multi-account seria, la domanda non è “come entro in quell’account?”, ma “quale ruolo posso assumere, da quale identità, per fare quale operazione, per quanto tempo?”.
Quando questa parte è chiara, il resto si semplifica: automazione, audit, operatività, revoca, MFA, CI/CD. Quando non è chiara, iniziano i workaround che prima o poi paghi.
Un pattern iniziale che funziona spesso
Non esiste una topologia universale valida per tutti. Dipende da dimensione, compliance, operating model, grado di autonomia dei team e livello di centralizzazione che vuoi ottenere.
Detto questo, un pattern iniziale che funziona spesso è questo:
un management account, un account shared services o networking, un account dev e un account prod.
La parola importante qui è “iniziale”. Non è una baseline assoluta. È un buon punto di partenza quando vuoi separare governance, servizi comuni e workload senza introdurre complessità prematura. AWS raccomanda di usare il management account solo per le attività che richiedono davvero quel livello e di evitare di deployare workload lì dentro.
Questa, per me, è una disciplina importante: il management account non è l’account più comodo dove mettere risorse; è quello che dovresti sporcare meno possibile.
RAM e shared VPC cambiano davvero il modo di progettare
Uno dei servizi che cambia più di quanto sembri l’architettura AWS è AWS RAM.
Per anni il modello implicito è stato: ogni account ha le sue risorse, e se vuoi farle parlare tra loro inizi con peering, transit gateway, eccezioni e compromessi. Con RAM, invece, alcune risorse possono essere condivise in modo nativo tra account o OU, e questo apre pattern più interessanti.
Il caso più potente è il VPC sharing. L’owner account condivide subnet non di default con altri account della stessa organizzazione. Dopo la condivisione, i participant possono vedere le subnet condivise e creare, modificare e cancellare le proprie risorse applicative al loro interno. Non possono però modificare le subnet condivise né gestire le risorse che appartengono al VPC owner o agli altri participant. Alcune azioni restano esplicitamente responsabilità dell’owner.
Questo cambia proprio il modello operativo: centralizzi il networking, decentralizzi i workload. Non è sempre la scelta giusta, ma quando hai più team applicativi e vuoi coerenza sulla rete, sul routing, sull’egress e sui controlli, è un pattern molto forte.
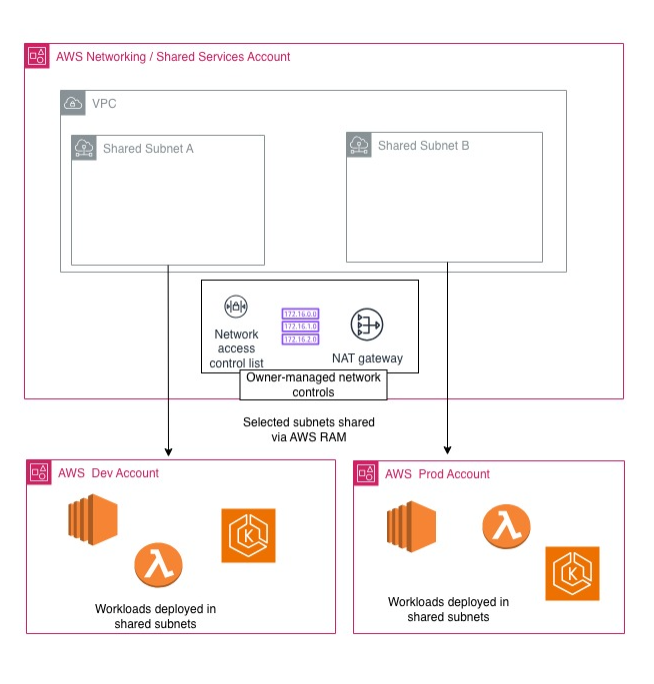
Un caso pratico semplice ma realistico
Immagina una piattaforma con un account networking/shared-services che possiede la VPC e le subnet, e due account workload: dev e prod.
Le subnet vengono condivise via RAM. I team rilasciano EC2, container o altri workload nei rispettivi account, ma dentro una rete comune controllata centralmente. Le SCP fanno da guardrail organizzativi. Gli operatori umani accedono via IAM Identity Center. L’operatività cross-account passa da ruoli assunti con STS.
Già così hai ottenuto tre cose che nell’account unico si confondono continuamente: separazione, governance e operatività.
Anche su S3 vale lo stesso principio: meno folklore, più policy
Sul cross-account access a S3, secondo me, conviene aggiornare subito il modo di raccontarlo.
Storicamente si finiva spesso a parlare di ACL. Oggi quella narrativa è molto meno centrale, perché S3 Object Ownership usa di default Bucket owner enforced e con questa impostazione le ACL sono disabilitate. In quel modello, il bucket owner possiede gli oggetti e governa l’accesso tramite policy. AWS raccomanda esplicitamente di disabilitare le ACL sui bucket nuovi. Per il cross-account access, quando bucket e identità sono in account diversi, la documentazione AWS chiarisce anche che servono i grant corretti sia dal lato IAM sia dal lato bucket policy.
Per questo, in un’architettura moderna, trovo più pulito ragionare con ruoli ben definiti e resource policy leggibili, non con stratificazioni storiche che nessuno vuole più debuggare.
Dove vedo gli errori più frequenti
Il primo è usare le SCP come sostituto di IAM.
Il secondo è avere più account ma nessun modello serio di trust e role assumption.
Il terzo è trattare il management account come un account operativo normale.
Il quarto è introdurre shared VPC senza aver chiarito responsabilità e limiti dell’owner rispetto ai participant.
Il quinto è continuare a raccontare il cross-account access a S3 come se fossimo fermi all’era delle ACL.
Il punto finale
AWS non ti obbliga a progettare bene.
Puoi tranquillamente tenere tutto in un account solo, mischiare ambienti, distribuire permessi in modo poco leggibile e rimandare ogni scelta strutturale. Per un po’ funziona. È proprio questo il problema: funziona abbastanza da farti credere che sia sostenibile.
Per me la maturità su AWS comincia quando capisci che il tema non è “quanti servizi uso”, ma come disegno confini, trust e governance.
Il problema non è AWS.
Il problema è continuare a pensare per account singolo quando il tuo contesto, da tempo, non lo è più.