GraphQL on autopilot: why (and how) to move from REST to AppSync without the pain




When APIs are no longer enough
There’s a moment, in every growing digital project, when slowness doesn’t come from the code but from the connections.
The backend replies in milliseconds, the database scales, the CDN does its job… but the user still waits.
Every time they open the main screen, the app runs a small invisible marathon: first it asks for the profile, then the posts, then notifications, then the friends list.
Five requests. Some in parallel, others in sequence.
The result? A handful of seconds that stack up at every interaction.
That’s when many teams realize they’re prisoners of a model whose time has passed.
REST, born in an era of lightweight clients and lightly-connected data, struggles today to power complex experiences — because every resource lives at its own endpoint, and the client must orchestrate everything, often becoming a small microservices orchestrator.
But there’s another way.
A way where the server composes the response, not the client.
A way where you ask only for what you need and receive it in a single call.
This is where GraphQL enters the scene.
GraphQL: the language that gives shape to data
GraphQL isn’t meant to replace REST, but to overcome its structural limits.
It’s a query language for APIs, but also something deeper: an explicit contract between those who build the interface and those who model the application’s data.
At the heart of it is the GraphQL schema — a logical, formal representation of the application domain.
It isn’t just a copy of a database: it’s the conceptual mapping of how data connects and how it can be requested, changed, or observed.
In other words, the schema is the graph that describes your application.
Within the schema there are three fundamental operation types:
- Query, which let you navigate the graph and gather information. Every field requested by the client becomes a node the server resolves, traversing the relationships defined in the schema. It’s how the client “reads” the system, moving among entities and connections like in a knowledge graph.
- Mutation, which let you modify or create data. They’re the equivalent of write/update/delete operations: they change the application state and return the updated object. Here too, the contract is strict: the schema dictates which operations are allowed and which fields can be manipulated.
- Subscription, which let you receive real-time updates when something changes. Subscriptions are part of the GraphQL standard (together with queries and mutations) but — and here lies the important nuance — the standard doesn’t define the transport protocol. GraphQL specifies how to declare a subscription, but leaves each implementation free to choose how to deliver updates (WebSocket, SSE, or other mechanisms). This is precisely where AWS AppSync shines: it provides a fully managed WebSocket infrastructure that handles connections, filters, and message delivery, enabling real-time reactivity without building or maintaining a manual pub/sub layer.
The result is a clear, powerful model: the client no longer needs to know the backend topology or resource addresses; it just needs to know how to talk to the schema.
From that moment on, the server composes the response like a puzzle, interfacing with the necessary data sources — databases, Lambda functions, HTTP APIs, or external systems — and returns to the client exactly what was requested: not a byte more, not a byte less.
REST vs GraphQL: two models for two eras
To really understand why GraphQL was born, first look honestly at what REST has become over the years.
REST had a huge merit: it brought order to the chaos of APIs, imposing a clear model made of resources, endpoints, and HTTP verbs. But that model was born in a different world — a world where apps were web pages, not interactive ecosystems that update themselves in real time.
Today’s interfaces ask for much more. They don’t just want to retrieve data, but to compose it, merge it, and update it continuously.
And here REST begins to show cracks.
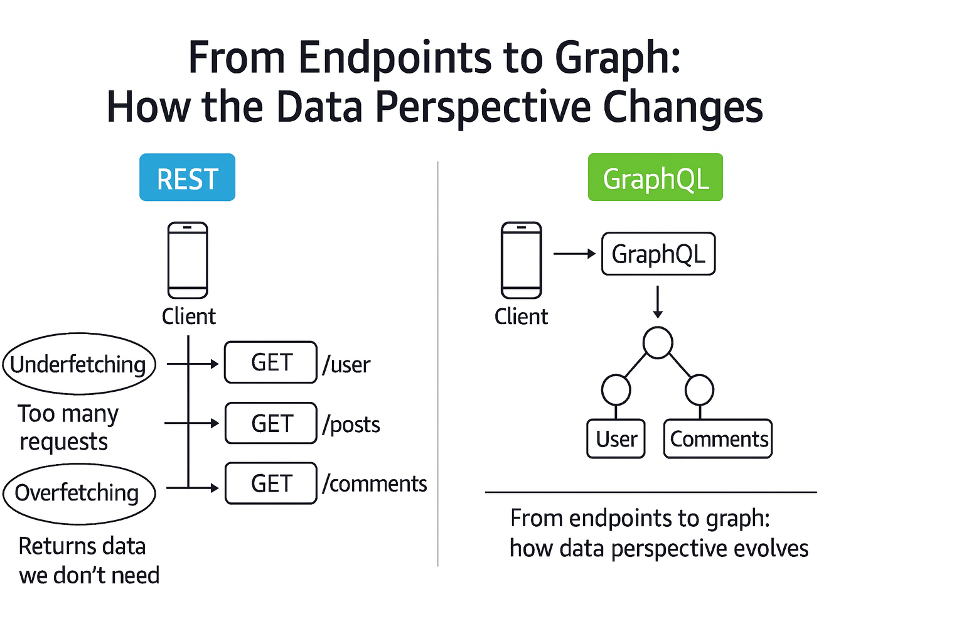
With REST, every resource lives at its own endpoint. If you want to build a complex screen — e.g., show the user profile, their posts, and each post’s comments — you must orchestrate multiple calls: one for the user, one for the posts, one for the comments. Perhaps even in sequence, because you first need the post ID to request comments.
It’s the classic chain of requests that starts innocently and ends in a tangle of round trips, latency, and duplicated client logic.
GraphQL radically changes the viewpoint.
You no longer think in terms of “endpoints,” but in terms of a data graph.
Every type in the schema is a node; every relationship, a link. And the query is simply a way of navigating that graph.
So instead of telling the server which URLs to call, the client declares which fields it needs:
query GetUser {
user(id: "123") {
name
posts {
title
comments {
content
author { name }
}
}
}
}
One request.
One response.
Everything needed to compose a full screen, in a single network trip. This is the heart of GraphQL’s advantage:
- no over-fetching (you don’t download useless data),
- no under-fetching (you don’t need extra calls to complete the information),
- and above all, no rigid dependency on endpoints, which often forces the client to know the backend’s internal structure.
Where REST exposes a set of resources, GraphQL exposes a domain model — a graph that naturally represents your application.
That’s why we say GraphQL isn’t a replacement for REST, but an evolution in how we think about data.
And when this evolution meets a fully managed platform like AWS AppSync, the combination becomes even more powerful: no servers to maintain, automatic query resolution, built-in caching, integrated security, and managed real-time.
Resolvers: the soul of the graph
If the GraphQL schema is the map that describes what the data looks like and how it connects, resolvers are the hands that travel that map.
They are the functions that translate the client’s request into concrete backend actions: read a record, compute a value, retrieve information from an external service.
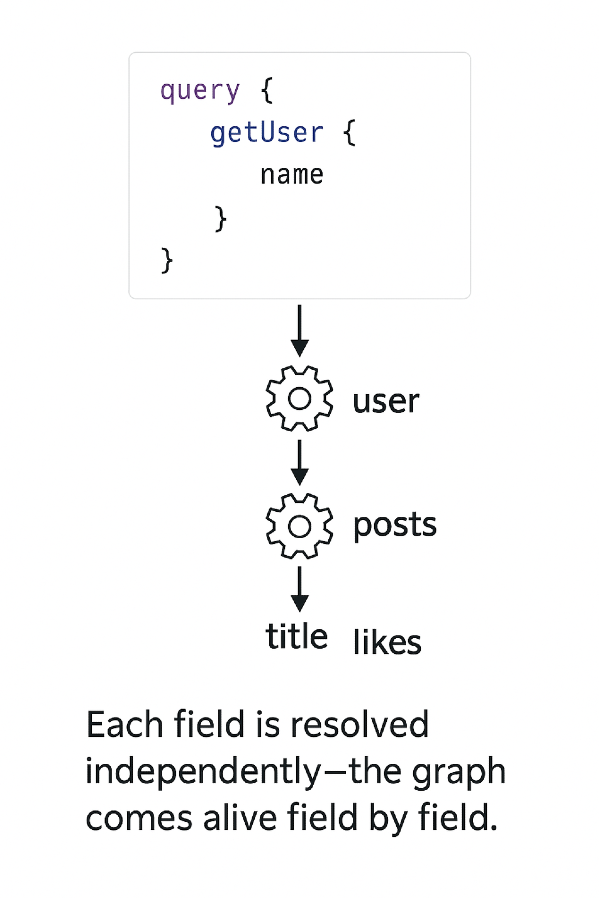
Every field in a GraphQL query is resolved by a resolver. When the client asks, for example:
{
user(id: "42") {
name
posts {
title
likes
}
}
}
The server doesn’t return everything “in one block,” but instead runs a small function for each field — one for user, one for name, one for posts, and so on.
Each of these knows where to fetch that specific piece of information and how to return it in the format defined by the schema.
This mechanism is what allows GraphQL to reconstruct the response like a puzzle, following the data graph step by step.
It’s not just about querying a database — it’s about composing information from multiple sources while maintaining consistency and strong typing throughout the process.
Resolvers can be simple — when a field directly maps to a known value — or more complex, when they need to combine data, apply rules, or filter results.
In both cases, the principle remains the same: every field in the graph is autonomous, and its resolution logic is explicit and declared.
This approach makes GraphQL predictable and transparent: every piece of data exists because something resolved it deterministically.
And it’s precisely this modularity that makes it possible to build evolving APIs — where you can add new fields or relationships without breaking existing parts.
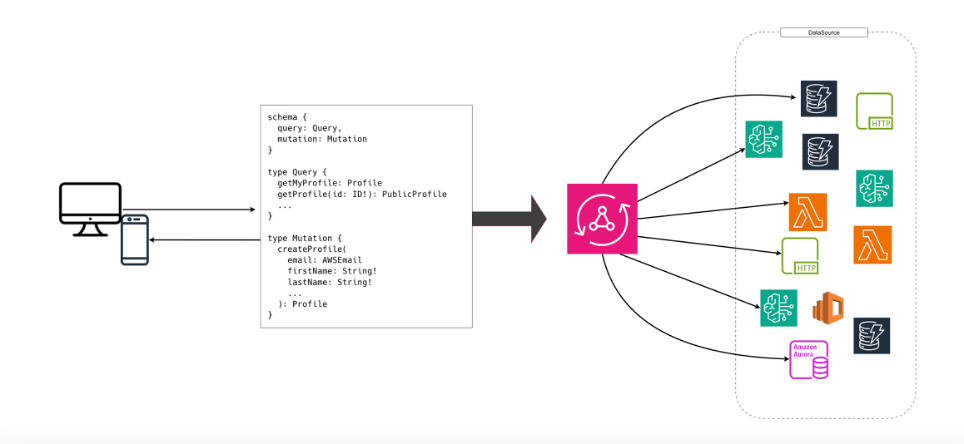
AppSync: GraphQL on Autopilot
So far, we’ve seen how GraphQL, by itself, is an elegant and coherent language: the schema defines the graph, the resolvers bring it to life, and the server orchestrates everything field by field.
But in real-world scenarios — where you have to think about infrastructure, security, authentication, caching, and scalability — building and maintaining a full GraphQL server can quickly become complex.
That’s where AWS AppSync comes in: a fully managed GraphQL platform that takes everything off your plate except the business logic.
You don’t need to install a server, manage sockets or load balancers, or write code for scaling.
AppSync is a completely serverless orchestration layer: it receives queries, authenticates users, resolves fields through data sources, and returns the ready-to-use response — all with high availability and pay-as-you-go pricing.
It natively integrates with:
- DynamoDB, for fast and scalable reads and writes
- AWS Lambda, for custom application logic
- HTTP, to access REST services or external APIs
- EventBridge, for event-driven architectures and asynchronous notifications
- Bedrock, to leverage generative AI services
How AppSync Implements Resolvers
In GraphQL, every field is resolved by a function.
In AppSync, these resolvers become configurable components, tightly integrated with AWS data sources.
This is where the concept we discussed earlier takes concrete shape.
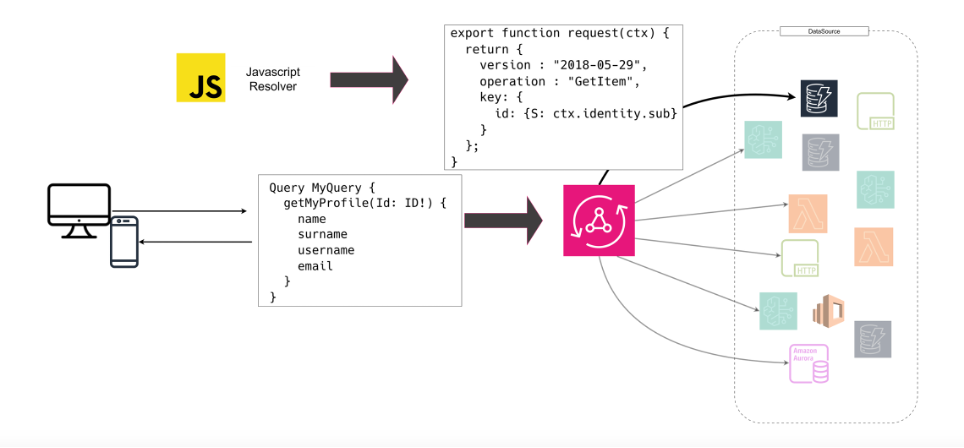
1. Unit Resolver
This is the simplest type: it maps a field to a single operation against a data source.
It can be configured using VTL (Velocity Template Language) or, more recently, JavaScript resolvers.
This declarative approach makes it possible to model even complex logic without writing server-side code, keeping the flow predictable and low-latency.
2. Pipeline Resolver
When an operation requires multiple steps — for example, validating input, enriching data from several sources, and composing a final response — AppSync allows you to chain up to ten resolver functions in sequence.
Each function has its own data source and passes its output to the next one via ctx.prev.result.
It’s like building a pipeline: clean, modular, and reusable.
This model minimizes the need for Lambda, improving efficiency and reducing costs.
3. Lambda Resolver
When you need to run actual code, AppSync can invoke AWS Lambda functions.
They’re ideal for custom business logic, integrations with external systems, or data transformations that can’t be handled with templates.
AppSync also optimizes this path through batch invoke, grouping multiple resolutions into a single invocation to minimize round-trips and cold starts.
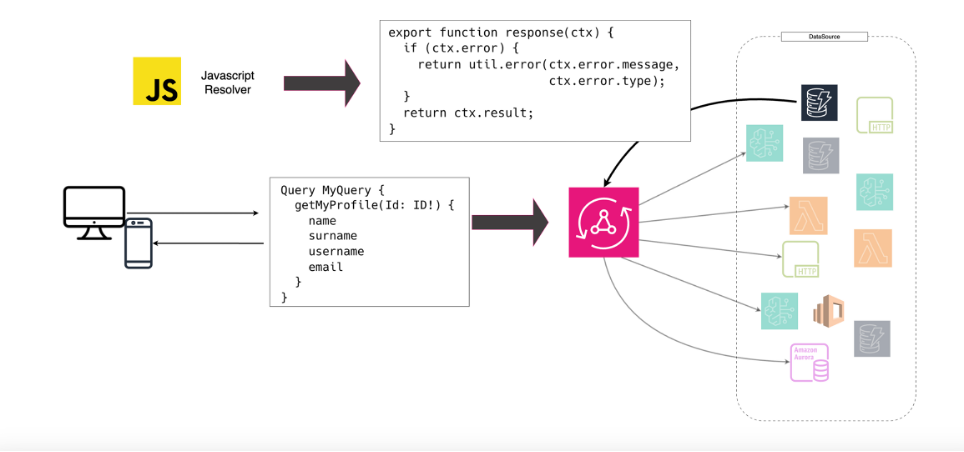
Example of a JavaScript resolver
Caching e performance
AppSync offers a caching system for resolvers, configurable per individual operation or field.
Unlike a global cache, this approach is more granular and allows you to maximize the hit ratio while reducing load on DynamoDB or Lambda.
In real-world projects, a well-placed cache can achieve over 95–99% hit rates, significantly lowering costs and latency.
Practical tip: use per-resolver caching for “cold” or highly reusable fields, such as static lists, lookups, or metadata. Avoid using it for requests that change frequently or are personalized per user.
Native scalability and reliability
AppSync inherits the scalability of the underlying AWS services it’s built on.
There are no instances to manage — it automatically scales with the workload, handling millions of requests simultaneously.
And since resolvers operate close to the data sources (often within the same AWS plane), latency remains low and predictable even under heavy load.
Why a managed approach is more efficient
Building a GraphQL server “by hand” means taking care of authentication, throttling, logging, scaling, and real-time connections yourself.
AppSync includes all of this by default:
- Security is based on IAM, Cognito, and OIDC
- Real-time subscriptions rely on managed WebSockets
- Monitoring integrates with CloudWatch and X-Ray
- And the entire execution layer is serverless
In other words, AppSync isn’t just a GraphQL implementation — it’s a data orchestration platform.
It acts as an intermediate layer that connects APIs, services, and heterogeneous data sources, while keeping the GraphQL experience seamless for the client.
The result: GraphQL that grows with you
With AppSync, you can start small — for example, by placing a GraphQL interface in front of a couple of existing REST APIs — and then evolve it by adding new data sources, pipeline resolvers, and caching.
All without rewriting code or worrying about scaling or provisioning.
In practice, AppSync lets you focus on what really matters: your application logic, the quality of your schema, and the experience of the people consuming your data.
Authentication, security, and real-time: GraphQL that knows its users
In a perfect world, every GraphQL request would have a single purpose: to fetch or modify data.
In the real world, however, queries come from different users, roles, and systems — and not everything should be accessible to everyone.
That’s why AWS AppSync integrates security and authentication at the very core of the service.
Not as an external filter, but as part of the GraphQL model itself: every field, operation, and subscription can be protected with granular rules, declared directly in the schema.
Multi-authentication: multiple identities, one schema
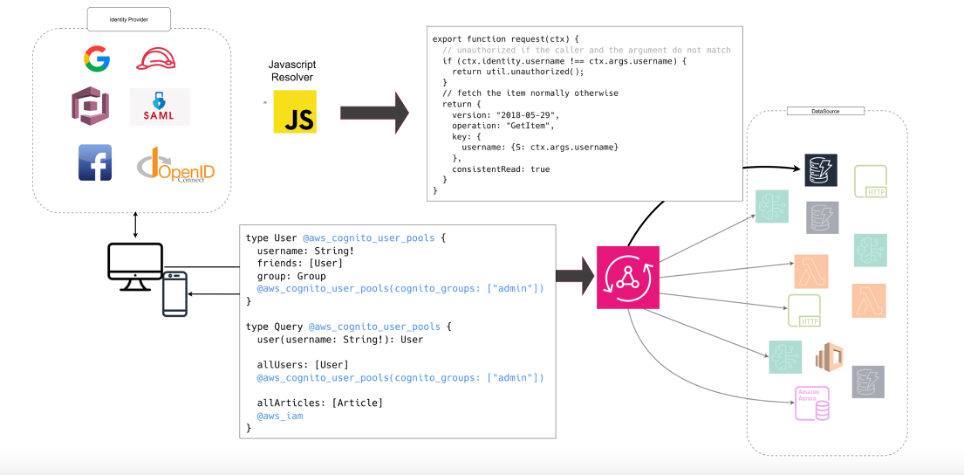
AppSync supports multiple authentication providers simultaneously — and that’s one of its key strengths.
You can allow:
- a mobile app to authenticate with Amazon Cognito User Pools,
- an internal microservice to communicate via IAM,
- and an external partner to access the API using OIDC or API keys — all through the same GraphQL endpoint.
Each authentication type can be associated with different operations in the schema.
Example:
- A user authenticated via Cognito can run queries and mutations on their own profile (
@aws_cognito_user_pools) - An internal service authenticated via IAM can invoke system-level mutations (
@aws_iam) - An external partner can access only a public subset of data (
@aws_api_key)
This flexibility makes it possible to model complex scenarios without multiplying endpoints or maintaining separate gateways.
Technical note:
Authorization directives (@aws_cognito_user_pools, @aws_iam, @aws_oidc, @aws_api_key) are interpreted by AppSync during query resolution, before any resolver is invoked.
This means that access control happens at the schema level, not as a post-processing step.
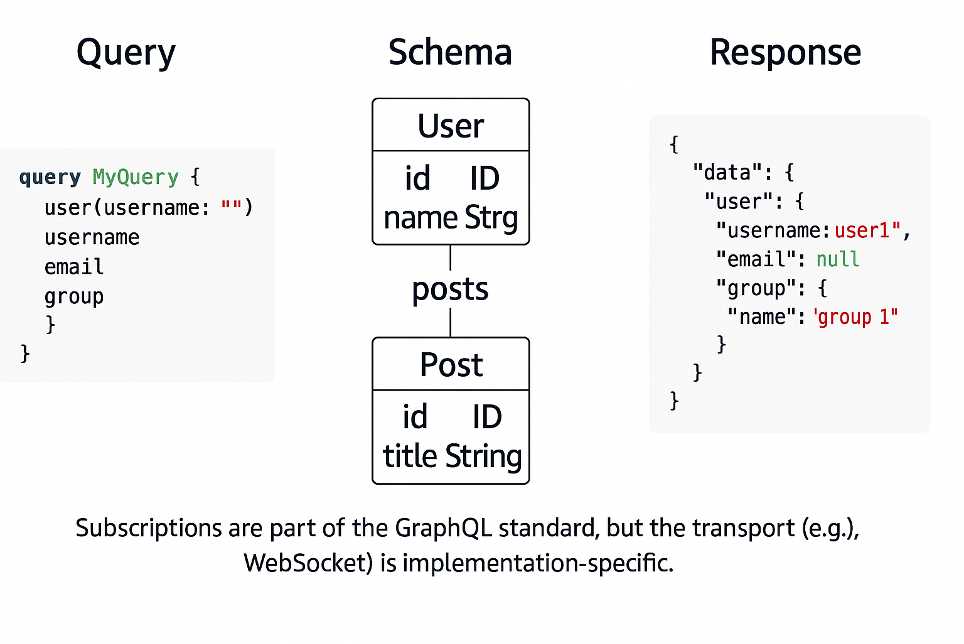
type User @aws_cognito_user_pools {
username: String!
friends: [User]
group: Group
@aws_cognito_user_pools(cognito_groups: ["admin"])
}
type Query @aws_cognito_user_pools {
user(username: String!): User
allUsers: [User]
@aws_cognito_user_pools(cognito_groups: ["admin"])
allArticles: [Article]
@aws_iam
}
Roles, groups, and multi-tenant
AppSync integrates natively with Amazon Cognito, allowing you to leverage groups, roles, and custom attributes to implement multi-tenant or role-based access control (RBAC) logic.
For example, you can add a tenantId or role attribute to the user’s token and use it within resolvers to automatically filter relevant data.
This approach is especially effective for multi-tenant SaaS applications:
each user only sees their own data, without the need to maintain separate databases or custom filtering logic in Lambda.
Security as part of the contract
The beauty of the GraphQL model in AppSync is that security is no longer a collection of scattered rules across gateways, middleware, and functions — it’s declarative.
It lives in the schema, right next to the types and operations it protects.
This reduces errors, makes policies readable, and keeps client and server behavior aligned.
In other words, the schema doesn’t just define what can be requested — it also defines who can request it.
Putting it all together
Subscription: managed real-time, zero code
Another classic complexity of self-hosted GraphQL is real-time management.
Subscriptions are part of the GraphQL standard, but the specification doesn’t define how they should be transported or maintained — WebSocket, Server-Sent Events, polling — each implementation has to come up with its own solution.
AppSync, on the other hand, does it for you.
It provides a fully managed WebSocket infrastructure that automatically handles connections, filters, and event distribution based on the rules defined in your schema.
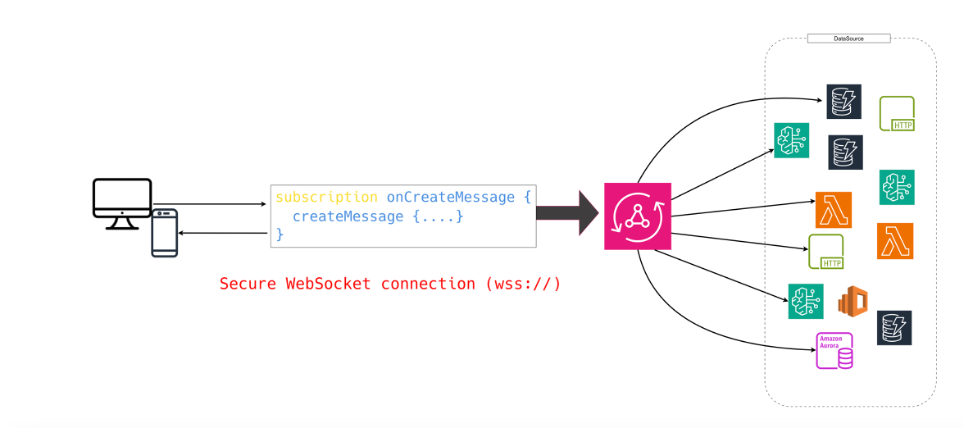
The mechanism is simple but powerful:
- You define a subscription linked to one or more mutations (e.g.
onNewPosttriggered bycreatePost) - The client subscribes through the same GraphQL endpoint
- AppSync keeps the connection alive and delivers only relevant events — securely and efficiently filtered
A unique trust layer
By combining security, authentication, and real-time, AppSync becomes more than a GraphQL engine — it’s a centralized trust plane.
Every query is authenticated, every field can be protected, and every event is delivered only to the users who are authorized to receive it.
And all this happens before your application code runs.
It’s a model where security isn’t an add-on, but a structural feature.
An architecture that lets you focus on business logic, knowing that identity, access, and real-time communication are already built into the platform.
Reliability, caching, and scalability: GraphQL that stays strong under load
Every growing architecture eventually faces the same challenge: performance.
More users, more queries, more data — and suddenly what worked fine in testing starts to become slow, expensive, or fragile.
With traditional GraphQL implementations, these problems often lead to overloaded servers, complex caching logic, or bottlenecks on data sources.
AppSync was designed to avoid all that.
As a fully managed service, it inherits the scalability, reliability, and optimizations of the AWS infrastructure — and extends them with features that make GraphQL natively performant.
Caching: speed by design, not data duplication
One of AppSync’s smartest features is per-resolver caching.
Instead of maintaining a global cache for entire queries (which can quickly become invalid), AppSync lets you define caches per field or operation.
This granular approach brings two major advantages:
- More control: you decide exactly what to cache and for how long.
- Higher hit ratio: frequently requested data — such as static lists, lookups, or shared results — is served directly from the cache, reducing data source calls by up to 90–99%.
Each cache node is fully managed (built on technology similar to Redis) and can be configured in just a few clicks or via CloudFormation.
Caching can also be automatically invalidated in response to mutations, keeping data consistent without extra code.
Example:
In an e-commerce app, resolvers that fetch categories, product metadata, or currencies are ideal candidates for per-resolver caching — reducing load on DynamoDB or external APIs without sacrificing freshness.
Batch invoke and fan-out reduction
Another key performance feature is how AppSync handles multiple resolver calls.
In complex graphs, a single query may require hundreds of small resolvers — each invoking a Lambda function or DynamoDB table.
To prevent “resolver explosion,” AppSync supports batch invoke, a mechanism that groups multiple resolutions into a single call.
This reduces round-trips, processing time, and Lambda invocation costs.
It’s a form of operational intelligence that works behind the scenes, keeping performance consistent even as queries grow in complexity.
Automatic scalability: no provisioning required
With AppSync, there are no servers to size or manage. The service automatically scales to handle thousands of queries per second — no configuration needed.
Underlying resources (such as DynamoDB, Lambda, or HTTP endpoints) follow the same elastic scaling model typical of AWS.
For high-traffic applications, you can request throughput quota increases via Service Quotas or AWS Support.
This allows you to keep the same architecture even during massive traffic spikes — like a product launch or global event.
In practice, AppSync scales vertically and horizontally with zero downtime.
As connections or concurrent queries increase, the platform automatically allocates the necessary resources while keeping latency under control.
Built-in reliability and resilience
Everything in AppSync is designed to be fault-tolerant.
Every component — from caching and resolvers to WebSocket connections — is replicated and managed across multiple Availability Zones.
In case of a failure, traffic is automatically rerouted with no impact on the API or user experience.
The service is stateless, meaning it doesn’t maintain application state between requests — each invocation is independent, reducing the risk of cascading failures common in self-hosted GraphQL servers.
Why this model is more efficient than self-hosted GraphQL
In a traditional setup, maintaining a high-performance GraphQL server requires you to:
- Manually scale instances
- Build and manage custom caching layers
- Handle connection pooling and load balancing
- Write code to mitigate latency between data sources
AppSync handles all of this natively and transparently.
It’s not a proxy — it’s a distributed orchestration engine that manages data flow between clients and sources with integrated caching, smart batching, and automatic scalability.
The result is a backend that remains lean and predictable even under heavy load — without compromising on security or reliability
Observability and troubleshooting: seeing inside the graph
As systems grow smarter, visibility becomes essential.
In GraphQL, this is especially true: a single query can trigger dozens of internal calls, pipeline steps, Lambda functions, and database operations.
When something slows down or breaks, it’s not enough to know that “the query failed” — you need to know where, why, and how much it impacted.
AppSync provides enterprise-grade observability tools that let you trace every request from entry to final response — with no agents, log servers, or custom tracing required.
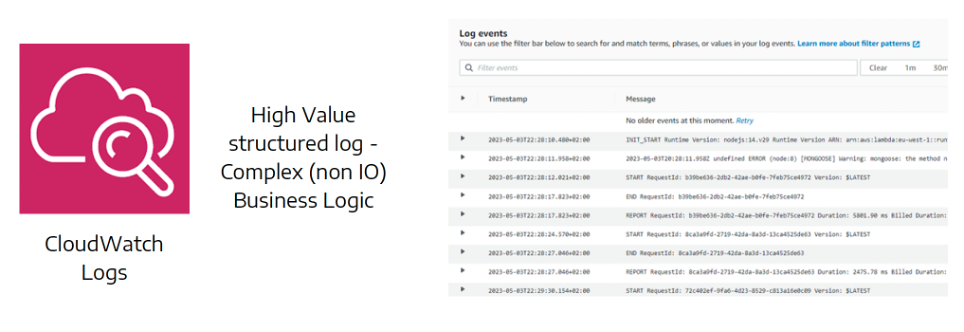
Detailed logging: CloudWatch as your window into the graph
The first tool to know is AWS CloudWatch, which collects all of AppSync’s operational logs.
You can configure the level of detail as needed:
- Error – logs only failed calls
- All – includes successful queries, response times, and context
- Verbose – captures request/response content, mapping templates (VTL/JS), and resolver context
Enabling verbose mode is like switching on the lights in a lab:
you can see exactly which fields are requested, which resolvers are invoked, and how data transforms along the pipeline.
It’s the perfect tool to understand where a query is consuming time — or where a template might be returning incorrect values.
Pro tip: use verbose mode wisely — it’s invaluable during testing and debugging, but it can generate large volumes of logs (and therefore higher costs) in production environments.
Distributed tracing with AWS X-Ray
When you want to go beyond simple logging and visualize the entire execution flow of a query, AWS X-Ray comes into play.
AppSync can be configured with xrayEnabled: true, and automatically each GraphQL request generates a trace showing the chain of calls between AppSync, data sources (DynamoDB, Lambda, HTTP), and any secondary functions.
The result is an interactive service map:
each node represents a service, each edge a call, and each color indicates latency or error metrics.
You can pinpoint in seconds where a query spends the most time, which resolvers are the most expensive, or where internal errors occur.
And if your resolvers invoke Lambda functions, you can extend tracing there as well by using the X-Ray SDK inside the function.
This gives you an end-to-end view of the entire flow — from the GraphQL client all the way down to the individual database or microservice.
Practical tip: for complex Lambdas or architectures with many microservices, consider integrating tools like Lumigo, Datadog, or New Relic.
They offer more intuitive interfaces for tracing and alerting than X-Ray, while remaining fully compatible with the data collected from AppSync.
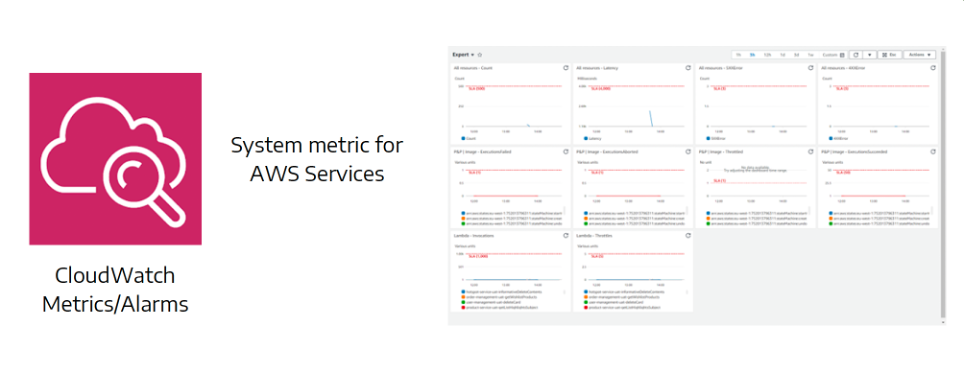
Metrics and alarms
In addition to logs and traces, AppSync exports a range of quantitative metrics to CloudWatch, such as:
- Number of GraphQL requests per second
- Average response time
- Authorization errors
- Number of active subscriptions
- Cache hit/miss ratio
You can build custom dashboards or configure automatic alarms (CloudWatch Alarms) to be notified if latency increases or if the cache stops working properly.
This allows you to react before problems become visible to users.
Targeted debugging: from resolver to field
A unique advantage of the GraphQL model in AppSync is field-level traceability.
Each resolver, being associated with a specific field, produces its own logs and metrics.
This means you can analyze the performance of a single field — for example, user.posts.comments — and pinpoint exactly where the issue lies, without having to sift through the entire API.
It’s a level of visibility that’s hard to achieve in traditional REST architectures, where problems often get lost among endpoints and microservices.
How to build an effective observability cycle
A typical production setup includes:
- CloudWatch Logs – to collect and analyze events from each query
- X-Ray – for end-to-end tracing across services
- CloudWatch Metrics + Alarms – to monitor trends and operational thresholds
- (Optional) External tools – for alerting, cost analysis, or cross-team correlation
With these integrated tools, AppSync becomes a transparent and manageable system: you know what happens, when it happens, and why.
Observability as part of the design
In AppSync, observability isn’t an afterthought — it’s a built-in platform feature.
Every query, resolver, and subscription is natively observable, and the collected data is centralized without requiring dedicated infrastructure.
This frees up time and resources: less time setting up logging, more time improving user experience.
In a world where data flows through dozens of services and serverless components, being able to “see inside the graph” is what turns an architecture from powerful to reliable.
Testing and quality: how to verify a living graph
In GraphQL, testing doesn’t just mean checking that “the API responds,” but that the entire flow — from schema to resolvers to data sources — behaves consistently.
Each field is a small piece of logic, each mutation can trigger event chains, and subscriptions keep real-time connections alive.
It’s an ecosystem, not just an API.
Although AWS AppSync is fully managed, it doesn’t remove the need for testing — it simply shifts it upward, toward validating the behavior of the graph itself.
Let’s see how.
Unit testing: the most granular level
At the lowest level are tests for mapping templates (VTL or JavaScript resolvers).
These files transform the GraphQL request into a data source call and format the response to match the schema.
Writing unit tests for these templates makes sense for complex cases — for example, when a resolver performs custom transformations or filtering.
AWS Amplify provides tools such as amplify-velocity-template and amplify-appsync-simulator, which allow you to run templates locally with simulated input and output.
In practice, it’s like testing the translation between GraphQL and the backend — verifying that the mapping does exactly what you expect.
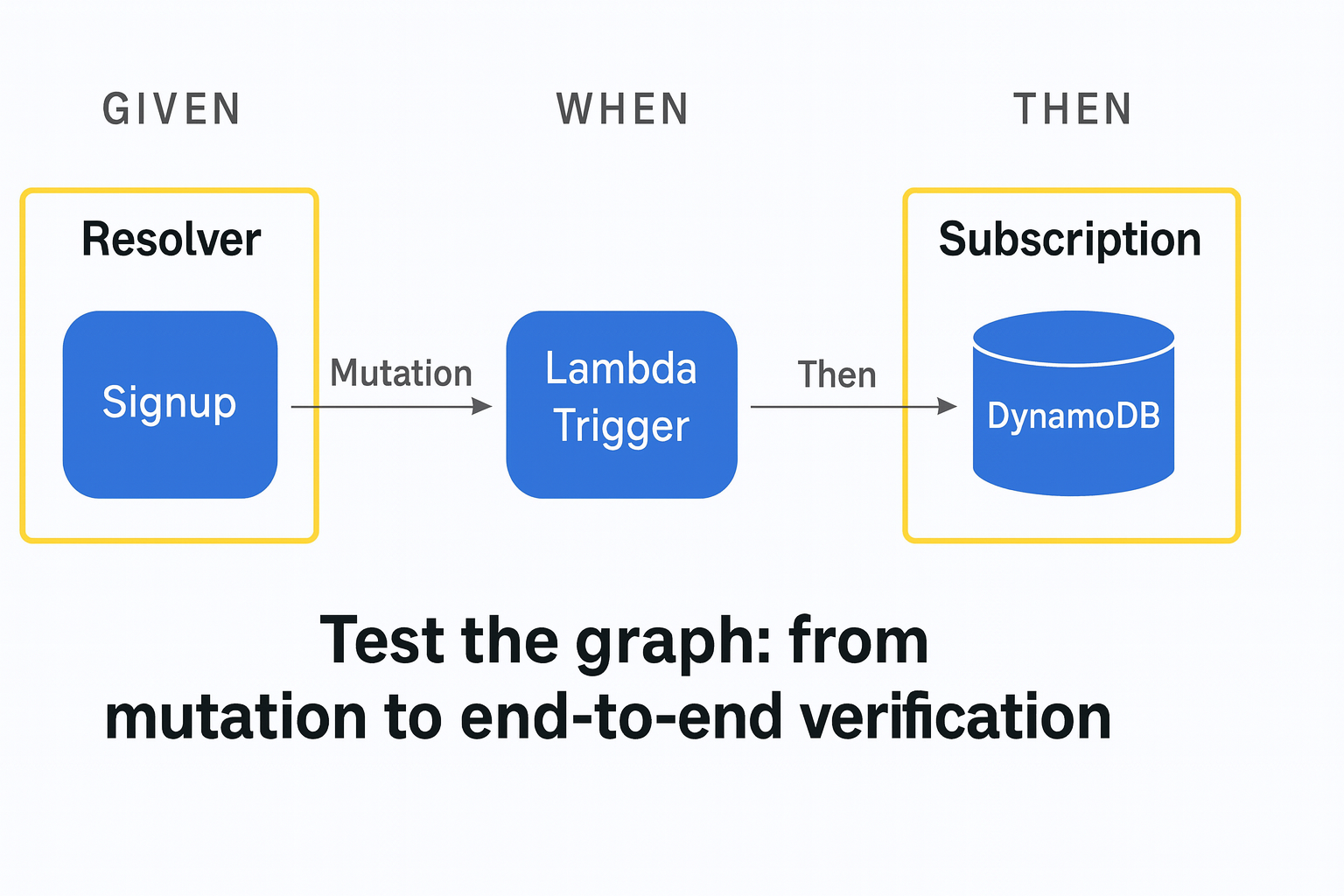
Integration testing: where the real value lies
The most valuable layer of testing in AppSync is integration testing — testing real resolvers against real data sources (DynamoDB, Lambda, HTTP).
No mocking here — you need to exercise the system for real.
Run a GraphQL query, pass real Cognito or IAM authentication tokens, and verify that the result matches the backend data state.
These tests catch:
- Authorization errors (missing or misconfigured IAM policies)
- Data shape mismatches between resolvers
- Incorrectly configured dependencies
This is where 90% of real issues appear — the ones that never surface in local development.
Concrete example:
A test that creates a user with the CreateUser mutation, waits for the Cognito PostConfirmation Lambda trigger, then verifies that the record was written to DynamoDB and that the getUser query returns it correctly.
That’s a true end-to-end test of an AppSync workflow.
End-to-End (E2E): testing the graph from the client’s perspective
The next step is end-to-end testing, which replicates the client experience:
authentication, queries, mutations, subscriptions, and responses.
You can use tools like Postman, GraphQL Playground, or testing frameworks such as Cypress, Playwright, or Jest (via a GraphQL client).
Each test starts with real Cognito authentication, sends requests to the AppSync endpoint, and validates the expected response.
This is the most direct way to ensure that the entire chain — security, schema, resolution, and data sources — works as intended.
And when testing real-time subscriptions, you can also verify event delivery over managed WebSockets, ensuring that only authorized users receive updates.
Mocks and local simulation: a safe playground
AppSync also supports local simulation modes through AWS Amplify.
You can launch a “mini” AppSync server to test queries, resolvers, and pipelines without deploying to AWS.
This is useful during early development stages or to validate schema and template changes before promoting them to shared environments.
A frequently overlooked advantage: this approach reduces testing costs and accelerates feedback cycles, especially for agile teams.
Testing as a continuous discipline
In a serverless environment like AppSync, testing isn’t a phase — it’s a continuous discipline.
Every change to the schema, resolvers, or data sources can alter the graph’s behavior.
That’s why it’s good practice to automate validation through CI/CD pipelines:
- Deploy to a temporary testing environment
- Run GraphQL test suites
- Automatically verify performance and security
- Only then, promote to production
It’s a way to treat the schema as living code — evolving, traceable, and tested.
The result: a reliable graph over time
A well-tested GraphQL API isn’t just “working” — it’s predictable.
Each field does what it promises, every mutation maintains consistency, and every subscription respects defined filters and roles.
In the context of AppSync, this means APIs that are stable, secure, and maintainable at scale.
And when something changes — a new field, a modified logic, or an updated resolver — tests become your safety net, allowing you to evolve without fear.
Conclusion: GraphQL and AppSync — the balance between control and freedom
Every technological revolution begins with a simple question:
What if there were a more natural way to talk to our data?
REST answered that question twenty years ago, bringing order where there was chaos.
But today, in a world of complex apps, interactive experiences, and distributed systems, the language of data needed to evolve again.
GraphQL is that new language — more expressive, more consistent, and closer to how we actually think about information.
And AWS AppSync is its perfect translator:
a service that takes the principles of GraphQL — schema, resolvers, security, real-time — and turns them into a fully managed, reliable, and infinitely scalable platform.
With AppSync:
- the schema becomes the single source of truth for your domain
- resolvers orchestrate data across heterogeneous sources
- security lives inside the graph, not at its edges
- real-time is built-in, not bolted on
- caching and scaling happen automatically
- observability lets you see everything that happens — field by field
It’s a different way to think about APIs: not as a collection of endpoints, but as a living system that grows alongside your application.
From REST to GraphQL, one step at a time
Moving to GraphQL doesn’t mean throwing away what you already have.
It means starting to shape your data around how the frontend truly consumes it.
You can begin gradually:
- Place AppSync in front of your existing REST APIs using HTTP resolvers.
- Gradually move logic into pipeline resolvers to combine data from multiple sources.
- Add Cognito authentication and caching to optimize performance and security.
- Enable subscriptions where real-time communication brings real value.
Step by step, without forcing it.
Until you end up with a backend that’s cleaner, more observable, scalable, and truly aligned with client needs.
A rare balance
AppSync’s real strength isn’t just technical — it’s philosophical.
It strikes a balance between two often opposing worlds: control and freedom.
It gives you the freedom to model your graph and data however you want, while freeing you from managing infrastructure, connections, instances, and logs.
It’s the ideal compromise between power and simplicity.
Not a framework, not a “closed” product, but a new way to design services — declarative, transparent, and naturally scalable.
The final mile
In the end, choosing GraphQL and AppSync isn’t just a choice of tools — it’s a shift in mindset.
It’s moving from a world of endpoints to a world of relationships.
From APIs that return data to systems that express knowledge.
From servers that respond to services that collaborate.
And when you see a well-written GraphQL query — clear, precise, almost readable as a thought — you realize it’s not just a technology:
it’s a new grammar for the language of data.
AppSync lets you speak that language without building everything from scratch — with the reliability and efficiency of a platform that’s already solved the hardest part: making everything else talk together.
Epilogue
In every line of GraphQL code lies the idea of a more coherent world, where client and server speak the same language.
And in every line of AppSync configuration lies the promise that this language can scale, live, and grow — without ever becoming a burden.