Beyond the Server: Anatomy of Serverless Thinking




Part 1 — The Age of Serverless
Introduction
Every technological revolution begins the moment a limitation becomes unbearable.
For decades, software development has been bound to an invisible axiom: to run code, you need a server. And that server — physical or virtual — has always been our cage.
We’ve configured it, maintained it, patched it, scaled it, monitored it. Every application innovation was mediated by an infrastructure that demanded to be tamed.
Then, something changed.
The cloud had already dissolved hardware ownership. But with serverless, the next step was bolder: dissolving management itself.
This is not just an infrastructural abstraction — it’s a profound cultural shift.
Serverless is the industry’s answer to the refusal of wasting cognitive capital maintaining what creates no direct value.
It’s not merely a technical choice; it’s a natural reaction to entropy.
“Build and run applications without thinking about servers.”
This definition — as essential as it is disarming — encapsulates the philosophy behind AWS Lambda and everything orbiting around it: infrastructure becomes transparent, and the focus shifts entirely toward business intent.
Organizations embracing this transition are not just seeking efficiency. They’re pursuing speed, elasticity, and operational peace of mind.
Serverless doesn’t promise to do more — it promises to do better with less: fewer fixed costs, less complexity, fewer human errors.
And in the modern software world, less is truly more.
The New Role of the Architect
In a serverless world, the architect is no longer the keeper of infrastructure — but the composer of behaviors.
Their job is not to decide how many nodes should handle the load, but when and why a function should exist.
Thinking serverless means designing in terms of events, reactions, and domain boundaries.
Each component becomes an autonomous cell — a Lambda that lives only as long as it takes to respond to an event, then disappears.
This way of reasoning enforces a radical shift: the architect no longer designs a monolith that breathes in unison, but an ecosystem that evolves independently.
Provisioning, autoscaling, availability — all are delegated to the cloud provider.
The architect’s task, then, is to model the flow of value, not the flow of resources.
In this vision, architecture is no longer a static diagram but an emergent behavior.
Here, architectural discipline approaches biology: a collection of functions that cooperate, compete, and regenerate.
A well-designed serverless system doesn’t simply live on infrastructure — it lives through it.
The Journey Toward a Fully Serverless Solution
Every organization that chooses to embrace serverless begins with a simple yet unsettling question:
“What if we stopped worrying about servers?”
The answer is never immediate, because serverless is not adopted — it’s internalized.
It requires a change in mindset, in pipelines, in ownership.
The team must learn to think in events, to let go of obsessive control, and to trust an invisible infrastructure.
The first step is almost always a pilot: an isolated microservice, a batch process, or an experimental feature.
From there, the curve becomes exponential.
Each new Lambda function becomes a tile in a larger ecosystem — a mosaic of compute-on-demand, orchestrated by API Gateway, powered by S3 and DynamoDB, exposed to the world through CloudFront.

The journey is not linear.
It’s an evolution made of compromises and discoveries.
Many teams move through a hybrid architecture — containers and Lambdas working together — before gradually reaching a fully serverless solution, where every layer is delegated to a managed service.
At the end of this journey, one realizes that the true achievement is not the absence of servers, but the absence of the fear of change.
Logical Architecture and the Lambda Dilemma
Serverless architecture is born from a constant tension between simplicity and granularity.
Every team soon faces a choice: should you build one monolithic Lambda per microservice, or split logic into Lambdas per feature?
In the first case — one Lambda per microservice — you gain compactness and startup speed.
Cold starts are minimal, management is straightforward, and deployment happens “all at once.”
It’s an approach reminiscent of the micro-monolith: a single unit, but easily scalable.
However, as the application grows, debugging becomes a nightmare.
Dependencies multiply, and every change requires a full redeployment.
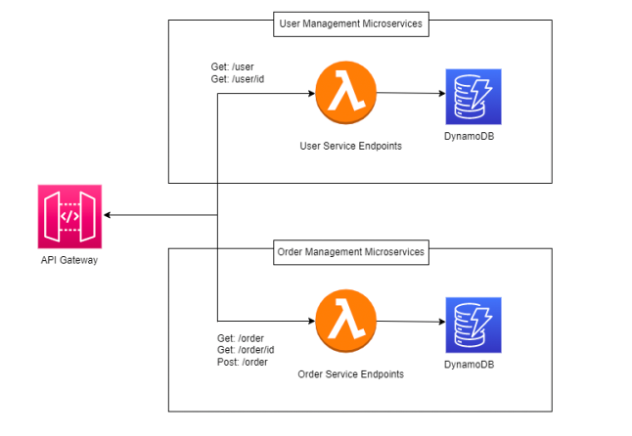
In the second scenario, a Lambda is adopted for each individual feature.
The microservice becomes a collection of autonomous functions working together.
Cold start times may increase, but deployment becomes surgical — deploy only what changes.
Complexity shifts toward orchestration, but in return you gain flexibility and release independence.
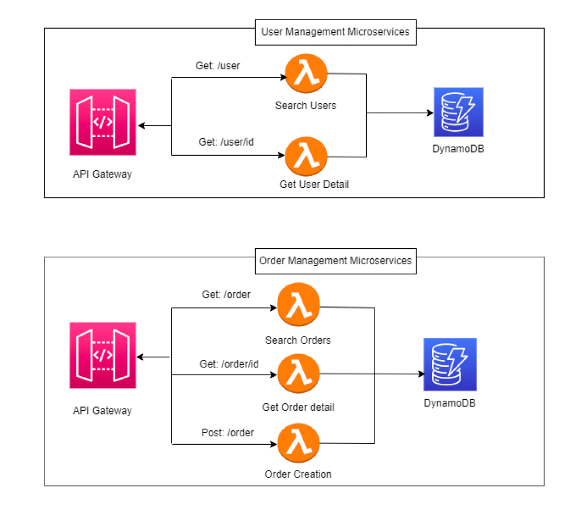
In reality, neither philosophy is “right” in an absolute sense.
The most mature architectures adopt a hybrid model, where the boundaries between functions are defined by the domain, not by the technology.
A core domain may deserve more granular Lambdas; a satellite domain, a more compact one.
The secret of serverless is this: there is no single best architecture — only the most appropriate one for a given moment.
The Database as a Domain
The true revolution of serverless lies not in the elimination of servers, but in the dissolution of monolithic databases.
In the traditional model, every service is tied to a single central datastore — a vast lake where everything converges, everything depends, and everything slows down.
In serverless, however, each microservice owns its own database, chosen according to its domain model.
This is the principle of Database per Service.
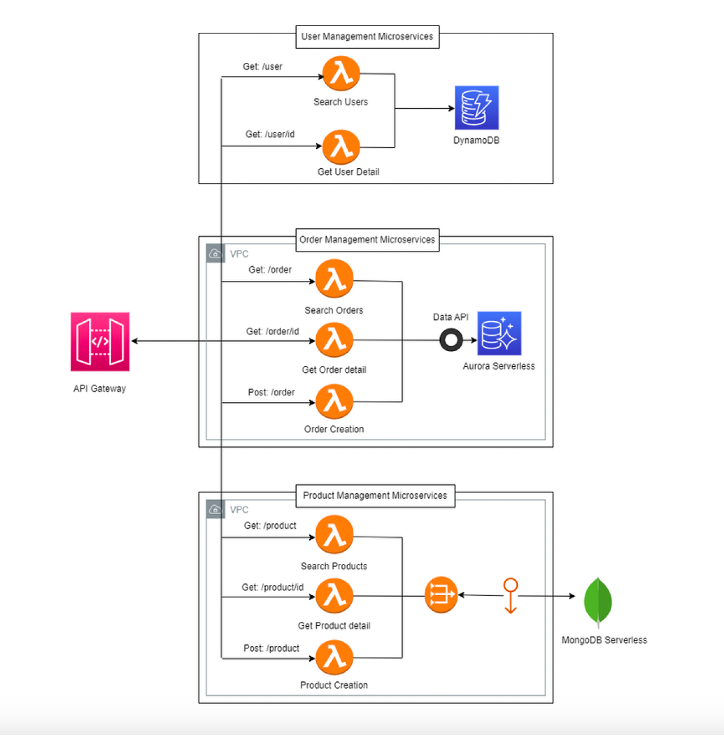
A service that manages user sessions can operate perfectly with DynamoDB, leveraging its linear scalability and per-request pricing.
Another, focused on data analytics, might rely on Aurora Serverless v2 for dynamic SQL queries.
Others may use S3 as an event store or static file repository.
The advantages of this approach are clear:
- Natural resilience: a database failure doesn’t block the system.
- Granular scaling: each domain scales according to its own traffic.
- Release autonomy: each team can evolve its schema without coordinating with others.
But the flip side is the loss of global transactional consistency.
Cross-domain operations require advanced patterns such as saga orchestration or eventual consistency.
Consistency is no longer immediate — it’s intentional.
This is one of the hardest lessons for teams migrating to serverless:
to accept that consistency is an emergent property, not an architectural axiom.
Part 2 — Anatomy of Serverless
Polyglot Engineering and Development Tools
Every technological revolution is also a liberation of language.
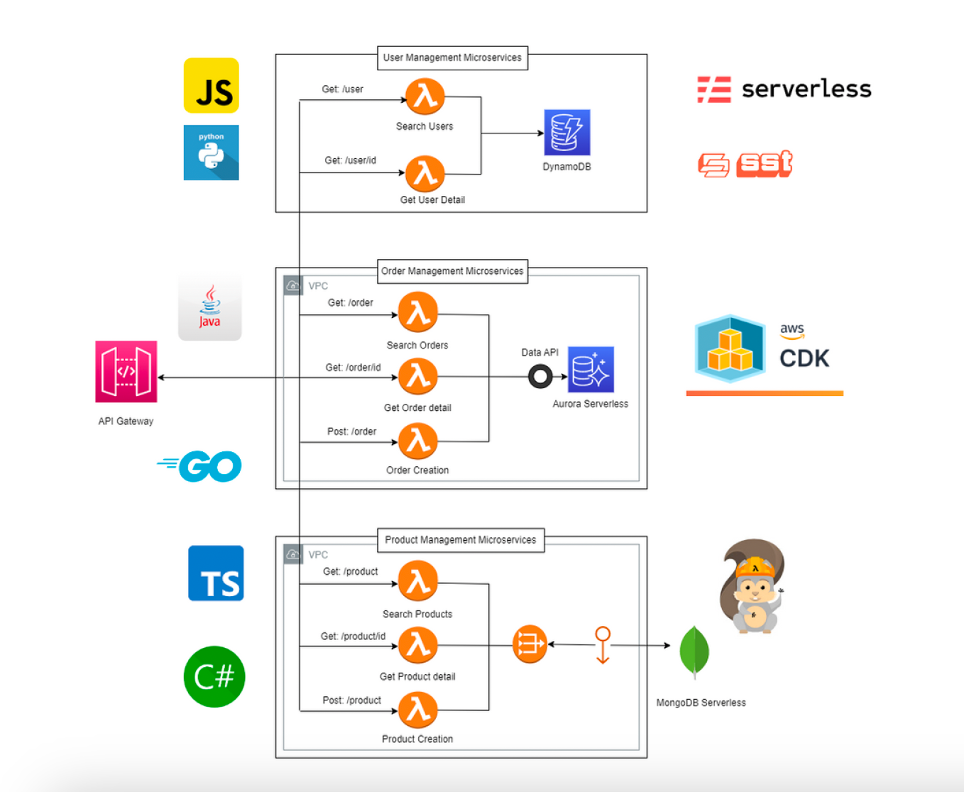
In the serverless world, the concept of a “stack” loses its meaning: every microservice, every Lambda, every function can be written in the language that best serves its purpose.
It is the triumph of polyglot engineering.
AWS doesn’t enforce a stack — it embraces it.
Lambda natively supports Python, Node.js, Go, Java, .NET, and Ruby, but most importantly, it allows custom runtimes.
This means technology is no longer an organizational constraint, but a contextual choice.
A data-driven team may use Python for development speed; an enterprise backend team may choose Java for ecosystem robustness; a high-performance service may prefer Go for its lightweight runtime.
The true serverless architect doesn’t choose a language for uniformity, but for fitness and cognitive cost.
On the development side, AWS has built a mature arsenal:
- AWS CDK (Cloud Development Kit) lets you define infrastructure as code using familiar languages (TypeScript, Python, Java). It’s the architectural DSL of serverless.
- AWS SAM (Serverless Application Model) provides a declarative framework to orchestrate Lambda, API Gateway, DynamoDB, and Step Functions natively.
- Serverless Framework and SST (Serverless Stack Toolkit) complete the vision, enabling CI/CD pipelines and multi-environment management.
These tools embody a fundamental principle:
infrastructure becomes a development artifact, not an administrative layer.
The result? More autonomous teams, faster release cycles, and a creative energy that had been lost in DevOps hierarchies.
The developer once again becomes an author, not a maintainer.
APIs as the System’s Language
Every serverless architecture is, ultimately, a network of conversations.
Microservices talking to each other, frontends querying backends, functions reacting to events.
The quality of this communication determines the quality of the entire ecosystem.
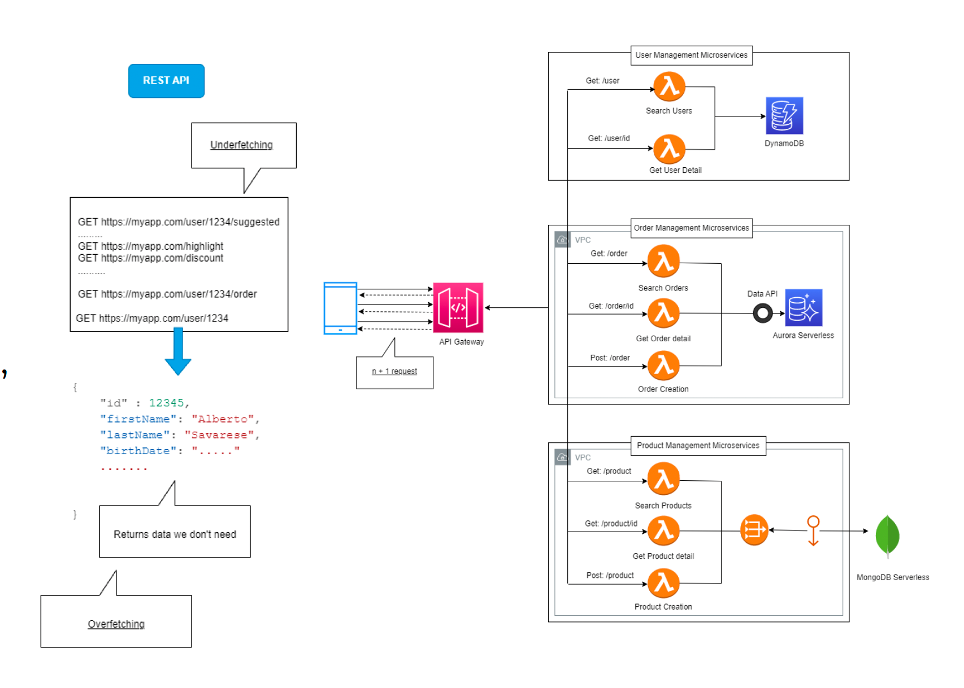
For years, the REST paradigm has dominated the scene.
But in a serverless environment — where scalability is atomic and costs are per invocation — REST begins to show its limits:
every endpoint is a round trip, every call a latency, every payload a cost.
The client often asks too much or too little.
In this scenario, GraphQL naturally emerges — and with it, AWS AppSync, which delivers a fully serverless implementation of the paradigm.
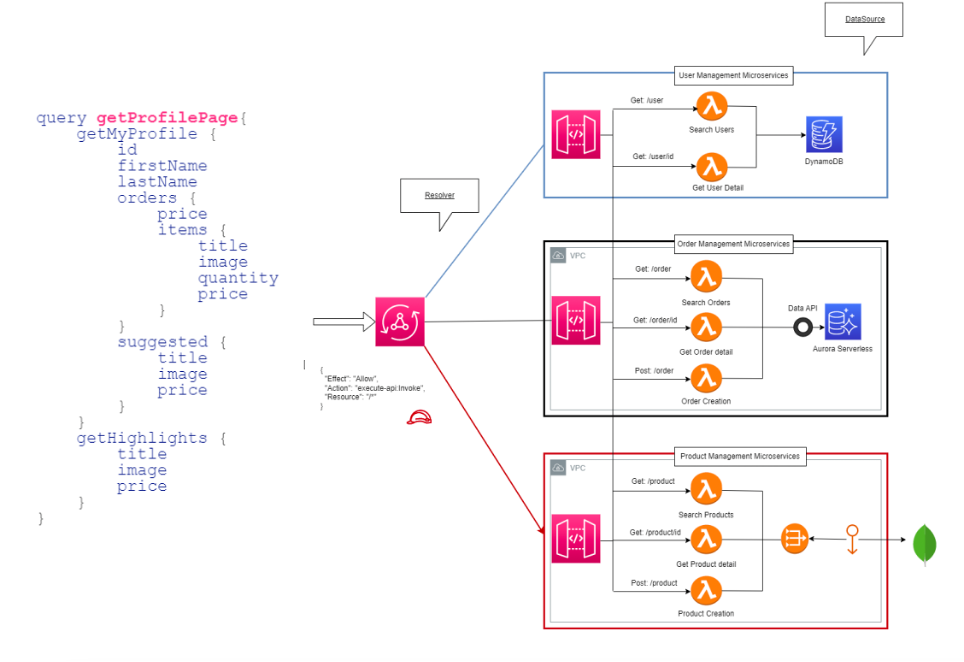
GraphQL flips the model:
The client doesn’t just consume resources — it navigates a graph of data.
Each node in the schema (type, query, mutation, subscription) is connected to a resolver, a connector to a data source (a Lambda function, a database, or a REST API).
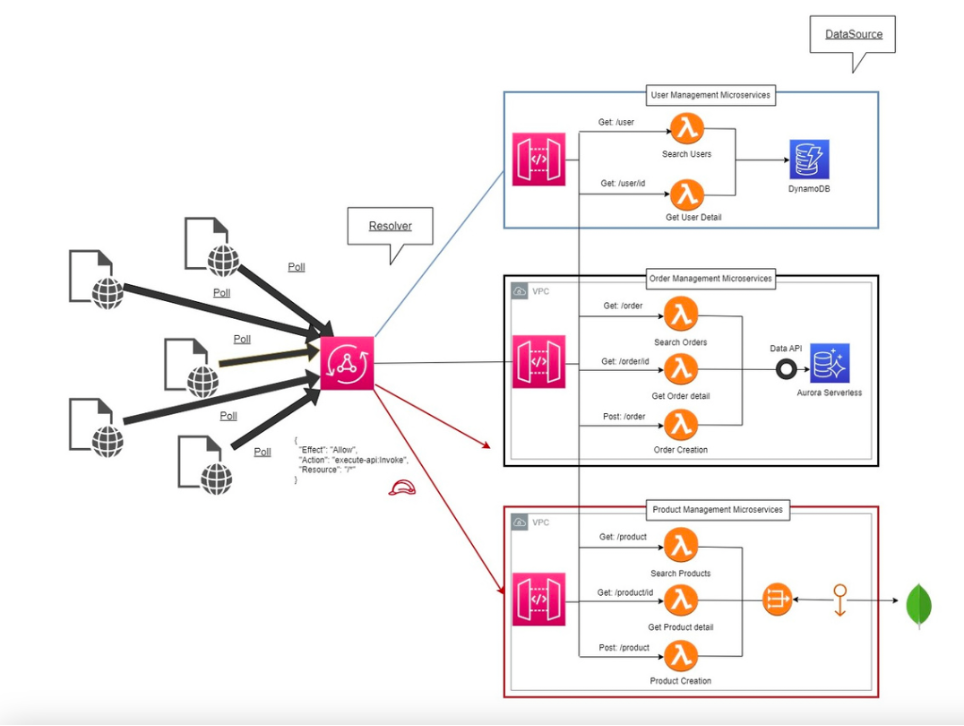
AppSync handles caching, security, and performance, eliminating the need for an intermediate layer.
The advantage is not only technical but philosophical:
GraphQL gives power back to the client, allowing it to define what data it wants and in what shape.
The network becomes semantic, not merely protocol-based.
And then there’s the subscription, the beating heart of the reactive model:
every time a mutation occurs, subscribed clients automatically receive an event.
No polling, no additional queues — just the natural propagation of information.
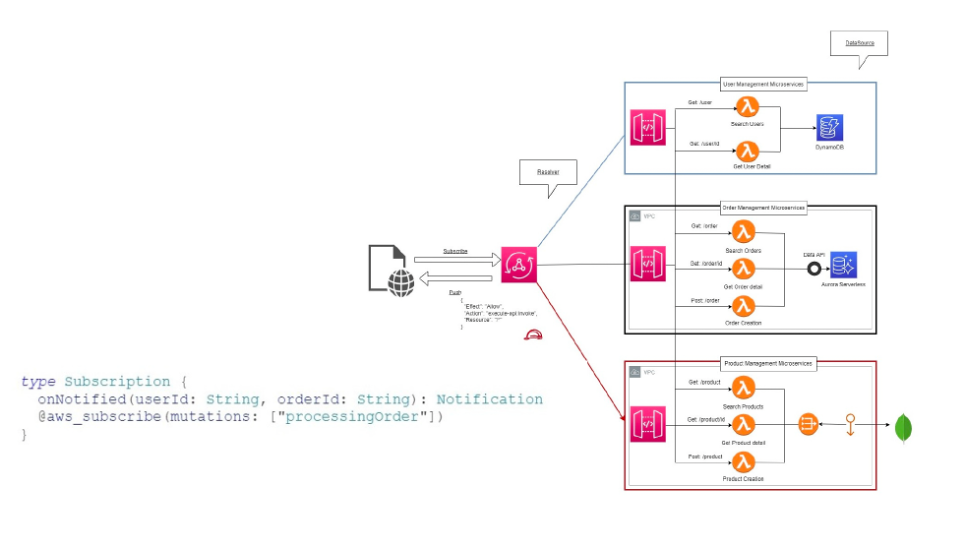
In an asynchronous world, GraphQL is not just a protocol — it’s a pact of trust between client and server.
Orchestration and Choreography: The Invisible Dance of Microservices
If serverless is a collection of autonomous functions, who decides when each one should act?
The answer is twofold, defining two schools of thought: orchestration and choreography.
In orchestration, a central service — often an AWS Step Function — governs the flow like a conductor leading an orchestra.
Every step is defined, tracked, and observable.
It’s perfect for complex processes such as payments, onboarding, or validation flows.
The advantage is predictability; the limitation is rigidity.
Choreography, on the other hand, is based on autonomy:
microservices exchange events through Amazon EventBridge, each reacting independently.
There is no central authority — only an ecosystem in balance.
The advantage is natural scalability; the limitation is global visibility.
A mature serverless system combines both models:
it uses orchestration for deterministic flows and choreography for evolutionary ones.
It’s an invisible dance, yet perfectly synchronized.
The serverless architect becomes a choreographer — not imposing sequences, but creating the conditions for sequences to emerge naturally.
From Backend to Pixel: Amplify and the Serverless Frontend
Serverless is not just a backend paradigm — it’s a philosophy that extends all the way to the frontend.
The question is: can a web application be entirely serverless?
With AWS, the answer is yes — thanks to Amplify, CloudFront, Lambda@Edge, and S3.
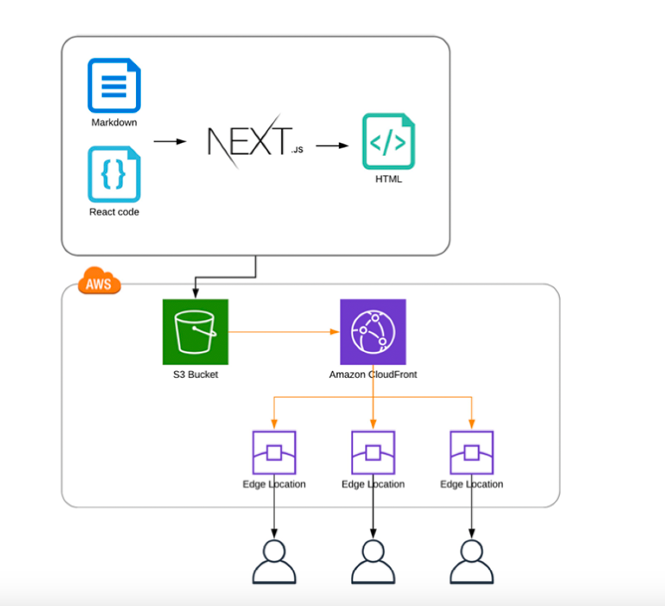
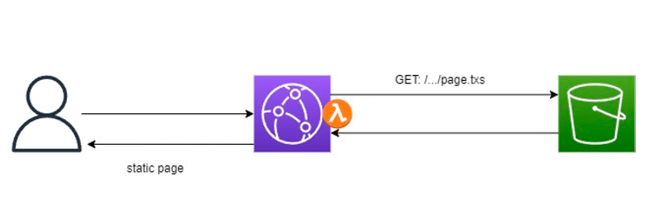
Let’s imagine the cycle:
the frontend code is built and uploaded to an S3 bucket;
CloudFront globally distributes the content, acting as a CDN;
Lambda@Edge steps in during viewer request/response phases to generate dynamic Server-Side Rendering (SSR).
This approach solves one of the Achilles’ heels of single-page applications: SEO.
Thanks to serverless SSR, search engines receive pre-rendered content, improving indexing without sacrificing performance or caching.
Amplify, in turn, automates the entire lifecycle:
versioning management, CI/CD, multiple environments, and atomic deployments.
It’s the practical embodiment of the principle: “no servers, no friction.”
The result is a global, scalable, and distributed frontend, where every pixel is served from the edge closest to the user.
The distance between code and customer literally shrinks to milliseconds.
Observability: Seeing the Invisible
Serverless, for all its elegance, hides a flaw: its invisibility.
When there are no instances to monitor and no centralized logs, understanding what’s happening becomes an art.
This is where the observability strategy comes into play.
AWS provides a complete toolkit:
- CloudWatch Logs for collecting each Lambda’s output,
- CloudWatch Metrics for tracking throughput, error rate, and latency,
- CloudWatch Alarms for automated responses to events,
- X-Ray for distributed tracing.
But for complex systems, solutions like Lumigo add an extra layer: they correlate invocations, visualize the flow between functions and services, and measure per-transaction costs.
In serverless, observability is not a luxury — it’s an ontological requirement.
Without it, a distributed architecture becomes a labyrinth.
With it, it becomes a self-diagnosing system, capable of telling its own story — where and why something breaks.
Observing a serverless system means learning to listen to its music of events — a symphony of invocations, queues, and streams that, once understood, reveals the true heartbeat of the application.
Part 3 — The Maturity and Vision of Serverless
The Cost Model: The Price of Invisibility
One of the most fascinating aspects of serverless is also the most treacherous: you pay only for what you use.
But behind this apparent simplicity lies a new kind of complexity — economic predictability.
In the traditional world, costs were stable but inefficient — VMs running 24/7, even during idle times.
In the serverless world, costs are dynamic — but potentially unpredictable:
every Lambda invocation, every DynamoDB query, every API Gateway call contributes to a mosaic of micro-transactions.
A mature team doesn’t suffer this complexity — it turns it into awareness.
It builds per-event cost models, not per-month ones.
It analyzes business flows and translates them into consumption metrics.
A concrete example: a food delivery application can estimate its average cost per order by summing up:
- Lambda invocations for orchestration and notifications,
- GraphQL calls on AppSync,
- event storage on S3,
- CloudWatch metrics generated throughout the flow.
AWS provides visibility through tools such as Cost Explorer, Budgets, and the Pricing Calculator — but it’s the architect who must turn them into a strategy.
The principle is simple: predict not how much you’ll spend, but why.
In a pay-per-use world, cost becomes a language — and like any language, it must be learned and spoken with intention.
Security and Identity: Trust as Architecture
In serverless, security is not configured — it’s designed.
Every Lambda, every API, every S3 bucket must be secure by definition, not by exception.
AWS Cognito becomes the heart of this model.
It handles authentication, federated identity (Google, Facebook, SAML, OpenID), and issues JWT tokens that can be verified directly by Lambdas or AppSync.
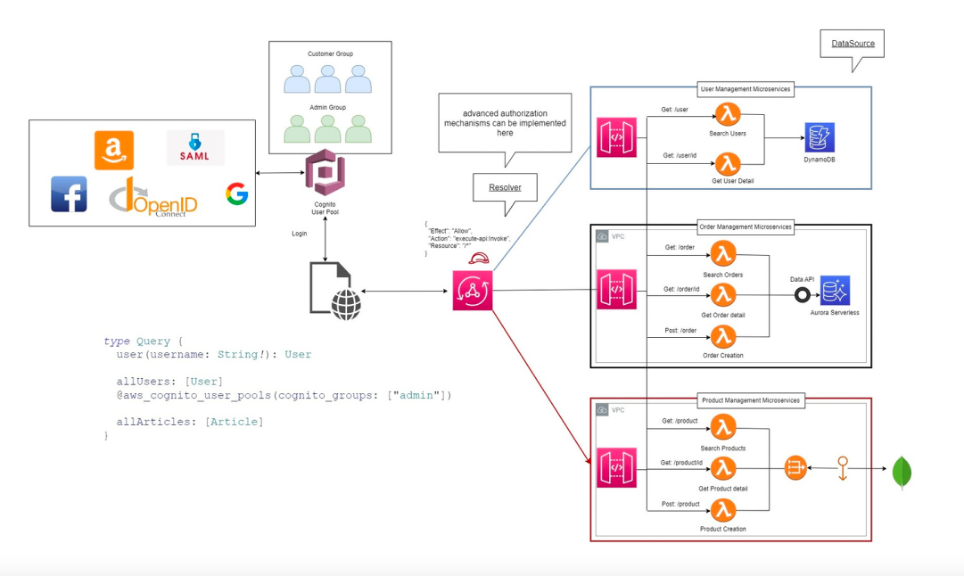
But serverless security doesn’t stop at login.
It lives in the granularity of IAM policies, in VPC Endpoints that restrict internal traffic, and in Lambda Layers that separate sensitive libraries from application code.
A more advanced approach includes creating custom directives in GraphQL to map authorization down to the field level.
In this way, a query requesting sensitive data can be denied without any additional code.
Serverless security is invisible, yet omnipresent.
It represents the highest form of trust — not the trust you grant a system, but the trust you build with it.
Resilience and Failure Management
A well-designed serverless system is not measured by how well it works, but by how it reacts when it stops working.
Resilience is not a feature — it’s a design behavior.
By its very nature, serverless tends toward resilience — each function is isolated, each service auto-scaling.
But reality is more complex.
A missing event, a parsing error, an unavailable dependency — all can generate silent failures.
That’s why resilient design is built on three pillars:
- Idempotency – every Lambda must be re-executable without side effects.
- Retry & DLQ (Dead Letter Queue) – every failed event deserves a second chance, routed to an SQS queue for reprocessing.
- Circuit breaker and fallback – recurring errors should open the circuit, isolate the issue, and notify upstream systems.
AWS Step Functions and EventBridge natively provide tools to build fault-tolerant flows.
But true resilience is born in the team’s mindset: treating failure as a first-class citizen, not as an anomaly.
In a mature serverless system, failure is no longer a surprise — it’s a form of feedback.
Culture and Organization: From DevOps to DevProduct
Every technological revolution carries a cultural side effect, and serverless is no exception.
By eliminating infrastructure, it radically changes the geometry of teams.
In the traditional model, development and operations were separate: devs built, ops maintained.
Serverless dissolves that barrier — there are no servers to maintain, so there is no “after production.”
The lifecycle becomes continuous and end-to-end.
Thus, a new figure emerges: the DevProduct.
A team is no longer responsible for a technical component, but for a business outcome.
Each team owns its functionality, costs, logs, and resilience.
This model — enabled by managed services and transparent metrics — fosters a culture of distributed ownership and measurable accountability.
The organizational impact is profound:
- less bureaucracy,
- more autonomy,
- less artificial coordination,
- more natural collaboration.
Serverless is not just a technological architecture — it’s a political act within team dynamics.
By shifting technical power to the edges, it creates an organization that is more organic, faster, more alive.
Trade-offs and Limits of the Serverless Model
Every paradigm casts its own shadow.
Serverless is not a universal answer — and a true architect knows this.
The first limitation is the cold start: the moment a dormant Lambda must wake up to handle a request.
AWS has largely mitigated this with provisioned concurrency, yet in low-latency systems, it remains a factor.
Then there’s vendor lock-in.
A solution deeply integrated with Lambda, AppSync, and DynamoDB is extraordinarily efficient on AWS — but difficult to replicate elsewhere.
It’s a trade-off between theoretical freedom and practical productivity.
Other limits emerge in long-running flows or high I/O pipelines, where per-invocation costs may exceed those of a containerized cluster.
And yet, architectural maturity doesn’t mean avoiding limits — it means designing with them consciously.
A serverless system is never entirely pure; it’s a pragmatic composition.
The goal is not to eliminate servers, but to eliminate server-centric thinking.
Beyond the Hype: The Quiet Maturity of Serverless
There was a time when serverless was everywhere — in conference titles, startup pitches, and modern cloud manifestos.
It was the promise of a definitive revolution: the dream of writing only business logic and letting the rest happen by itself.
Then, as with every technological cycle, enthusiasm faded.
Serverless stopped being the magic word on everyone’s lips.
Some, looking at trends or the silence on social media, assumed it was over.
The reality is the opposite.
Serverless hasn’t lost relevance — it has reached maturity.
Truly successful technologies don’t live on hype — they become part of the world’s infrastructure, so ordinary they seem invisible.
When something truly works, we stop calling it magic.
Today, serverless is exactly that: no longer the promise of a possible future, but the normality of the present.
There’s no need to announce it — it’s already everywhere:
in the asynchronous flows of an e-commerce platform,
in the backends of mobile apps,
in data analytics systems that scale infinitely without anyone having to think about it.
This is the true victory of the paradigm:
moving from exception to convention.
It’s no longer an experiment — it’s an operational pattern, an architectural grammar internalized by those who build modern software.
Serverless hasn’t lost its hype —
it simply no longer needs it.
It has entered its adult phase — where technology becomes so solid, predictable, and widespread that it no longer requires applause.
It has become what every technology dreams to be: transparent, indispensable, and taken for granted.
Conclusions — Big Thinking Mitigation
Serverless sits at the intersection of ambition and simplicity.
It promises to simplify — yet demands deeper thought.
By freeing engineers from infrastructure, it forces them to focus on what truly matters: the flow of value.
The concept of Big Thinking Mitigation, which ideally concludes this journey, represents this balance:
think big, but build small; imagine global ecosystems, but implement them as collections of local functions.
A fully serverless system is not a technological achievement — it’s a methodological declaration.
It tells the world that technology can become invisible, leaving room for intelligence, creativity, and value.
In an increasingly connected future, serverless won’t be the exception — it will be the new default.
And the true role of the architect will no longer be to build infrastructure,
but to create systems that build themselves.